第9讲、深入理解Scaled Dot-Product Attention
Scaled Dot-Product Attention是Transformer架构的核心组件,也是现代深度学习中最重要的注意力机制之一。本文将从原理、实现和应用三个方面深入剖析这一机制。
1. 基本原理
Scaled Dot-Product Attention的本质是一种加权求和机制,通过计算查询(Query)与键(Key)的相似度来确定对值(Value)的关注程度。其数学表达式为:
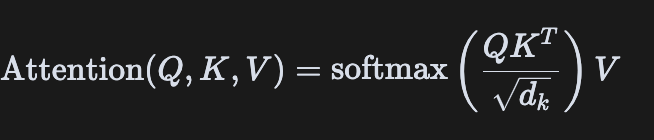
这个公式包含几个关键步骤:
- 计算相似度:通过点积(dot product)计算Query和Key的相似度,得到注意力分数(attention scores)
- 缩放(Scaling):将点积结果除以$\sqrt{d_k}$进行缩放,其中$d_k$是Key的维度
- 应用Mask(可选):在某些情况下(如自回归生成)需要遮盖未来信息
- Softmax归一化:将注意力分数通过softmax转换为概率分布
- 加权求和:用这些概率对Value进行加权求和
2. 为什么需要缩放(Scaling)?
缩放是Scaled Dot-Product Attention区别于普通Dot-Product Attention的关键。当输入的维度$d_k$较大时,点积的方差也会变大,导致softmax函数梯度变得极小(梯度消失问题)。通过除以$\sqrt{d_k}$,可以将方差控制在合理范围内。
假设Query和Key的各个分量是均值为0、方差为1的独立随机变量,则它们点积的方差为$d_k$。通过除以$\sqrt{d_k}$,可以将方差归一化为1。
3. 代码实现解析
让我们看看PyTorch中Scaled Dot-Product Attention的典型实现:
def scaled_dot_product_attention(query, key, value, mask=None, dropout=None):
# 获取key的维度
d_k = query.size(-1)
# 计算注意力分数并缩放
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 应用mask(如果提供)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# 应用softmax得到注意力权重
attn = F.softmax(scores, dim=-1)
# 应用dropout(如果提供)
if dropout is not None:
attn = dropout(attn)
# 加权求和
return torch.matmul(attn, value), attn
这个函数接受query、key、value三个张量作为输入,可选的mask用于遮盖某些位置,dropout用于正则化。
4. 张量维度分析
假设输入的形状为:
- Query: [batch_size, seq_len_q, d_k]
- Key: [batch_size, seq_len_k, d_k]
- Value: [batch_size, seq_len_k, d_v]
计算过程中各步骤的维度变化:
- Key转置后: [batch_size, d_k, seq_len_k]
- Query与Key的点积: [batch_size, seq_len_q, seq_len_k]
- Softmax后的注意力权重: [batch_size, seq_len_q, seq_len_k]
- 最终输出: [batch_size, seq_len_q, d_v]
5. 在Multi-Head Attention中的应用
Scaled Dot-Product Attention是Multi-Head Attention的基础。在Multi-Head Attention中,我们将输入投影到多个子空间,在每个子空间独立计算注意力,然后将结果合并:
class MultiHeadAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super().__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) 投影并分割成多头
query, key, value = [
l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))
]
# 2) 应用注意力机制
x, self.attn = scaled_dot_product_attention(query, key, value, mask, self.dropout)
# 3) 合并多头结果
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
6. 实际应用场景
Scaled Dot-Product Attention在多种场景下表现出色:
- 自然语言处理:捕捉句子中词与词之间的依赖关系
- 计算机视觉:关注图像中的重要区域
- 推荐系统:建模用户与物品之间的交互
- 语音处理:捕捉音频信号中的时序依赖
7. 优势与局限性
优势:
- 计算效率高(可以通过矩阵乘法并行计算)
- 能够捕捉长距离依赖关系
- 模型可解释性强(可以可视化注意力权重)
局限性:
- 计算复杂度为O(n²),对于长序列计算开销大
- 没有考虑位置信息(需要额外的位置编码)
- 对于某些任务,可能需要结合CNN等结构以捕捉局部特征
8. 总结
Scaled Dot-Product Attention是现代深度学习中的关键创新,通过简单而优雅的设计实现了强大的表达能力。它不仅是Transformer架构的核心,也启发了众多后续工作,如Performer、Linformer等对注意力机制的改进。理解这一机制对于掌握现代深度学习模型至关重要。
通过缩放点积、应用softmax和加权求和这三个简单步骤,Scaled Dot-Product Attention成功地让模型"关注"输入中的重要部分,这也是它能在各种任务中取得卓越表现的关键所在。
9、Scaled Dot-Product Attention应用案例
敬请关注下一篇
第9讲、深入理解Scaled Dot-Product Attention的更多相关文章
- [UCSD白板题] Minimum Dot Product
Problem Introduction The dot product of two sequences \(a_1,a_2,\cdots,a_n\) and \(b_1,b_2,\cdots,b_ ...
- Dot Product
These are vectors: They can be multiplied using the "Dot Product" (also see Cross Product) ...
- FB面经Prepare: Dot Product
Conduct Dot Product of two large Vectors 1. two pointers 2. hashmap 3. 如果没有额外空间,如果一个很大,一个很小,适合scan小的 ...
- CUDA Samples: dot product(使用零拷贝内存)
以下CUDA sample是分别用C++和CUDA实现的点积运算code,CUDA包括普通实现和采用零拷贝内存实现两种,并对其中使用到的CUDA函数进行了解说,code参考了<GPU高性能编程C ...
- 向量点积(Dot Product),向量叉积(Cross Product)
参考的是<游戏和图形学的3D数学入门教程>,非常不错的书,推荐阅读,老外很喜欢把一个东西解释的很详细. 1.向量点积(Dot Product) 向量点积的结果有什么意义?事实上,向量的点积 ...
- 理解numpy dot函数
python代码 x = np.array([[1,3],[1,4]]) y = np.array([[2,2],[3,1]]) print np.dot(x,y) 结果 [[11 5] [14 6] ...
- 理解numpy.dot()
import numpy.matlib import numpy as np a = np.array([[1,2],[3,4]]) b = np.array([[11,12],[13,14]]) p ...
- CUDA Samples: Dot Product
以下CUDA sample是分别用C++和CUDA实现的两个非常大的向量实现点积操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下: common.hpp: #ifndef FBC_CUD ...
- 视觉slam十四讲个人理解(ch7视觉里程计1)
参考博文::https://blog.csdn.net/david_han008/article/details/53560736 https://blog.csdn.net/n66040927/ar ...
- [论文理解] CBAM: Convolutional Block Attention Module
CBAM: Convolutional Block Attention Module 简介 本文利用attention机制,使得针对网络有了更好的特征表示,这种结构通过支路学习到通道间关系的权重和像素 ...
随机推荐
- VMware16虚拟机安装激活教程
1.开始安装前需要准备好的软件 VMware-workstation-full-16--虚拟机软件(必要) 获取方式: 官方下载地址:https://www.vmware.com/cn/product ...
- $GOPATH/go.mod exists but should not
开启模块支持后,并不能与GOPATH共存,所以把项目从GOPATH中移出即可
- 云服务器下如何部署Flask项目详细操作步骤
参考网上各种方案,再结合之前学过的Django部署方案,最后确定Flask总体部署是基于:centos7+nginx+uwsgi+python3+Flask之上做的. 本地windows开发测试好了我 ...
- g2o优化库实现曲线拟合
g2o优化库实现曲线拟合 最近学习了一下g2o优化库的基本使用,尝试着自己写了一个曲线拟合的函数,也就是下面这个多项式函数: \[y = ax^3 + bx^2 + cx + d \] 我们以 \(a ...
- 举个栗子之gorpc - 消息的编码和解码
2022年的第一个rpc,比以往来的更早一些... 留杭过年...写点东西 初始化项目gorpc 借助go module我们可以轻易创建一个新的项目 mkdir gorpc go mod init g ...
- 洛谷P4198 楼房重建 题解
Part1.自己一开始是怎么想的 我一开始的想法是先考虑什么情况下是看不见的. 如果是 \(i < j\) 的话可以直接看 \(j\) 的斜率和 \(i\) 的斜率就是比较 \(\frac{h_ ...
- (原创)[开源][.Net Framework 4.5] SimpleMVVM(极简MVVM框架)更新 v1.1,增加NuGet包
一.前言 意料之外,也情理之中的,在主业是传统行业的本人,技术的选型还是落后于时代. 这不,因现实需要,得将大库中的 WPF MVVM 相关部分功能拆分出来独立使用,想着来都来了,就直接开源得了,顺便 ...
- Metasploit(MSF)渗透测试之永恒之蓝实验
实验环境 前提:对方的445端口必须开放,首先要保证是能够访问到目标机器的,那么我们先ping一下目标机器,看网络是否连通 如果无法ping的话,对方机器必须要关闭防火墙,或许有其他方法在对方开启防火 ...
- javaWeb基础之Tomcat
一.Tomcat:web服务器软件 1. 下载:http://tomcat.apache.org/ 2. 安装:解压压缩包即可. * 注意:安装目录建议不要有中文和空格 3. 卸载:删除目录就行了 4 ...
- 🎀Java-Exception与RuntimeException
简介 Exception Exception 类是所有非致命性异常的基类.这些异常通常是由于编程逻辑问题或外部因素(如文件不存在.网络连接失败等)导致的,可以通过适当的编程手段来恢复或处理.Excep ...