自然语言17_Chinking with NLTK
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

https://www.pythonprogramming.net/chinking-nltk-tutorial/?completed=/chunking-nltk-tutorial/
代码
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 13 09:14:13 2016 @author: daxiong
"""
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer #训练数据
train_text=state_union.raw("2005-GWBush.txt")
#测试数据
sample_text=state_union.raw("2006-GWBush.txt")
'''
Punkt is designed to learn parameters (a list of abbreviations, etc.)
unsupervised from a corpus similar to the target domain.
The pre-packaged models may therefore be unsuitable:
use PunktSentenceTokenizer(text) to learn parameters from the given text
'''
#我们现在训练punkttokenizer(分句器)
custom_sent_tokenizer=PunktSentenceTokenizer(train_text)
#训练后,我们可以使用punkttokenizer(分句器)
tokenized=custom_sent_tokenizer.tokenize(sample_text) '''
nltk.pos_tag(["fire"]) #pos_tag(列表)
Out[19]: [('fire', 'NN')]
'''
'''
#测试语句
words=nltk.word_tokenize(tokenized[0])
tagged=nltk.pos_tag(words)
chunkGram=r"""Chunk:{<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser=nltk.RegexpParser(chunkGram)
chunked=chunkParser.parse(tagged)
#lambda t:t.label()=='Chunk' 包含Chunk标签的列
for subtree in chunked.subtrees(filter=lambda t:t.label()=='Chunk'):
print(subtree)
''' #文本词性标记函数
def process_content():
try:
for i in tokenized[0:5]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words) chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{""" chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged) chunked.draw() except Exception as e:
print(str(e)) process_content()
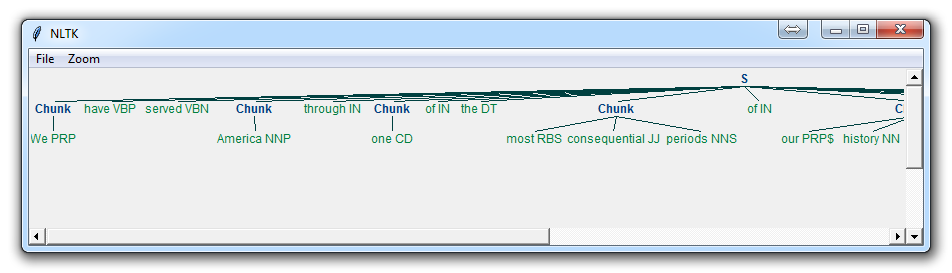
百度文库参考
http://wenku.baidu.com/link?url=YIrqeVS8a1zO_H0t66kj1AbUUReLUJIqId5So5Szk0JJAupyg_m2U_WqxEHqAHDy9DfmoAAPu0CdNFf-rePBsTHkx-0WDpoYTH1txFDKQxC
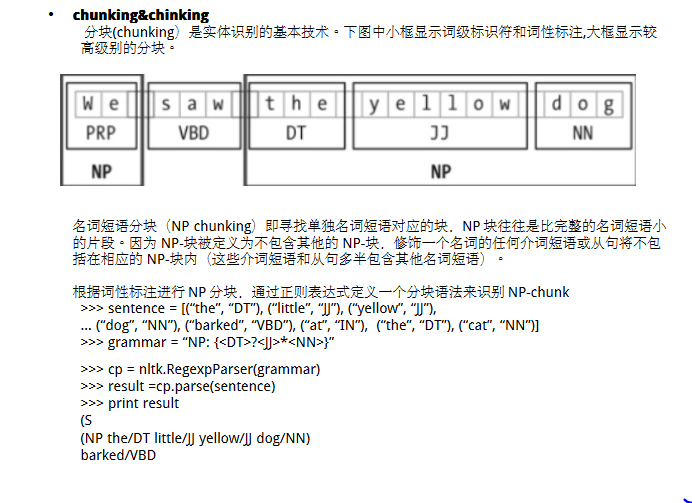


chinking可用于提取句子主干,去除不需要的修饰语
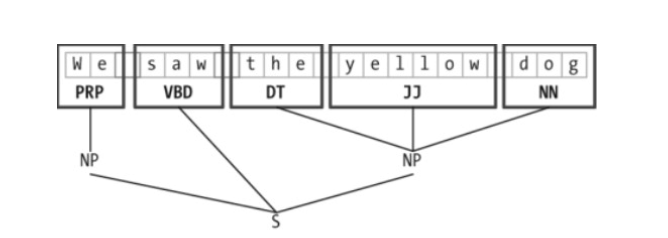
Chinking with NLTK
You may find that, after a lot of chunking, you have some words in
your chunk you still do not want, but you have no idea how to get rid
of them by chunking. You may find that chinking is your solution.
Chinking is a lot like chunking, it is basically a way for you to
remove a chunk from a chunk. The chunk that you remove from your chunk
is your chink.
The code is very similar, you just denote the chink, after the chunk, with }{ instead of the chunk's {}.
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt") custom_sent_tokenizer = PunktSentenceTokenizer(train_text) tokenized = custom_sent_tokenizer.tokenize(sample_text) def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words) chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{""" chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged) chunked.draw() except Exception as e:
print(str(e)) process_content()
With this, you are given something like:
Now, the main difference here is:
}<VB.?|IN|DT|TO>+{
此句表示,我们移除一个或多个动词,介词,定冠词,或to
This means we're removing from the chink one or more verbs, prepositions, determiners, or the word 'to'.
Now that we've learned how to do some custom forms of chunking, and chinking, let's discuss a built-in form of chunking that comes with NLTK, and that is named entity recognition.

自然语言17_Chinking with NLTK的更多相关文章
- 转 --自然语言工具包(NLTK)小结
原作者:http://www.cnblogs.com/I-Tegulia/category/706685.html 1.自然语言工具包(NLTK) NLTK 创建于2001 年,最初是宾州大学计算机与 ...
- 自然语言22_Wordnet with NLTK
QQ:231469242 欢迎喜欢nltk朋友交流 https://www.pythonprogramming.net/wordnet-nltk-tutorial/?completed=/nltk-c ...
- 自然语言16_Chunking with NLTK
Chunking with NLTK 对chunk分类数据结构可以图形化输出,用于分析英语句子主干结构 # -*- coding: utf-8 -*-"""Created ...
- Python自然语言处理工具NLTK的安装FAQ
1 下载Python 首先去python的主页下载一个python版本http://www.python.org/,一路next下去,安装完毕即可 2 下载nltk包 下载地址:http://www. ...
- Python自然语言工具包(NLTK)入门
在本期文章中,小生向您介绍了自然语言工具包(Natural Language Toolkit),它是一个将学术语言技术应用于文本数据集的 Python 库.称为“文本处理”的程序设计是其基本功能:更深 ...
- Python NLTK 自然语言处理入门与例程(转)
转 https://blog.csdn.net/hzp666/article/details/79373720 Python NLTK 自然语言处理入门与例程 在这篇文章中,我们将基于 Pyt ...
- NLTK在自然语言处理
nltk-data.zip 本文主要是总结最近学习的论文.书籍相关知识,主要是Natural Language Pracessing(自然语言处理,简称NLP)和Python挖掘维基百科Infobox ...
- Python自然语言处理工具小结
Python自然语言处理工具小结 作者:白宁超 2016年11月21日21:45:26 目录 [Python NLP]干货!详述Python NLTK下如何使用stanford NLP工具包(1) [ ...
- 自然语言处理(NLP)入门学习资源清单
Melanie Tosik目前就职于旅游搜索公司WayBlazer,她的工作内容是通过自然语言请求来生产个性化旅游推荐路线.回顾她的学习历程,她为期望入门自然语言处理的初学者列出了一份学习资源清单. ...
随机推荐
- Linux vsftp配置本地用户
主要讲的是配置本地用户, ftp现在用的也少了,一般都用ssh和svn 1. 安装ftp yum -y install vsftpd 2. 配置 /etc/vsftpd/vsftpd.conf # ...
- bzoj 3743
这道题用到了4个dfs,分别是找出所有家的最小生成树,找出一点距离树的最小距离,找出每个点儿子距离的最大值(不包括父亲,也就是指不包括根节点的子树),用父亲的值来更新自己 因为我们可以知道:如果我们在 ...
- mysql数据库默认存放位置修改
windows: 方式一 使用符号连接 假设你的mysql安装在c:\mysql,数据目录就是c:\mysql\data 现在你想在D 盘建立一个名为foo的数据库,路径为d:\data\foo. ...
- html-div自动撑大
下面提供几种解决方案,以修复该问题. 1.给父容器使用display属性 div#container { display: table; /* 建议使用 */ /*或者 display: table- ...
- UIScrollView实现图片轮播器及其无限循环效果
图片轮播器: 一.实现效果 实现图片的自动轮播 二.实现代码 storyboard中布局 代码: 1 #import "YYViewController.h" ...
- IOS实现动画的几种简单方法
1.使用 NSTimer 来实现 [NSTimer scheduledTimerWithTimeInterval:0.01 target:self selector:@selector(setNeed ...
- Leetcode 382. Linked List Random Node
本题可以用reservoir sampling来解决不明list长度的情况下平均概率选择元素的问题. 假设在[x_1,...,x_n]只选一个元素,要求每个元素被选中的概率都是1/n,但是n未知. 其 ...
- java web项目导入到eclipse中变成了java项目的一种情况的解决办法
前提,我把代码上传到github上之后,在另外一台电脑上拉下之后,先报出现的是jre不对,然后换成了当前的jre,然后红色的感叹号消失了但是之前项目上那个小地球不见了,也就是说变成了java项目. - ...
- fbv (FrameBuffer Viewer)编译指南
fbv:FrameBuffer image Viewer,可在控制台下查看jpg,png,gif,bmp等格式的图片,可以结合FBTerm在控制台设置背景图片,也可在编译在嵌入式设备上使用.但是ubu ...
- restore和recover的区别(转)
recover和restore的区别: restore just copy the physical file, recover will consistent the database. resto ...