我永远喜欢着OOP——第一次总结
我永远喜欢着OOP——第一次总结
一、三次作业总结分析
1. 第一次作业
1.1 作业分析
第一作业主要是给我们引入了一个对于非法输入处理的思想,包括第一次上机,都一直围绕着一个全新的主题,就是非法输入处理,而对于这次作业本身,其实难度并不是很大,甚至用纯C也不会有很大的工作量,但是引入了一个这样一个重要思想笔者觉得是学到很多的
1.2 程序架构
说起第一次作业,笔者其实是有为第二次作业做准备的(但是看起来准备的并不合格),在第一次作业中笔者还专门准备了一个虚基类来准备继承其他的项(因为怕操作失误删了),以方便在第二次作业如果加入其他的函数,就直接加上一个新的子类,然后上层逻辑用利用多态,根本不用改(事实证明是我想少了)。
直接上UML图吧(先让我去git clone 一下)
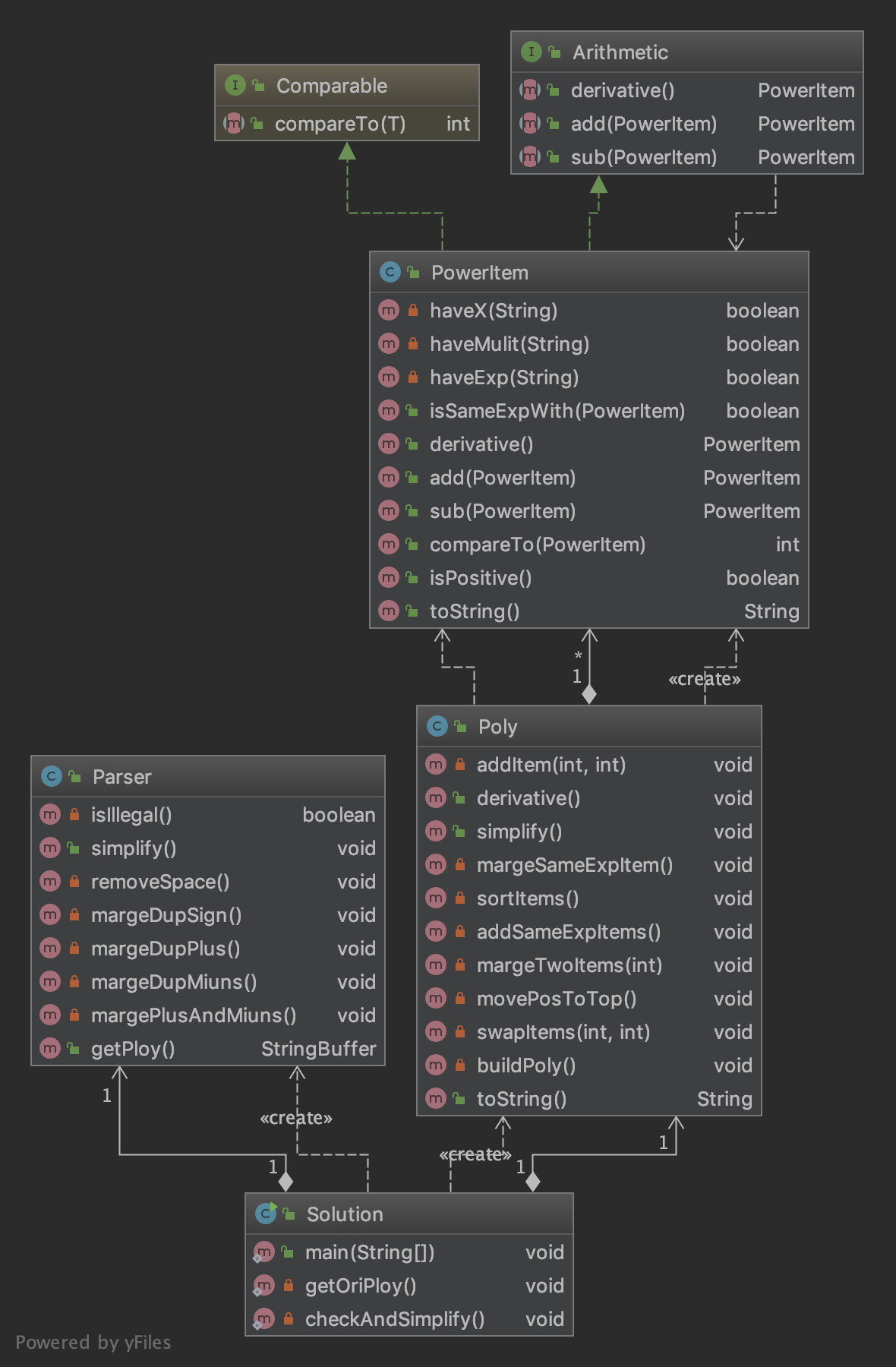
可以看到,看到每个类的方法很多,不过细看可以看出来很多其实这主要是方法模块化的结果。
首先是关于错误处理和输入规范化,笔者单独实现了一个Parser解析类来完成这个工作,利用正则分割和匹配每一项,在遇到非法输入即抛出异常,有顶层类捕获并输出WF
然后就是求导部分,因为只有加法,所以只需要表达式调用每个项的求导即可完成求导
最后是化简,也就是优化,在本章作业里,优化都是一个让我觉得很难受的地方,也不一定说每个优化有多么复杂的逻辑或是算法,但是更多的给我的感觉是,从整理到求导整个过程像是一个整体,而优化就像是没有关系的一件事情硬插在了里面。
不过现在静下心来思考,其实,优化不应该被放在任何一个因子、项、表达式类里面,其实,笔者觉得应该装饰者模式来处理也许会更好,每种优化作为一个装饰者,然后将项、表达式、因子传入,然后再得到化简后的结果,这样的组织首先不会导致化简逻辑和运算逻辑混为一谈,两件事情高度耦合,错误就很容易发生(笔者本人也是深受其害,以至于Bug修复的时候只需要注释掉simplify()函数就可以修复绝大多数同质Bug),所以还是回到了高内聚低耦合的话题上,这件事情应该是设计阶段要仔细思考的一件事。
所以也可以看到,我的项和表达式里面充斥着大量的和项与表达式运算无关的方法,他们也严重违反了单一职责原则
| Class | CBO | DIT | LCOM | NOC | RFC | WMC |
|---|---|---|---|---|---|---|
| Arithmetic | 3.0 | |||||
| Parser | 1.0 | 1.0 | 1.0 | 0.0 | 21.0 | 13.0 |
| Poly | 2.0 | 1.0 | 1.0 | 0.0 | 39.0 | 23.0 |
| PowerItem | 2.0 | 1.0 | 4.0 | 0.0 | 26.0 | 29.0 |
| Solution | 2.0 | 1.0 | 1.0 | 0.0 | 16.0 | 3.0 |
| Total | 68.0 | |||||
| Average | 1.75 | 1.0 | 1.75 | 0.0 | 21.0 | 17.0 |
从度量中也可以看到整体复杂度其实还是不高的
2. 第二次作业
2.1 作业分析
第二次相对于第一次,求导规则更加复杂,数据如何组织是一件比较麻烦的事情,由于当时笔者没有将常数作为单独一项来处理,所以导致在优化合并的时候,提取系数极其困难
2.2 程序架构
直接上类图,咱们看图说话
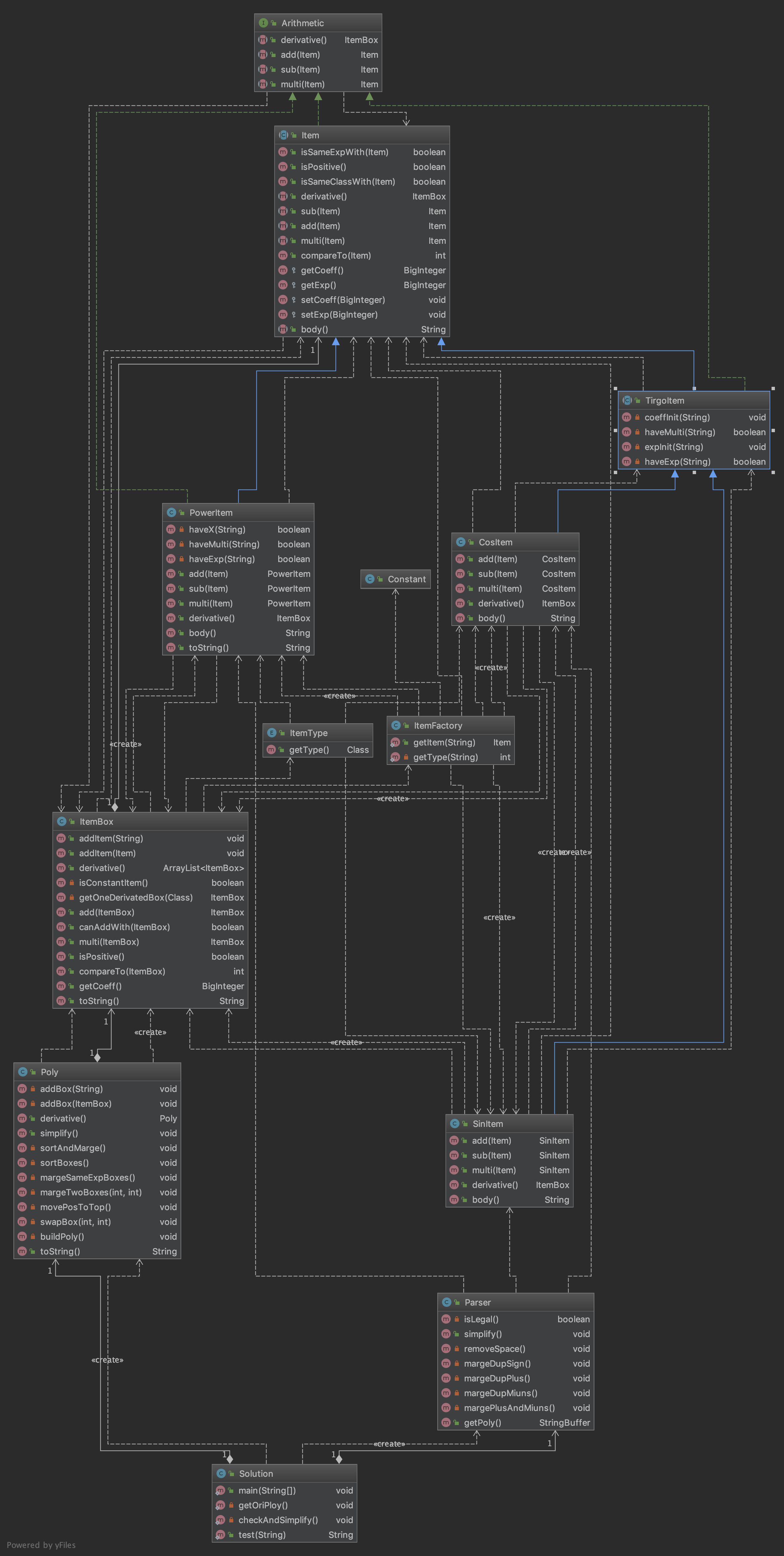
很庞大,但是其实就是因子继承虚基类,然后所有承在一起的因子构成一个所谓的Box,Box中用HashMap来维护三项,主体逻辑跟上一次完全相同,但是化简逻辑复杂了很多,从图中也可以看到有很多化简函数放在了里面,让人看不懂,这也是这三次作业的败笔所在,没有把化简功能分离出来,这样不仅不利于测试化简功能,而且程序的未知行为无法估测,这也是这样测试中出现Bug的一个十分重要的原因
下面给出程序的度量
| Class | CBO | DIT | LCOM | NOC | RFC | WMC |
|---|---|---|---|---|---|---|
| Constant | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ItemType | 4.0 | 1.0 | 2.0 | 2.0 | ||
| Solution | 4.0 | 0.0 | 1.0 | 0.0 | 11.0 | 4.0 |
| ItemFactory | 6.0 | 0.0 | 1.0 | 0.0 | 5.0 | 9.0 |
| TirgoItem | 4.0 | 1.0 | 2.0 | 2.0 | 11.0 | 10.0 |
| SinItem | 7.0 | 2.0 | 5.0 | 0.0 | 17.0 | 11.0 |
| CosItem | 7.0 | 2.0 | 5.0 | 0.0 | 17.0 | 11.0 |
| Item | 7.0 | 0.0 | 8.0 | 2.0 | 15.0 | 12.0 |
| Parser | 4.0 | 0.0 | 1.0 | 0.0 | 10.0 | 13.0 |
| Poly | 2.0 | 0.0 | 1.0 | 0.0 | 17.0 | 25.0 |
| PowerItem | 6.0 | 1.0 | 8.0 | 0.0 | 21.0 | 29.0 |
| ItemBox | 9.0 | 0.0 | 1.0 | 0.0 | 22.0 | 44.0 |
| Total | 170.0 | |||||
| Average | 5.083333333333333 | 0.5454545454545454 | 2.8333333333333335 | 0.36363636363636365 | 11.692307692307692 | 14.166666666666666 |
可以看到,由于Poly和ItemBox类中集合了过多本不该属于他们的方法,所以导致这两个类的复杂度很高,最终的Bug也是出现在这两个类的协作中
3. 第三次作业
3.1 作业分析
这次的作业看起来改动很大,其实仔细分析可以发现,只是新增了一个嵌套功能,也就是说,如果保证嵌套的内容没有问题,那么整个程序的逻辑和第二次作业基本是一致的,我也是按照这个思路来组织,并根据指导书给出的因子、项、表达式这样的分层结构来实现的设计
3.2 程序架构
基本就是按照指导书给出的三层结构来实现的设计,下面给出UML图

结构很清晰,容我再次痛斥一次我这种肮脏的优化设计,耦合度真的很高,无法测试,导致系统存在大量的不确定性,正确性无法保证的同时,还无法单独调试改错,实在丑陋
| Class | CBO | DIT | LCOM | NOC | RFC | WMC |
|---|---|---|---|---|---|---|
| ExceptionUtil | 1.0 | 1.0 | 1.0 | 0.0 | 5.0 | 1.0 |
| Main | 4.0 | 1.0 | 1.0 | 0.0 | 12.0 | 2.0 |
| PowerFactor | 5.0 | 2.0 | 2.0 | 0.0 | 18.0 | 9.0 |
| NumFactor | 7.0 | 2.0 | 2.0 | 0.0 | 17.0 | 9.0 |
| Factor | 7.0 | 1.0 | 4.0 | 5.0 | 20.0 | 12.0 |
| FactorFactory | 7.0 | 1.0 | 1.0 | 0.0 | 9.0 | 13.0 |
| ExprFactor | 5.0 | 2.0 | 4.0 | 0.0 | 22.0 | 15.0 |
| CosFactor | 6.0 | 2.0 | 1.0 | 0.0 | 36.0 | 19.0 |
| SinFactor | 6.0 | 2.0 | 1.0 | 0.0 | 35.0 | 19.0 |
| Term | 13.0 | 1.0 | 1.0 | 0.0 | 51.0 | 49.0 |
| Expr | 3.0 | 1.0 | 3.0 | 0.0 | 61.0 | 63.0 |
| Total | 211.0 | |||||
| Average | 5.818181818181818 | 1.4545454545454546 | 1.9090909090909092 | 0.45454545454545453 | 26.0 | 19.181818181818183 |
可以看出,底层的模块的复杂度还较为良好,而上层的模块,也就是项和表达式,由于过多的化简逻辑掺杂其中,导致这两个类的复杂度很高,是十分糟糕的情况
二、关于Bug
1. 我的Bug
笔者在第二次和第三次都出现了Bug,而且情况很类似,都是一个几行代码就能修复但是却很致命的Bug,我觉得原因有下面几点:
- 思路不够清晰,或者说由于模块耦合过度导致思路混乱
- 数据组织方式有问题,数据的组织形式往往是在设计时针对求导来设计的,而往往忽略了优化部分,然而又没有采用新的组织,导致最终出现问题或者化简困难
- 本身算法水平较差,算法效率不够
所以我觉得,在设计一个程序的时候,首先,应该保证良好的模块间解耦,从而能够让思维集中而不用去一直全局考虑,其次,就是要合理组织数据,如果要完成的两件事情有各自的较优数据组织方式,那么重新组织数据也不失为一种方法
2. 别人的Bug
关于如何发现别人的Bug,我从两个角度说吧
出于行业内的代码审查和代码走查方式:
这种方式强调看代码逻辑,也就是白盒测试,在看代码的同时不断提出疑问,然后从这些疑问中寻找可能存在的bug,黑盒测试在这里只起辅助验证作用。
然而,在现有的游戏模式下,首先,你要面对的是六七份代码,每份的代码量都在千行左右,而且有的代码的可读性又比较差,毕竟没有统一的设计规范,这种方法基本不可行,毕竟这种方法在企业中的效率也就只是几个人两个半小时几百行代码的样子
所以,萌生了一种很没趣的方式——评测机玩法
我也叫它摇奖玩法,就是通过自己定义一个生成逻辑,然后模拟评测机去一直测测测,什么时候测到了就算捞到了,这个方法主要的效果是会给编程人员较大的压力和动力去完善自己的代码,对于评测人员,应该可以提高编写脚本的能力,可谓收获颇丰呢
三、关于设计模式
既然说到设计模式了,就简单提一下
对于本次作业,我觉得有下面这两种模式都是比较推荐的:
- 工厂模式,借用工厂模式将因子的生成逻辑(判断 + 生成)封装,代码看起来会很简洁,也可以看到我从第二次作业,类图里面就多了一个
FactorFactory - 装饰者模式,这个主要用于解决化简优化问题,每个化简逻辑可以被定义为一个装饰者,然后将求导的结果一层层装饰,最终获得优化结果,这个模式是笔者前两天才想起的,没有用到作业中也是可惜了
我永远喜欢着OOP——第一次总结的更多相关文章
- [洛谷P3987]我永远喜欢珂朵莉~
[洛谷P3987]我永远喜欢珂朵莉~ 题目大意: 给你\(n(n\le10^5)\)个数\(A_{1\sim n}(A_i\le5\times10^5)\),\(m(m\le5\times10^5)\ ...
- 我永远爱着OOP——第二单元作业总结
第二单元的电梯真是愉♂快呢,多线程编程作为java编程OOP中的重要组成部分,通过这一个单元的学习,我也是有了很多全新的认识 那么下面就先例行一下公事 三次作业分析 第五次作业 设计分析 实现的电梯是 ...
- OOP第一次博客作业
一.关于Java&&面向对象 本学期刚开始进行Java的学习,也是刚开始了解面向对象,目前也就学习了三四周的样子,期间进行了三次作业,我感觉到Java的语法和c语言中的有许多相似之处, ...
- 洛谷P3987 我永远喜欢珂朵莉~(set 树状数组)
题意 题目链接 Sol 不会卡常,自愧不如.下面的代码只有66分.我实在懒得手写平衡树了.. 思路比较直观:拿个set维护每个数出现的位置,再写个线段树维护区间和 #include<bits/s ...
- 我永远喜欢我的偶像 KIKU
- 【木德木作杯楼市达人秀NO.28】南湖买房故事
应得意版主的邀请,我也来写写我的买房故事,虽然过程没有别人那么惊心动魄,但是毕竟是自己人生中非常重要的一件事情,就像恋爱一样,情话永远没有情书好,我也借此纪念一下这段短暂的时光.其中会涉及到本人对一些 ...
- 【计算机网络】应用层(一) HTTP
HTTP报文 HTTP报文是HTTP应用程序间发送的数据块,它由三部分组成:起始行(start line),首部(header)和主体(body),如下图所示: 从分类上,报文又可以分为请求报 ...
- System.Collections 学习
public interface IEnumerator { object Current { get; } bool MoveNext(); void Reset(); } public inter ...
- BZOJ 3143 游走 | 数学期望 高斯消元
啊 我永远喜欢期望题 BZOJ 3143 游走 题意 有一个n个点m条边的无向联通图,每条边按1~m编号,从1号点出发,每次随机选择与当前点相连的一条边,走到这条边的另一个端点,一旦走到n号节点就停下 ...
随机推荐
- [转] Firewall and network filtering in libvirt
Firewall and network filtering in libvirt There are three pieces of libvirt functionality which do n ...
- 微服务中Feign快速搭建
在微服务架构搭建声明性REST客户端[feign].Feign是一个声明式的Web服务客户端.这使得Web服务客户端的写入更加方便 要使用Feign创建一个界面并对其进行注释.它具有可插入注释支持,包 ...
- 谦先生-hadoop大数据运维纪实
1.NN宕掉切不过去先看zkfc的log引起原因是dfs.ha.fencing.ssh.private-key-files的配置路径配错造成以致无法找到公钥 2.dfs.namenode.shared ...
- JSON Web Token(JWT)使用步骤说明
在JSON Web Token(JWT)原理和用法介绍中,我们了解了JSON Web Token的原理和用法的基本介绍.本文我们着重讲一下其使用的步骤: 一.JWT基本使用 Gradle下依赖 : c ...
- 抓包工具 Fiddler 使用介绍
简介 Fiddler是一个抓包工具,可以将网络传输发送与接收的数据包进行截获.重发.编辑等操作.也可以用来检测流量.原理是以web代理服务器的形式进行工作的,使用的代理地址是:127.0.0.1,端口 ...
- FF中flash滚轮失效的解决方案
概述 在FF浏览器中有这样一个bug,就是当鼠标hover在flash区域的时候,滚轮会失效.原因是ff浏览器没有把滚轮事件嵌入到flash里面去.如果这个flash很小的话,比如直播的视频,会很容易 ...
- 几个实用的CSS代码段总结
废话不多说,直接上代码,希望能帮到有需要的小伙伴 ①:遮罩 position: fixed; background: rgba(0, 0, 0, .4); top: 0; left: 0; right ...
- PHP之ThinkPHP框架(数据库)
PHP是网站后台开发语言,其重要的操作对象莫过于数据库,之前有了解过mysqli和pdo,但ThinkPHP的数据库交互必须使用其特定的封装方法,或者可以认为其是对PHP数据库操作的进一步封装,以达到 ...
- Android项目创建.prorperties配置文件和调用方法
刚接触Android开发不久,今天写项目发现里面的可变参数有点多,(主要是服务器访问路径), 如果路径改变或者改名字了的话,若都写在代码里,岂不是要炸了? 我想到了Java项目里的有个.prorper ...
- Ocelot简易教程(四)之请求聚合以及服务发现
上篇文章给大家讲解了Ocelot的一些特性并对路由进行了详细的介绍,今天呢就大家一起来学习下Ocelot的请求聚合以及服务发现功能.希望能对大家有所帮助. 作者:依乐祝 原文地址:https://ww ...