Kafka入门实战教程(4):重要的集群参数配置
1 如何规划Kafka
集群部署“兵马未动,粮草先行”,与其盲目上马一套Kafka环境然后事后费力调整,不如一开始就思考好实际场景下业务所需的集群环境。在考量部署方案时需要通盘考虑,不能仅从单个维度上进行评估,下面是几个重要的维度的考量和建议:
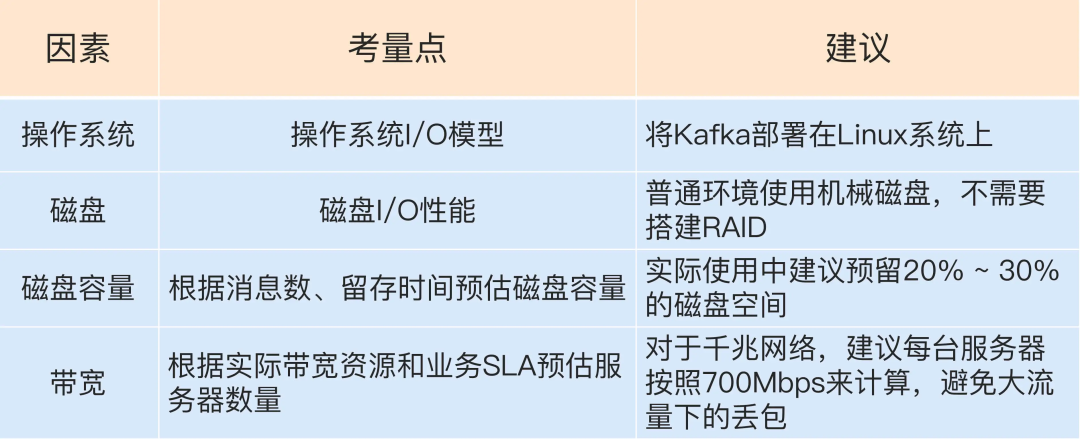
这里重点说说操作系统的因素。Linux系统比其他系统(特别是Windows系统)更加适合部署Kafka,主要体现在三个方面:
I/O模型的使用
数据网络传输效率
社区支持度
一句话总结:在Linux部署Kafka能够享受到零拷贝技术带来的快速数据传输特性。
2 一些重要的集群参数配置
我们从多个维度来看看分别有哪些重要的集群参数:
Broker端参数
(1)与存储信息相关的参数
log.dirs 必填,线上环境一定要配置多个路径,有条件最好挂载到不同的物理磁盘,可以提高读写性能和实现故障转移。
/home/kafka1,/home/kafka2,/home/kafka3
log.dir 非必填,建议不填。
(2)与ZooKeeper相关的参数
zookeeper.connect是与zookeeper相关的最重要的参数,没有之一。
zk1:2181,zk2:2181,zk3:2181
(3)与Broker连接相关的参数
listeners:监听器,告诉外部连接通过什么协议访问指定主机名和端口的Kafka服务。这里的协议名称可能是标准的名字,比如 PLAINTEXT 表示明文传输、SSL 表示使用 SSL 或 TLS 加密传输等。
PLAINTEXT://0.0.0.0:9091
advertised.listeners:这组监听器是Broker用于对外发布的。
PLAINTEXT://kafka1:9091
(4)关于Topic管理的参数
auto.create.topics.enable:是否允许自动创建topic,建议线上环境将其设置为false,即不允许自动创建Topic。
auto.leader.rebalance.enable:是否允许Kafka定期对一些Topic分区进行Leader重新选举,建议线上环境设置为false,因为换一次Leader成本很高。
(5)关于数据留存的参数
log.retention.{hours|minutes|ms}:这是个“三兄弟”,都是控制一条消息数据被保存多长时间。从优先级上来说 ms 设置最高、minutes 次之、hours 最低。
虽然 ms 设置有最高的优先级,但是通常情况下我们还是设置 hours 级别的多一些,比如log.retention.hours=168表示默认保存 7 天的数据,自动删除 7 天前的数据。
log.retention.bytes:这是指定 Broker 为消息保存的总磁盘容量大小。
这个值默认是 -1,表明你想在这台 Broker 上保存多少数据都可以,至少在容量方面 Broker 绝对为你开绿灯,不会做任何阻拦。这个参数真正发挥作用的场景其实是在云上构建多租户的 Kafka 集群:设想你要做一个云上的 Kafka 服务,每个租户只能使用 100GB 的磁盘空间,为了避免有个“恶意”租户使用过多的磁盘空间,设置这个参数就显得至关重要了。
message.max.bytes:控制 Broker 能够接收的最大消息大小。
这个值默认的 1000012 太少了,还不到 1MB。实际场景中突破 1MB 的消息都是屡见不鲜的,因此在线上环境中设置一个比较大的值还是比较保险的做法。毕竟它只是一个标尺而已,仅仅衡量 Broker 能够处理的最大消息大小,即使设置大一点也不会耗费什么磁盘空间的。
Topic级别参数
retention.ms:规定了该 Topic 消息被保存的时长。默认是 7 天,即该 Topic 只保存最近 7 天的消息。一旦设置了这个值,它会覆盖掉 Broker 端的全局参数值。
retention.bytes:规定了要为该 Topic 预留多大的磁盘空间。和全局参数作用相似,这个值通常在多租户的 Kafka 集群中会有用武之地。当前默认值是 -1,表示可以无限使用磁盘空间。
对于Topic级别的参数,建议统一使用kafka-configs来修改Topic级别的参数。例如,下面使用了kafka-configs命令将发送消息的最大值改为10MB。
bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name transaction --alter --add-config max.message.bytes=10485760
JVM级别参数
KAFKA_HEAP_OPTS:指定堆大小。
KAFKA_JVM_PERFORMANCE_OPTS:指定 GC 参数。
例如,我们可以这样启动 Kafka Broker,即在启动 Kafka Broker 之前,先设置上这两个环境变量:
$> export KAFKA_HEAP_OPTS=--Xms6g --Xmx6g
$> export KAFKA_JVM_PERFORMANCE_OPTS= -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true
$> bin/kafka-server-start.sh config/server.properties
操作系统级别参数
通常情况下,Kafka 并不需要设置太多的 OS 参数,下面列出几个最好关注一下的因素:
文件描述符限制
通常情况下将它设置成一个超大的值是合理的做法,比如ulimit -n 1000000。
文件系统类型
根据官网的测试报告,XFS 的性能要强于 ext4,所以生产环境有条件的话最好还是使用 XFS。
Swappiness
建议将 swappniess 配置成一个接近 0 但不为 0 的值,比如 1。
提交时间
这个定期就是由提交时间来确定的,默认是 5 秒。一般情况下我们会认为这个时间太频繁了,可以适当地增加提交间隔来降低物理磁盘的写操作。
3 总结
本文从Kafka集群众多的参数配置项选取了一些特别特别重要的参数配置做了介绍,相信了解这些参数配置之后,对于我们后续优化Kafka集群配置会大有裨益。
参考资料
极客时间,胡夕《Kafka核心技术与实战》
B站,尚硅谷《Kafka 3.x入门到精通教程》

Kafka入门实战教程(4):重要的集群参数配置的更多相关文章
- Kafka入门实战教程(7):Kafka Streams
1 关于流处理 流处理平台(Streaming Systems)是处理无限数据集(Unbounded Dataset)的数据处理引擎,而流处理是与批处理(Batch Processing)相对应的.所 ...
- Hadoop集群参数和常用端口
一.Hadoop集群参数配置 在hadoop集群中,需要配置的文件主要包括四个,分别是core-site.xml.hdfs-site.xml.mapred-site.xml和yarn-site.xml ...
- 转 Kafka入门经典教程
Kafka入门经典教程 http://www.aboutyun.com/thread-12882-1-1.html 问题导读 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic. ...
- [转载]HTML5开发入门经典教程和案例合集(含视频教程)
http://www.iteye.com/topic/1132555 HTML5作为下一代网页语言,对Web开发者而言,是一门必修课.本文档收集了多个HTML5经典技术文档(HTML5入门资料.经典) ...
- Spring-Session实现Session共享Redis集群方式配置教程
循序渐进,由易到难,这样才更有乐趣! 概述 本篇开始继续上一篇的内容基础上进行,本篇主要介绍Spring-Session实现配置使用Redis集群,会有两种配置方式,一种是Redis-Cluster, ...
- kafka系列二:多节点分布式集群搭建
上一篇分享了单节点伪分布式集群搭建方法,本篇来分享一下多节点分布式集群搭建方法.多节点分布式集群结构如下图所示: 为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建. 一.安装Jdk 具体安 ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- 原创:centos7.1下 ZooKeeper 集群安装配置+Python实战范例
centos7.1下 ZooKeeper 集群安装配置+Python实战范例 下载:http://apache.fayea.com/zookeeper/zookeeper-3.4.9/zookeepe ...
- CentOS6安装各种大数据软件 第五章:Kafka集群的配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
随机推荐
- 异常--java进阶day08
1.异常 java中,所有的异常都是类 2.异常的体系结构 3.编译时异常与运行时异常 1.编译时异常 语法完全正确,但是代码就是会报错,如下图 上图中,写的是时间格式化类的使用,parse方法将给的 ...
- golang实现命令行程序的使用帮助
通过flag包我们可以很方便的实现命令行程序的参数标志, 接下来我们来看看如何实现命令行程序的使用帮助, 通常以参数标志-h或--help的形式来使用. 自动生成使用帮助 我们只需要声明其他参数标志, ...
- @PathVaribale
/** * @pathVaribale * 作用: 用于获取url 中的占位符的值. * 例如:请求 url 中 /delete/{id},这个{id}就是 url 占位符. * url 支持占位符是 ...
- vue报错:Property or method "xxx" is not defined on the instance but referenced during render.
vue报错:Property or method "attendanceDetaill" is not defined on the instance but referenced ...
- 备份一个迭代查找TreeViewItem的辅助函数
private TreeViewItem FindTreeItem(TreeViewItem item, Func<TreeViewItem, bool> compare) { if (i ...
- Asp.net core 少走弯路系列教程(四)JavaScript 学习
前言 新人学习成本很高,网络上太多的名词和框架,全部学习会浪费大量的时间和精力. 新手缺乏学习内容的辨别能力,本系列文章为新手过滤掉不适合的学习内容(比如多线程等等),让新手少走弯路直通罗马. 作者认 ...
- Android frida hook (学习分享)
frida模块 参考: https://www.52pojie.cn/thread-1823118-1-1.html https://www.52pojie.cn/thread-1840174-1-1 ...
- 【HUST】网络攻防实践|TCP会话劫持+序列号攻击netcat对话
文章目录 一.前言 1. 实验环境 2. 攻击对象 3. 攻击目的 4. 最终效果 docker的使用 新建docker docker常用指令 二.正式开始 过程记录 1. ARP欺骗 2. 篡改数据 ...
- SOUI2-布局系统
布局系统 每个UI界面都是由大量的界面元素构成的,在window编程中,这些界面元素的最小单位被称为控件,而布局则是这些控件在界面的相对位置和大小. 目前SOUI支持锚点布局.线性布局.网格布局,下面 ...
- TVMC python:一种TVM的高级API
Step 0: Imports from tvm.driver import tvmc Step 1: Load a model 下载模型: wget https://github.com/onnx/ ...