【译】深度双向Transformer预训练【BERT第一作者分享】
目录
翻译自Jacob Devlin分享的slides
NLP中的预训练
词嵌入是利用深度学习解决自然语言处理问题的基础。

词嵌入(例如word2vec,GloVe)通常是在一个较大的语料库上利用词共现统计预训练得到的。例如下面两个句子中,由于king和queen附近的上下文时常相同或相似,那么在向量空间中,这两个词的距离较为接近。

语境表示
问题:通常的词嵌入算法无法表现一个词在不同语境(上下文)中不同的语义。例如bank一词在下列两个句子中有着不同的语义,但是却只能使用相同的向量来表示。

解决方案:在大语料上训练语境表示,从而得到不同上下文情况下的不同向量表示。

语境表示相关研究
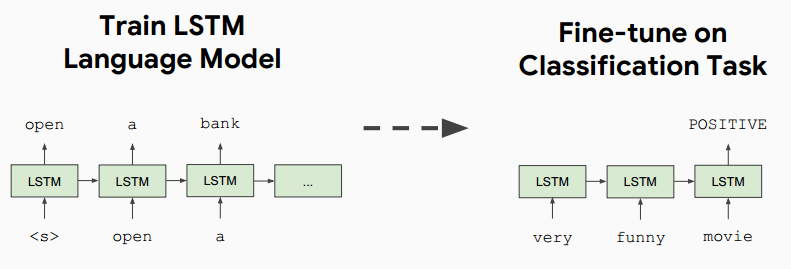
2018年中:GPT: Improving language understanding by generative pre-training, OpenAI
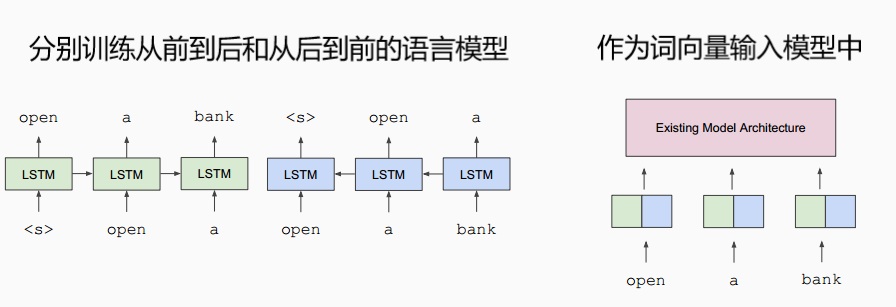
译者注:比较著名的还有2018年初fast.ai提出的ULMFiT
存在的问题
- 问题:语言模型的训练,要么仅适用上文,要么仅适用下文;而人类理解语言则是同时考虑上下文的。
- 为什么说语言模型是单向的
- 理由1:为了生成适合模型计算的概率分布
- 理由2:如果使用双向的编码器,因为这会产生一些循环,在这些循环中,单词会间接地“窥见”自己

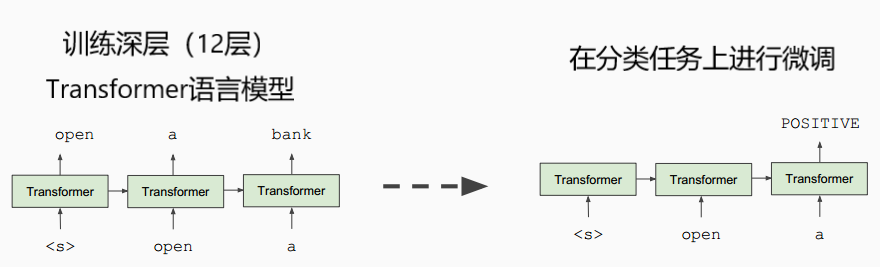
BERT的解决方案
任务一:Masked LM
把输入序列中的k%(一般为15%)的词掩盖住,然后通过上下文预测这些被掩盖住的词。

- k%的设置
- k太小:计算代价过大
- k太大:剩下的上下文不足以准确预测
- 遇到的问题:在预训练过程中所使用的这个特殊符号,在后续的任务中是不会出现的。
- 由于15%的词被遮住,那么就有15%的词要被语言模型预测,但是BERT并不是一词就将所有这些词都用[MASK]替换掉,而是

任务二:预测下一句
学习句子间的关系,预测句子B是否句子A的下一句话(译者注:二元分类任务)。

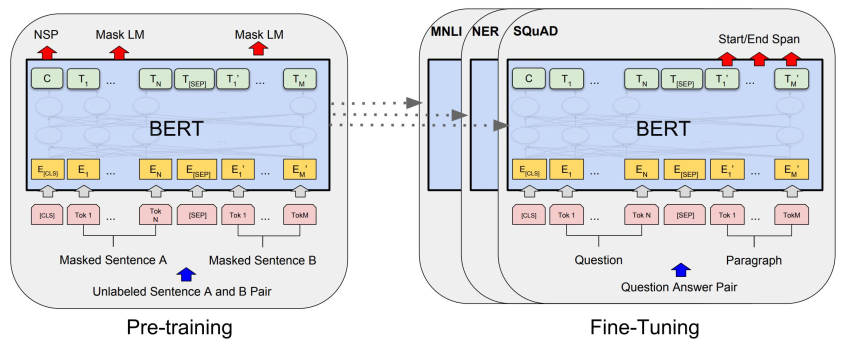
BERT
输入表示

- 使用30,000 WordPiece 词表(BERT 用 WordPiece工具来进行分词,并插入特殊的分离符([CLS],用来分隔样本)和分隔符([SEP],用来分隔样本内的不同句子))
- 每一个token由三种向量加和而成
- 单一序列更高效
模型结构——Transformer编码器
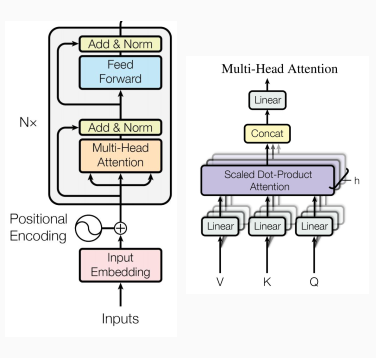
- 多头注意力机制
- 上下文建模
- 前向层
- 计算非线性层次特征
- 正则化与残差
- 让深层网络更有效
- 位置向量
- 让模型学习相对位置的特征
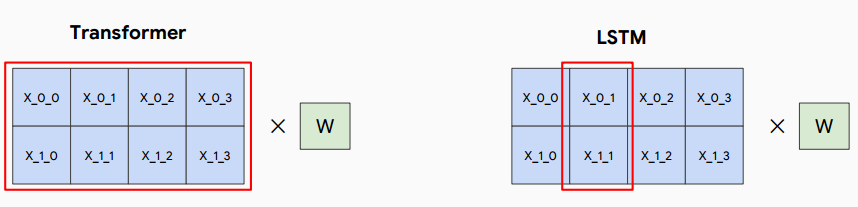
Transformer vs. LSTM
- 自注意力机制不管词间距离长短而直接计算其依赖关系
- 每一层进行乘法运算在TPU上更高效
- 有效的batch_size是词数而不是序列数
模型细节
- 语料: Wikipedia (2.5B words) + BookCorpus (800M words)
- Batch Size: 131,072 个词 (1024 个序列* 每个序列128个词或者256个序列 *每个序列512个词)
- 训练时间: 1M steps (~40 epochs)
- Optimizer: AdamW, 1e-4 learning rate, linear decay
- BERT-Base: 12-layer, 768-hidden, 12-head
- BERT-Large: 24-layer, 1024-hidden, 16-head
- 在4x4 或 8x8 的TPU slice上训练了4天
在不同任务上进行微调
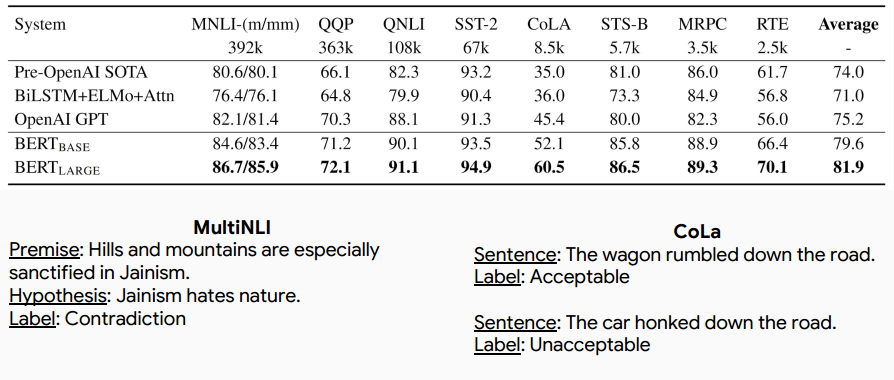
GLUE
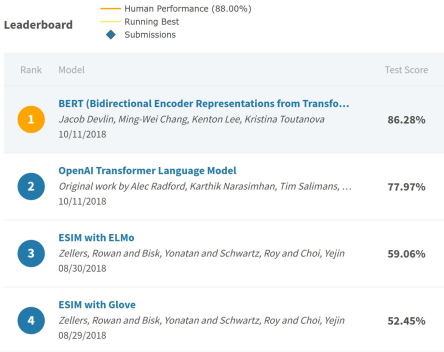
SQuAD 1.1

*注:榜单已经被很多基于BERT的模型刷新了
SQuAD 2.0

SWAG
分析
预训练的影响
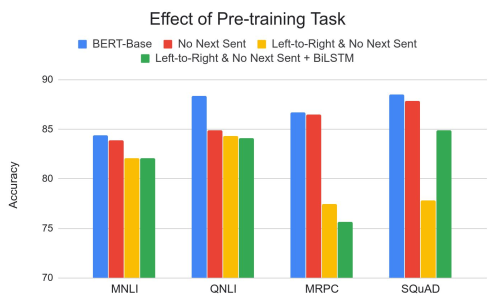
- 相较于从前到后(从左到右)语言模型,在一些任务中,Masked LM更重要,还有一些任务中,预测下一句这一策略很重要。
- 从前到后的模型在词级别的任务(如SQuAD)上表现平平,加上BiLSTM后效果也一般。
方向与训练时间的影响
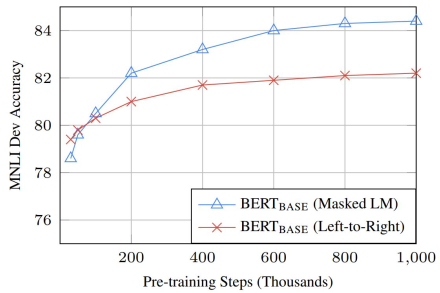
- 由于仅仅预测15%的词,因此Masked LM收敛速度仅仅慢了一点点
- Masked LM的绝对结果显然更好
模型规模的影响
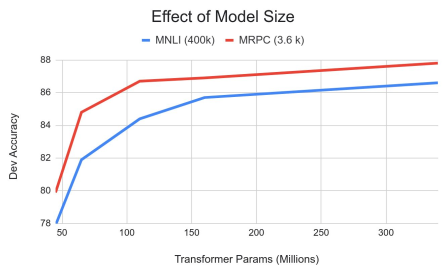
- 大模型更有效
- 即使在仅有3,600个标注样本的数据集上,把参数从110M调整到340M也带来了性能提升
- 性能提升并不是渐进的
遮罩策略的影响

- 一次遮住100%的词让基于特征的方法在性能上有所下降
- 而100%使用随机替换的方式让基于特征的方法在性能上下降幅度较小
多语言BERT(机器翻译)
- 在104种语言的维基百科数据上训练不同的语言模型,共享110k的WordPiece 词表
- XNLI是由MultiNLI翻译为多种语言得到的
- 在人工翻译测试集上进行性能评估
- 机器翻译-训练:将英文翻译为其他语言,然后进行微调
- 机器翻译-测试:将其他语言翻译为英文,使用英文模型
- 零样本:在英文模型上使用其他语言进行测试
生成训练数据(机器阅读理解)
使用seq2seq模型从context+answer中生成正例问题
启发式地将正例问题转换为负例(如“no answer”/impossible )
在维基百科数据上预训练seq2seq模型
- 用BERT作为编码器,训练解码器解码下一个句子
在SQuAD 进行微调——Context+Answer →Question
- Ceratosaurus was a theropod dinosaur in the Late Jurassic, around 150 million years ago. -> When did the Ceratosaurus live ?
训练模型,预测答案,不使用问题描述
- Ceratosaurus was a theropod dinosaur in the Late Jurassic, around 150 million years ago. -> {150 million years ago, 150 million, theropod dinsoaur, Late Jurassic, in the Late Jurassic}
使用第三步的模型从大量维基百科数据中生成答案
使用第四步的输出作为seq2seq模型的输入,生成问题描述
- Roxy Ann Peak is a 3,576-foot-tall mountain in the Western Cascade Range in the U.S. state of Oregon. → What state is Roxy Ann Peak in?
利用基线SQuAD2.0 系统过滤不好的问题
- ○ Roxy Ann Peak is a 3,576-foot-tall mountain in the Western Cascade Range in the U.S. state of Oregon. → What state is Roxy Ann Peak in? ( 好问题)
○ Roxy Ann Peak is a 3,576-foot-tall mountain in the Western Cascade Range in the U.S. state of Oregon. → Where is Oregon? (坏问题)
- ○ Roxy Ann Peak is a 3,576-foot-tall mountain in the Western Cascade Range in the U.S. state of Oregon. → What state is Roxy Ann Peak in? ( 好问题)
启发式地生成强负例
- 从同一文档的其他段落中获得正例问题
- What state is Roxy Ann Peak in? → When was Roxy Ann Peak first summited?
- 将一些词替换为段落内相同 POS标识类型的词
- What state is Roxy Ann Peak in? → What state is Oregon in?
- What state is Roxy Ann Peak in? → What mountain is Roxy Ann Peak in?
- 从同一文档的其他段落中获得正例问题
可选步骤: Two-pass训练,
常见问题
- 深度双向性是必要的吗?在更大的模型上像ELMo这种类型的浅层双向性怎么样?
- 深度双向性的优点:训练耗时稍短
- ELMo这种类型的浅层双向模型的缺点:
- 需要在上面增加非预训练的双向模型
- 从后到前的SQuAD模型看不到问题描述
- 需要训练两个模型
- 错位:从前到后(LTR)预测下一个词,从后到前(RTL)预测前一个词
- 增加预训练任务并不是没有用
- 为什么之前没有人想到这一点?或者说,为什么在ELMo之前语境预训练没有流行起来?
- 比起有监督训练,计算开销更大
- 在2013年,从零训练2层的512维的LSTM情感分析模型,需要花费约8小时进行训练,正确率达到80%;而预训练的语言模型在同样的结构上需要消耗一周的时间,而正确率也就能达到80.5%。(谁会为了这么一点点提升却消耗这么大的计算代价?)
- 靠这一个模型能解决NLP中的所有问题吗?
- 就目前而言,在大部分任务上是可以由这一模型解决的
结论
- 使用预训练,更大的模型意味着更好的性能,目前没有证明其界限
- 研究者或企业在BERT上建立模型,会带来更好的模型性能
【译】深度双向Transformer预训练【BERT第一作者分享】的更多相关文章
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- 【转载】BERT:用于语义理解的深度双向预训练转换器(Transformer)
BERT:用于语义理解的深度双向预训练转换器(Transformer) 鉴于最近BERT在人工智能领域特别火,但相关中文资料却很少,因此将BERT论文理论部分(1-3节)翻译成中文以方便大家后续研 ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- 预训练语言模型的前世今生 - 从Word Embedding到BERT
预训练语言模型的前世今生 - 从Word Embedding到BERT 本篇文章共 24619 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embeddi ...
- 学习AI之NLP后对预训练语言模型——心得体会总结
一.学习NLP背景介绍: 从2019年4月份开始跟着华为云ModelArts实战营同学们一起进行了6期关于图像深度学习的学习,初步了解了关于图像标注.图像分类.物体检测,图像都目标物体检测等 ...
- 最强 NLP 预训练模型库 PyTorch-Transformers 正式开源:支持 6 个预训练框架,27 个预训练模型
先上开源地址: https://github.com/huggingface/pytorch-transformers#quick-tour 官网: https://huggingface.co/py ...
- 知识增强的预训练语言模型系列之ERNIE:如何为预训练语言模型注入知识
NLP论文解读 |杨健 论文标题: ERNIE:Enhanced Language Representation with Informative Entities 收录会议:ACL 论文链接: ht ...
- NLP与深度学习(六)BERT模型的使用
1. 预训练的BERT模型 从头开始训练一个BERT模型是一个成本非常高的工作,所以现在一般是直接去下载已经预训练好的BERT模型.结合迁移学习,实现所要完成的NLP任务.谷歌在github上已经开放 ...
随机推荐
- RESTful API浅谈
一.REST的由来 全称:REST,全称是Resource Representational State Transfer,即:资源在网络中以某种形式进行状态转移.————所谓状态的转移,可参考< ...
- Javascript 将字符串替换为特定的规律的字符串
Javascript 将字符串替换为特定的规律的字符串 这是测试过程,可以再简化一点. function spinalCase(str) { // "It's such a fine lin ...
- js获取时间戳的三种方法
1.Date.Now() 2.new Date().getTime() 3.Date.parse(new Date()) 其中1和2是相同含义 chrome控制台键入:Date.now() ===ne ...
- JavaWeb数据库长时间不访问断开链接解决思路
这几天开发的线上商超系统长时间不操作,会频繁的出现第一次登陆或者跟数据库操作有关的方法都会报500错误,很是鸡肋啊这个问题. 经过网上不断的探索,在知识的海洋里畅游了几分钟后我自己总结出一套方法,我用 ...
- 批处理判断是BIOS还是UEFI启动
https://files.cnblogs.com/files/liuzhaoyzz/detectefi.rar @echo offpushd %~dp0reg add "HKEY_CURR ...
- Azkaban各种类型的Job编写
一.概述 原生的 Azkaban 支持的plugin类型有以下这些: command:Linux shell命令行任务 gobblin:通用数据采集工具 hadoopJava:运行hadoopMR任务 ...
- HTTP请求的502、504、499错误
1.名词解释 502 Bad Gateway:作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应(伪响应). 504 Gateway Time-out:作为网关或者代理工作的服务 ...
- 教你如何下载并破解IAR
最近参加项目要写STM8的工程的,所以用到IAR,所以就自己安装了一次然后写个心得. 因为我用到的是STM8,所以我就下载了STM8的,不过其他过程都一样的. 首先去到IAR SYSTEMS的官网,找 ...
- mysql 5.7 enable binlog
0. precondition a) install mysql 5.7, for detail please refer my blog post. 1. login mysql and chec ...
- SpringMVC Controller接收前台ajax的GET或POST请求返回各种参数
这几天写新项目遇到这个问题,看这位博主总结得不错,懒得写了,直接转!原文:http://blog.csdn.net/yixiaoping/article/details/45281721原文有些小错误 ...