自然语言17_Chinking with NLTK
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

https://www.pythonprogramming.net/chinking-nltk-tutorial/?completed=/chunking-nltk-tutorial/
代码
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 13 09:14:13 2016 @author: daxiong
"""
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer #训练数据
train_text=state_union.raw("2005-GWBush.txt")
#测试数据
sample_text=state_union.raw("2006-GWBush.txt")
'''
Punkt is designed to learn parameters (a list of abbreviations, etc.)
unsupervised from a corpus similar to the target domain.
The pre-packaged models may therefore be unsuitable:
use PunktSentenceTokenizer(text) to learn parameters from the given text
'''
#我们现在训练punkttokenizer(分句器)
custom_sent_tokenizer=PunktSentenceTokenizer(train_text)
#训练后,我们可以使用punkttokenizer(分句器)
tokenized=custom_sent_tokenizer.tokenize(sample_text) '''
nltk.pos_tag(["fire"]) #pos_tag(列表)
Out[19]: [('fire', 'NN')]
'''
'''
#测试语句
words=nltk.word_tokenize(tokenized[0])
tagged=nltk.pos_tag(words)
chunkGram=r"""Chunk:{<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser=nltk.RegexpParser(chunkGram)
chunked=chunkParser.parse(tagged)
#lambda t:t.label()=='Chunk' 包含Chunk标签的列
for subtree in chunked.subtrees(filter=lambda t:t.label()=='Chunk'):
print(subtree)
''' #文本词性标记函数
def process_content():
try:
for i in tokenized[0:5]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words) chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{""" chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged) chunked.draw() except Exception as e:
print(str(e)) process_content()
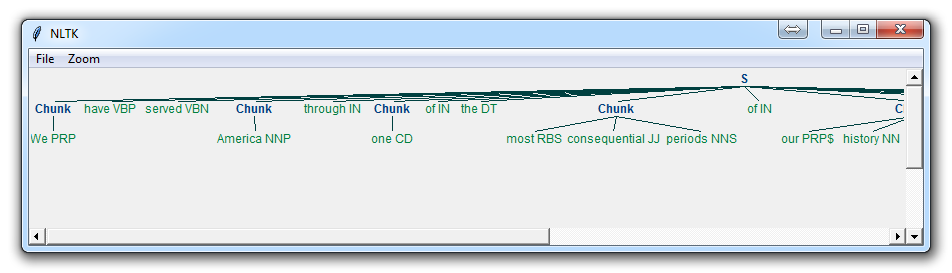
百度文库参考
http://wenku.baidu.com/link?url=YIrqeVS8a1zO_H0t66kj1AbUUReLUJIqId5So5Szk0JJAupyg_m2U_WqxEHqAHDy9DfmoAAPu0CdNFf-rePBsTHkx-0WDpoYTH1txFDKQxC
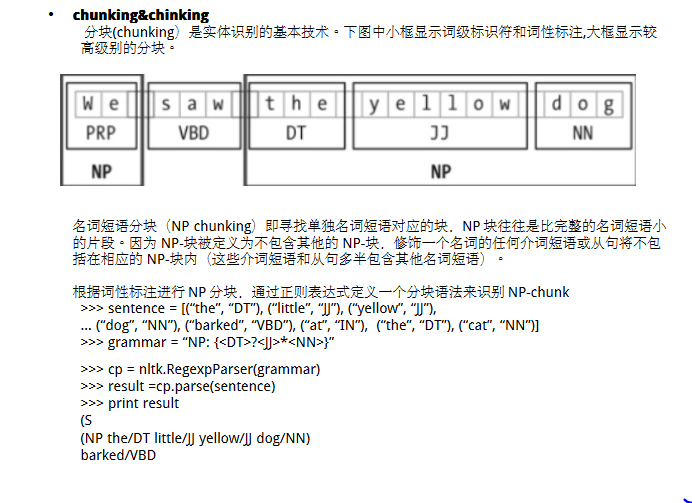


chinking可用于提取句子主干,去除不需要的修饰语
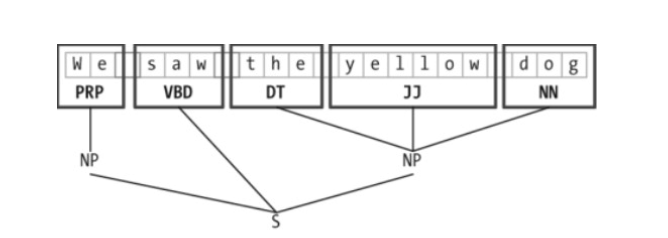
Chinking with NLTK
You may find that, after a lot of chunking, you have some words in
your chunk you still do not want, but you have no idea how to get rid
of them by chunking. You may find that chinking is your solution.
Chinking is a lot like chunking, it is basically a way for you to
remove a chunk from a chunk. The chunk that you remove from your chunk
is your chink.
The code is very similar, you just denote the chink, after the chunk, with }{ instead of the chunk's {}.
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt") custom_sent_tokenizer = PunktSentenceTokenizer(train_text) tokenized = custom_sent_tokenizer.tokenize(sample_text) def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words) chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{""" chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged) chunked.draw() except Exception as e:
print(str(e)) process_content()
With this, you are given something like:
Now, the main difference here is:
}<VB.?|IN|DT|TO>+{
此句表示,我们移除一个或多个动词,介词,定冠词,或to
This means we're removing from the chink one or more verbs, prepositions, determiners, or the word 'to'.
Now that we've learned how to do some custom forms of chunking, and chinking, let's discuss a built-in form of chunking that comes with NLTK, and that is named entity recognition.

自然语言17_Chinking with NLTK的更多相关文章
- 转 --自然语言工具包(NLTK)小结
原作者:http://www.cnblogs.com/I-Tegulia/category/706685.html 1.自然语言工具包(NLTK) NLTK 创建于2001 年,最初是宾州大学计算机与 ...
- 自然语言22_Wordnet with NLTK
QQ:231469242 欢迎喜欢nltk朋友交流 https://www.pythonprogramming.net/wordnet-nltk-tutorial/?completed=/nltk-c ...
- 自然语言16_Chunking with NLTK
Chunking with NLTK 对chunk分类数据结构可以图形化输出,用于分析英语句子主干结构 # -*- coding: utf-8 -*-"""Created ...
- Python自然语言处理工具NLTK的安装FAQ
1 下载Python 首先去python的主页下载一个python版本http://www.python.org/,一路next下去,安装完毕即可 2 下载nltk包 下载地址:http://www. ...
- Python自然语言工具包(NLTK)入门
在本期文章中,小生向您介绍了自然语言工具包(Natural Language Toolkit),它是一个将学术语言技术应用于文本数据集的 Python 库.称为“文本处理”的程序设计是其基本功能:更深 ...
- Python NLTK 自然语言处理入门与例程(转)
转 https://blog.csdn.net/hzp666/article/details/79373720 Python NLTK 自然语言处理入门与例程 在这篇文章中,我们将基于 Pyt ...
- NLTK在自然语言处理
nltk-data.zip 本文主要是总结最近学习的论文.书籍相关知识,主要是Natural Language Pracessing(自然语言处理,简称NLP)和Python挖掘维基百科Infobox ...
- Python自然语言处理工具小结
Python自然语言处理工具小结 作者:白宁超 2016年11月21日21:45:26 目录 [Python NLP]干货!详述Python NLTK下如何使用stanford NLP工具包(1) [ ...
- 自然语言处理(NLP)入门学习资源清单
Melanie Tosik目前就职于旅游搜索公司WayBlazer,她的工作内容是通过自然语言请求来生产个性化旅游推荐路线.回顾她的学习历程,她为期望入门自然语言处理的初学者列出了一份学习资源清单. ...
随机推荐
- 52-which 显示系统命令所在目录
显示系统命令所在目录 which command-list 参数 command-list 是which搜索的一条或多条命令(实用程序) 示例 which 单条命令 $ which ls /bin/l ...
- Shell脚本_判断根分区使用率
vim gen_fen_qu_shi_yong_lv.sh chmod 755 gen_fen_qu_shi_yong_lv.sh 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ...
- Shell命令_正则表达式
正则表达式是包含匹配,通配符是完全匹配 基础正则表达式 test.txt示例文件 1 2 3 4 5 6 7 8 9 10 11 12 Mr. James said: he was the hones ...
- Image Segmentation的定义
Definition 图像分割将一张图分为\(n\)个region, 需要满足下面5个条件 每一个像素都要属于一个region 每个region都是连通的 region与region之间没有交集 re ...
- 【HDU 5698】瞬间移动(组合数,逆元)
x和y分开考虑,在(1,1)到(n,m)之间可以选择走i步.就需要选i步对应的行C(n-2,i)及i步对应的列C(m-2,i).相乘起来. 假设$m\leq n$$$\sum_{i=1}^{m-2} ...
- Sublime Text 3 python和Package Control配置方法
(如果下面的方法试了Packages control功能还是不能用参考这个方法: 1.直接把C:\Sublime Text 3x64\Data\Packages\ 目录下原有的Packages c ...
- macOS 安装 pip
安装好wget之后: wget https://bootstrap.pypa.io/get-pip.py sudo python get-pip.py 终于可以愉快的pip了~
- 【poj3241】 Object Clustering
http://poj.org/problem?id=3241 (题目链接) MD被坑了,看到博客里面说莫队要写曼哈顿最小生成树,我就写了一个下午..结果根本没什么关系.不过还是把博客写了吧. 转自:h ...
- 【poj1019】 Number Sequence
http://poj.org/problem?id=1019 (题目链接) 题意 给出一个数:1 12 123 1234 12345 123456 1234567 12345678 123456789 ...
- Nuget包里的依赖包更新到最新版本会不会随主包回滚到旧包的研究
A包中有几个依赖包:A-1包,版本:>=1.0:但是我项目上已经引用了A-1包的2.0版本,那么我添加A包的时候,不会将A-1包2.0版本改成1.0版本,会直接用2.0版本的.