python 之常用模块
一 认识模块
二 常用模块
(1)re模块
(2)collections模块
一 认识模块
(1)什么是模块
(2)模块的导入和使用
(1)模块是:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
但其实import加载的模块分为四个通用类别:
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包
4 使用C编写并链接到python解释器的内置模块
为什么要使用模块?
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用,
(2)模块的导入和使用
更多内容:http://www.cnblogs.com/Eva-J/articles/7292109.html
二 常用模块
re 模块
引入通过一个京东的注册例子来引入:https://reg.jd.com/reg/person?ReturnUrl=https%3A//www.jd.com
如果我们在电话号码那一栏随便写上‘11111111111’它会给出格式错误
这个功能是怎样实现的呢?
假如现在你用python写一段代码,类似:
phone_number = input('please input your phone number : ')
如何判断输入的电话号码是合法的?
根据手机号码一共11位并且是以13、14/15/17/18开头的数字这些特点,我们用python可以写了如下代码:
import re
while True:
phone_number = input('please input your phone number : ')
if len(phone_number) == 11 \
and phone_number.isdigit()\
and (phone_number.startswith('') \
or phone_number.startswith('') \
or phone_number.startswith('') \
or phone_number.startswith('')\
or phone_number.startswith('')):
print('是合法的手机号码')
else:
print('不是合法的手机号码'):
优化后的代码是:
import re
while True:
phone_number=input('please input your phone number:')
if re.match('^(13|14|15|18|17)[0-9]{9}$',phone_number):
print('是合法的手机号码')
else:
print('不是合法的手机号码')
re模块 和 正则表达式
他俩的关系:不管你以后是不是去做python开发,只要你是一个程序员就应该了解正则表达式的基本使用。如果未来你要在爬虫领域发展,你就更应该好好学习这方面的知识。
但是re模块本质上和正则表达式没有一毛钱的关系。re模块和正则表达式的关系,类似于time模块和时间的关系
时间有自己的格式,年月日使分秒,12个月。。。。已经成为了一种规格。time模块只不过是python提供给我们的可以方便我们操作时间的一个工具而已。
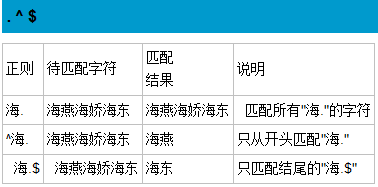
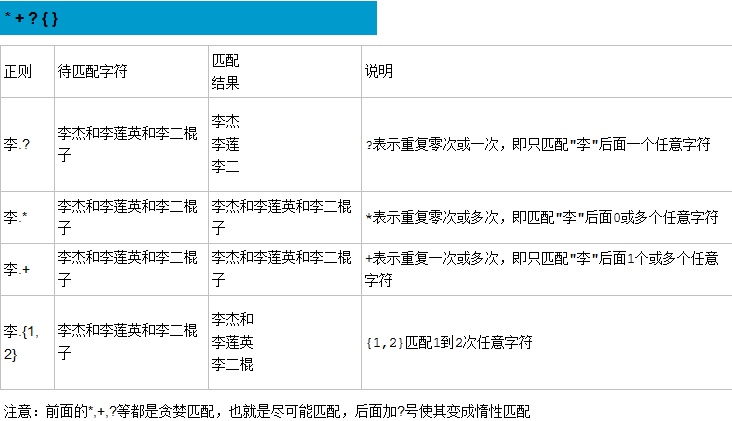
正则表达式:是匹配字符串内容的一种规则。
定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来报答对字符串的一种过滤逻辑。
正则表达式的在线测试工具http://tool.chinaz.com/regex/
我们谈到正则表达式都是跟字符串有关系。在线测试工具里,你输入的每一个字都是一个字符串。其次,如果在一个位置的一个值,不会出现什么变化,那么是不需要规则的。
如果你要用‘1’去匹配‘1’,或者用‘2’去匹配‘2’,直接可以匹配上。这些事不需要高深的理论。
那么在之后我们要更多考虑的是在同一个位置上 可以出现的字符范围。
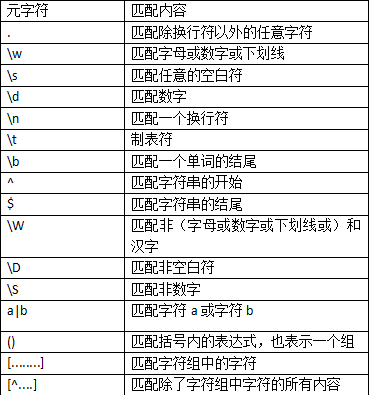
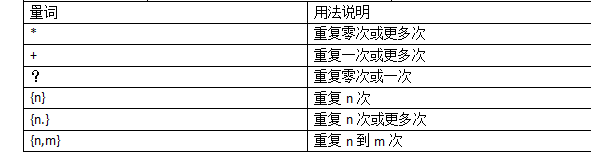
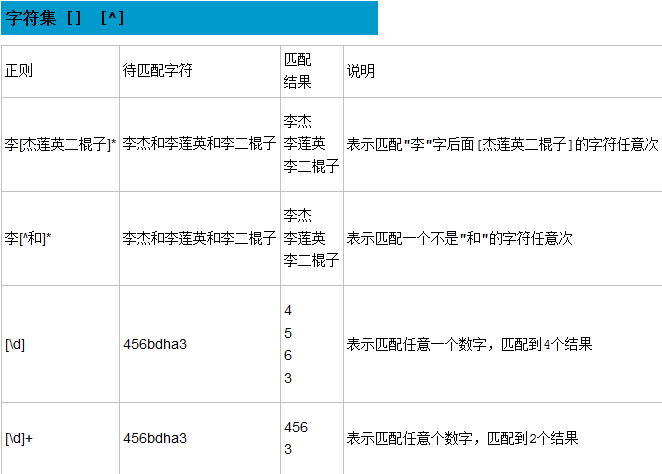
字符组:[字符组]
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
字符分为很多类,数字、字母、标点等等。
假如你现在要求一个位置‘只能出现一个数字’,那么这个位置上的字符只能是0、1........9这个10个数之一。



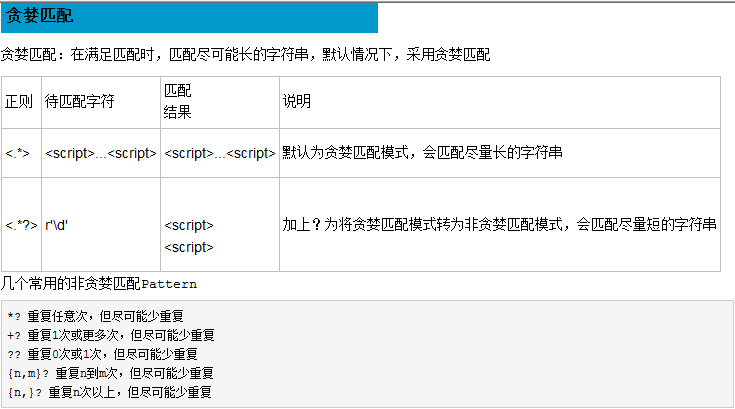

re 模块的应用
import re
# ret=re.findall('a','eval agen heh')
# print(ret)
# ret=re.search('a','aval egon hah ')
# print(ret.group)
# ret=re.match('a','agon avel haha').group()
# print(ret)
# ret=re.split('[ab]','abcd')
# print(ret)
# ret=re.sub('\d','H','123abade456')
# print(ret)
# ret=re.subn('\d','H','123abade456')
# print(ret)
# obj=re.compile('\d{3}')
# ret=obj.search('adajfafg123wwww')
# print(ret.group())
# ret=re.finditer('\d','daohgaljflahgl123456aoafhlfjaljf')
# print(ret)
# print(next(ret).group())
# print(next(ret).group())
findall的优先级
import re
ret=re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(ret)
ret=re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret)
split的加括号和不加括号的区别
import re
# ret=re.split('\d+','afljalfjlajgl123465ddiei145q')
# print(ret)
# ret=re.split('(\d+)','afljalfjlajgl123465ddiei145q')
# print(ret)
在匹配部分加上括号可以保留分割的数字这个在某些时候特别重要。
在匹配部分不加括号就不会保留分割的数字。
练习题:
匹配标签
import re
ret=re.search('<(?P<tag_name>\w+)>\w+</(?P=tag_name)>','<h1>hello</h1>')
print(ret.group())
ret=re.search(r'<(\w+)>\w+</\1>','<h1>hello</h1>')
print(ret.group(1))
匹配整数
import re
# ret=re.findall('\d+','1 - 2 * ( (60-30 +(-40.36/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2)')
# print(ret)
# ret=re.findall(r'-?\d+\.\d*|(-?\d+)','1 - 2 * ( (60-30 +(-40.36/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2)')
# print(ret)
# ret.remove('')
# print(ret)
数字匹配
import re
# while True:
# s=input('>>请输入月份:').strip()
# if re.match('(^(0?[1-9]|1[0-2])$)',s):
# print('输入月份正确')
# else:
# print('格式不正确') # while True:
# s=input('>>请输入qq号:').strip()
# if re.match('^[1-9][0-9]{4,}$',s):
# print('输入格式正确')
# else:
# print('格式不正确') # while True:
# s=input('>>请输入一个浮点数:').strip()
# if re.match('^(-?\d+)(\.\d*)?$',s):
# print('输入格式正确')
# else:
# print('格式不正确') # while True:
# s=input('>>请输入一个汉字:').strip()
# if re.match('^[\u4e00-\u9fa5]{0,}$',s):
# print('输入格式正确')
# else:
# print('格式不正确')
爬虫练习
import requests
import re
import json def getPage(url):
response = requests.get(url)
return response.text def parsePage(s):
com = re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S) ret = com.finditer(s)
for i in ret:
yield {
"id": i.group("id"),
"title": i.group("title"),
"rating_num": i.group("rating_num"),
"comment_num": i.group("comment_num"),
} def main(num):
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
print(ret)
f = open("move_info7", "a", encoding="utf8") for obj in ret:
print(obj)
data = json.dumps(obj, ensure_ascii=False)
f.write(data + "\n") if __name__ == '__main__':
count =
for i in range():
main(count)
count +=
collections模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
namedtuple
# from collections import namedtuple
# Point=namedtuple('Point',['x','y'])
# p=Point(1,2)
# print(p.x)
# print(p.y)
deque用于插入和删除数据
# from collections import deque
# q=deque(['x','y','z'])
# q.append('a')
# q.appendleft('w')
# print(q)
OrderdDict 有序的字典
from collections import OrderedDict
# d=dict([('a',1),('b',2),('d',5),('c',3)])
# print(d)
# d1=OrderedDict([('a',1),('c',2),('d',7)])
# print(d1)
# d=OrderedDict()
# d['x']=1
# d['y']=5
# d['z']=9
# print(d)
defaultdict
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66 , 'k2': 小于66}values = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90]
my_dict = {}
for value in values:
if value > 66:
if my_dict.get('k1'):
my_dict['k1'].append(value)
else:
my_dict['k1'] = [value]
else:
if my_dict.get('k2'):
my_dict['k2'].append(value)
else:
my_dict['k2'] = [value]
print(my_dict)
另一种解法:
from collections import defaultdict
values = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90]
dic=defaultdict(list)
for value in values :
if value>66:
dic['k1'].append(value)
else:
dic['k2'].append(value)
print(dic)
Counter计数的
from collections import Counter
c=Counter('adcddafkajljgljl')
print(c)
python 之常用模块的更多相关文章
- python的常用模块之collections模块
python的常用模块之collections模块 python全栈开发,模块,collections 认识模块 什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文 ...
- python之常用模块
python 常用模块 之 (subprocess模块.logging模块.re模块) python 常用模块 之 (序列化模块.XML模块.configparse模块.hashlib模块) pyth ...
- python之常用模块二(hashlib logging configparser)
摘要:hashlib ***** logging ***** configparser * 一.hashlib模块 Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等. 摘要算法 ...
- Python学习——python的常用模块
模块:用一堆代码实现了某个功能的代码集合,模块是不带 .py 扩展的另外一个 Python 文件的文件名. 一.time & datetime模块 import time import dat ...
- Python之常用模块--collections模块
认识模块 什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编写的 ...
- Python自动化开发之python的常用模块
python常用模块 模块的种类:模块分为三种,分别是自定义模块:内置标准模块(即标准库):开源模块(第三方). 以下主要研究标准模块即标准库:标准库直接导入即可,不需要安装. 时间模块:time , ...
- python基础----常用模块
一 time模块(时间模块)★★★★ 时间表现形式 在Python中,通常有这三种方式来表示时 ...
- python(五)常用模块学习
版权声明:本文为原创文章,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明. https://blog.csdn.net/fgf00/article/details/52357 ...
- python学习——常用模块
在学习常用模块时我们应该知道模块和包是什么,关于模块和包会单独写一篇随笔,下面先来了解有关在python中的几个常用模块. 一.什么是模块 常见的场景:一个模块就是一个包含了python定义和声明的文 ...
随机推荐
- 【WebSocket No.3】使用WebSocket协议来做服务器
写在开始 上面一篇写了一篇使用WebSocket做客户端,然后服务端是socke代码实现的.传送门:webSocket和Socket实现聊天群发 本来我是打算写到一章上的,毕竟实现的都是一样的功能,后 ...
- C语言异常处理之 setjmp()和longjmp()
异常处理之除0情况 相信大家处理除0时,都会通过函数,然后判断除数是否为0,代码如下所示: double divide(doublea,double b) { const double delta = ...
- #WEB安全基础 : HTML/CSS | 0x2初识a标签
教你点厉害玩意,尝尝HTML的厉害! 我为了这节课写了一些东西,你来看看
- C#DataTable复制、C#DataTable列复制、C#DataTable字段复制
try { //获取满足条件的数据 DataTable Mdr = datable.Select().ToString("yyyy-MM-dd HH:mm:ss") + " ...
- K8s helm 创建自定义Chart
# 删除之前创建的 chart helm list helm delete --purge redis1 # 创建自定义 chart myapp cd ~/helm helm create myapp ...
- php小程序登录时解密getUserInfo获取openId和unionId等敏感信息
在获取之前先了解一下openId和unionId openId : 用户在当前小程序的唯一标识 unionId : 如果开发者拥有多个移动应用.网站应用.和公众帐号(包括小程序),可通过unionid ...
- CSS3的媒体查询(Media Queries)与移动设备显示尺寸大全
媒体查询介绍 我今天就总结一下响应式设计的核心CSS技术Media(媒体查询器)的用法. 先看一个简单的例子: <link rel="stylesheet" media=&q ...
- RabbitMQ 环境搭建
安装基础环境 yum install net-tools yum install yum yum install gcc glibc-devel make ncurses-devel openssl- ...
- Java的关键字
下面列出Java关键字.这些保留字不能用于常量.变量和任标识示字符的名称 没事儿时多背背,对你没有坏处哒! 类别 关键字 说明 访问控制 private 私有的 protected 受保护的 publ ...
- jquery带参插件函数的编写
<!DOCTYPE html><html><head lang="en"> <meta charset="UTF-8" ...