从join on和where执行顺序认识T-SQL查询处理执行顺序
先从一例子看join on 和 where执行结果的不同
CREATE TABLE "SCOTT"."A" (
"PERSON_ID" NUMBER(5) NULL ,
"PERSON_NAME" VARCHAR2(255 BYTE) NULL
)
;
-- ----------------------------
-- Records of A
-- ----------------------------
INSERT INTO "SCOTT"."A" VALUES ('', '张三');
INSERT INTO "SCOTT"."A" VALUES ('', '李四');
INSERT INTO "SCOTT"."A" VALUES ('', '王五');
INSERT INTO "SCOTT"."A" VALUES ('', '赵六');
INSERT INTO "SCOTT"."A" VALUES ('', '周七');
CREATE TABLE "SCOTT"."B" (
"PERSON_ID" NUMBER(5) NULL ,
"LOVE_FRUIT" VARCHAR2(255 BYTE) NULL
);
-- ----------------------------
-- Records of B
-- ----------------------------
INSERT INTO "SCOTT"."B" VALUES ('', '香蕉');
INSERT INTO "SCOTT"."B" VALUES ('', '苹果');
INSERT INTO "SCOTT"."B" VALUES ('', '橘子');
INSERT INTO "SCOTT"."B" VALUES ('', '梨');
INSERT INTO "SCOTT"."B" VALUES ('', '桃');
查询语句1
SELECT * FROM A LEFT JOIN ORACLE.B ON A.PERSON_ID=B.PERSON_ID AND A.PERSON_ID=1;
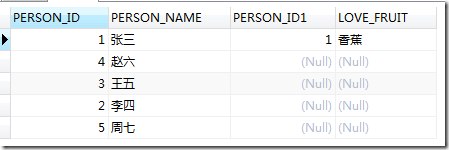
查询语句2
SELECT * FROM A LEFT JOIN ORACLE.B ON A.PERSON_ID=B.PERSON_ID WHERE A.PERSON_ID=1;

为什么结果不同呢? 可以从查询逻辑处理的过程解释。
select语句的处理过程
我们知道,SQL 查询的大致语法结构如下:
(5)SELECT DISTINCT TOP(<top_specification>) <select_list> (1)FROM <left_table> <join_type> JOIN <right_table> ON <on_predicate> (2)WHERE <where_predicate> (3)GROUP BY <group_by_specification> (4)HAVING <having_predicate> (6)ORDER BY <order_by_list>
select 语法的处理顺序
The following steps show the processing order for a SELECT statement.
- FROM
- ON
- JOIN
- WHERE
- GROUP BY
- WITH CUBE or WITH ROLLUP
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- TOP
这些步骤执行时, 每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只是最后一步生成的表才会返回给调用者。如果没有在查询中指定某一子句,将跳过相应的步骤。
select各个阶级分别干了什么:
(1)FROM 阶段
FROM阶段标识出查询的来源表,并处理表运算符。在涉及到联接运算的查询中(各种join),主要有以下几个步骤:
a.求笛卡尔积。不论是什么类型的联接运算,首先都是执行交叉连接(cross join),求笛卡儿积,生成虚拟表VT1-J1。
b.ON筛选器。这个阶段对上个步骤生成的VT1-J1进行筛选,根据ON子句中出现的谓词进行筛选,让谓词取值为true的行通过了考验,插入到VT1-J2。
c.添加外部行。如果指定了outer join,还需要将VT1-J2中没有找到匹配的行,作为外部行添加到VT1-J2中,生成VT1-J3。
经过以上步骤,FROM阶段就完成了。概括地讲,FROM阶段就是进行预处理的,根据提供的运算符对语句中提到的各个表进行处理(除了join,还有apply,pivot,unpivot)
(2)WHERE阶段
WHERE阶段是根据<where_predicate>中条件对VT1中的行进行筛选,让条件成立的行才会插入到VT2中。
(3)GROUP BY阶段
GROUP阶段按照指定的列名列表,将VT2中的行进行分组,生成VT3。最后每个分组只有一行。
(4)HAVING阶段
该阶段根据HAVING子句中出现的谓词对VT3的分组进行筛选,并将符合条件的组插入到VT4中。
(5)SELECT阶段
这个阶段是投影的过程,处理SELECT子句提到的元素,产生VT5。这个步骤一般按下列顺序进行
a.计算SELECT列表中的表达式,生成VT5-1。
b.若有DISTINCT,则删除VT5-1中的重复行,生成VT5-2
c.若有TOP,则根据ORDER BY子句定义的逻辑顺序,从VT5-2中选择签名指定数量或者百分比的行,生成VT5-3
(6)ORDER BY阶段
根据ORDER BY子句中指定的列明列表,对VT5-3中的行,进行排序,生成游标VC6.
例子解释
查询语句1的执行过程
SELECT * FROM A LEFT JOIN ORACLE.B ON A.PERSON_ID=B.PERSON_ID AND A.PERSON_ID=1;
求笛卡尔积,产生5*5=25条记录
|
PERSON_NAME |
B.PERSON_ID |
LOVE_FRUIT |
|
|
1 |
张三 |
1 |
香蕉 |
|
1 |
张三 |
2 |
苹果 |
|
1 |
张三 |
3 |
橘子 |
|
1 |
张三 |
4 |
梨 |
|
1 |
张三 |
8 |
桃 |
|
2 |
李四 |
1 |
香蕉 |
|
2 |
李四 |
2 |
苹果 |
|
2 |
李四 |
3 |
橘子 |
|
2 |
李四 |
4 |
梨 |
|
2 |
李四 |
8 |
桃 |
|
3 |
王五 |
1 |
香蕉 |
|
3 |
王五 |
2 |
苹果 |
|
3 |
王五 |
3 |
橘子 |
|
3 |
王五 |
4 |
梨 |
|
3 |
王五 |
8 |
桃 |
|
4 |
赵六 |
1 |
香蕉 |
|
4 |
赵六 |
2 |
苹果 |
|
4 |
赵六 |
3 |
橘子 |
|
4 |
赵六 |
4 |
梨 |
|
4 |
赵六 |
8 |
桃 |
|
5 |
周七 |
1 |
香蕉 |
|
5 |
周七 |
2 |
苹果 |
|
5 |
周七 |
3 |
橘子 |
|
5 |
周七 |
4 |
梨 |
|
5 |
周七 |
8 |
桃 |
ON筛选器(A.PERSON_ID=B.PERSON_ID AND A.PERSON_ID=1)
|
A.PERSON_ID |
PERSON_NAME |
B.PERSON_ID |
LOVE_FRUIT |
|
1 |
张三 |
1 |
香蕉 |
添加外部行
|
A.PERSON_ID |
PERSON_NAME |
B.PERSON_ID |
LOVE_FRUIT |
|
1 |
张三 |
1 |
香蕉 |
|
1 |
张三 |
||
|
1 |
张三 |
||
|
1 |
张三 |
||
|
1 |
张三 |
查询语句2的执行过程
SELECT * FROM A LEFT JOIN ORACLE.B ON A.PERSON_ID=B.PERSON_ID WHERE A.PERSON_ID=1;
求笛卡尔积,产生5*5=25条记录
|
A.PERSON_ID |
PERSON_NAME |
B.PERSON_ID |
LOVE_FRUIT |
|
1 |
张三 |
1 |
香蕉 |
|
1 |
张三 |
2 |
苹果 |
|
1 |
张三 |
3 |
橘子 |
|
1 |
张三 |
4 |
梨 |
|
1 |
张三 |
8 |
桃 |
|
2 |
李四 |
1 |
香蕉 |
|
2 |
李四 |
2 |
苹果 |
|
2 |
李四 |
3 |
橘子 |
|
2 |
李四 |
4 |
梨 |
|
2 |
李四 |
8 |
桃 |
|
3 |
王五 |
1 |
香蕉 |
|
3 |
王五 |
2 |
苹果 |
|
3 |
王五 |
3 |
橘子 |
|
3 |
王五 |
4 |
梨 |
|
3 |
王五 |
8 |
桃 |
|
4 |
赵六 |
1 |
香蕉 |
|
4 |
赵六 |
2 |
苹果 |
|
4 |
赵六 |
3 |
橘子 |
|
4 |
赵六 |
4 |
梨 |
|
4 |
赵六 |
8 |
桃 |
|
5 |
周七 |
1 |
香蕉 |
|
5 |
周七 |
2 |
苹果 |
|
5 |
周七 |
3 |
橘子 |
|
5 |
周七 |
4 |
梨 |
|
5 |
周七 |
8 |
桃 |
ON筛选器 (A.PERSON_ID=B.PERSON_ID )
|
PERSON_NAME |
B.PERSON_ID |
LOVE_FRUIT |
|
|
1 |
张三 |
1 |
香蕉 |
|
2 |
李四 |
2 |
苹果 |
|
3 |
王五 |
3 |
橘子 |
|
4 |
赵六 |
4 |
梨 |
添加外部行
|
PERSON_NAME |
B.PERSON_ID |
LOVE_FRUIT |
|
|
1 |
张三 |
1 |
香蕉 |
|
2 |
李四 |
2 |
苹果 |
|
3 |
王五 |
3 |
橘子 |
|
4 |
赵六 |
4 |
梨 |
|
5 |
周七 |
WHERE阶段 (A.PERSON_ID=1)
|
A.PERSON_ID |
PERSON_NAME |
B.PERSON_ID |
LOVE_FRUIT |
|
1 |
张三 |
1 |
香蕉 |
有了上面的验证,我们可以猜测下面语句的执行结果
SELECT * FROM A LEFT JOIN ORACLE.B ON A.PERSON_ID=B.PERSON_ID
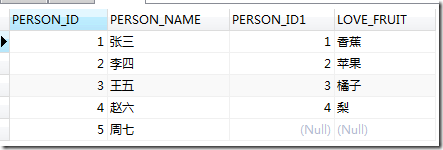
参考文献
从join on和where执行顺序认识T-SQL查询处理执行顺序
https://msdn.microsoft.com/en-us/library/ms189499%28v=SQL.100%29.aspx
从join on和where执行顺序认识T-SQL查询处理执行顺序的更多相关文章
- Mybatis按SQL查询字段的顺序返回查询结果
在SpringMVC+Mybatis的开发过程中,可以通过指定resultType="hashmap"来获得查询结果,但其输出是没有顺序的.如果要按照SQL查询字段的顺序返回查询结 ...
- 【hibernate spring data jpa】执行了save()方法 sql语句也执行了,但是数据并未插入数据库中
执行了save()方法 sql语句也执行了,但是数据并未插入数据库中 解决方法: 是因为执行了save()方法,也执行了sql语句,但是因为使用的是 @Transactional 注解,不是手动去提 ...
- spring MVC +freemarker + easyui 实现sql查询和执行小工具总结
项目中,有时候线下不能方便的连接项目中的数据源时刻,大部分的问题定位和处理都会存在难度,有时候,一个小工具就能实时的查询和执行当前对应的数据源的库.下面,就本人在项目中实际开发使用的小工具,实时的介绍 ...
- SQL 查询的执行顺序
SELECT语句的完整语法如下 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN & ...
- SQL查询语句执行的逻辑顺序
一.简介 大家都知道SELECT语句是用来查询数据表中的数据的,构成SELECT语句的还有各种元素(where.from.group by等),不同元素又代表了不同的处理逻辑,那么这些元素在执行查询时 ...
- SQL查询语句执行流程
msyql执行流程 你有个最简单的表,表里只有一个 ID 字段,在执行下面这个查询语句时:: select * from T where ID=10: 我们看到的只是输入一条语句,返回一个结果,却不知 ...
- java for循环里面执行sql语句操作,有效结果只有一次,只执行了一次sql mybatis 循环执行update生效一次 实际只执行一次
java后台controller中,for循环执行数据库操作,但是发现实际仅仅执行了一次,或者说提交成功了一次,并没有实际的个数循环 有可能是同一个对象导致的 可以仔细看一下下面两段代码有什么区别 p ...
- Mybatis按照SQL查询字段的顺序返回查询结果,使用resultType="java.util.LinkedHashMap"
在使用Mybatis开发时,Mybatis返回的结果集就是个map,当返回map时只需要做好SQL映射就好了,减少了代码量,简单便捷,缺点是不太方便维护,但是写大量的vo类去返回也挺累的,这个看你个人 ...
- SQL查询语句执行的顺序是-----------------
MSSQL逻辑查询的步骤 摘自:Microsoft SQL Server 2005技术内幕:T-SQL查询: 逻辑查询处理中的各个阶段 本节介绍逻辑查询处理所涉及的各个阶段.我先简要描述一下每个阶段, ...
- MySQL进阶8 分页查询(limit) - 【SQL查询语法执行顺序及大致结构】- 子查询的3个经典案例
#进阶8 分页查询 /* 应用场景: 当要显示的数据,一页显示不全,需要分页提交sql请求 语法: select 查询列表 #7 from 表1 #执行顺序:#1 [join type join 表2 ...
随机推荐
- Android5.0新控件RecyclerVIew的介绍和兼容使用的方法
第一部分 RecyclerVIew是一个可以替代listview和Gallery的有效空间而且在support-v7中有了低版本支持,具体使用方式还是规规矩矩的适配器加控件模式.我们先来看看官网的介绍 ...
- 关于SqlBulkCopy SQL批量导入需要注意,列名是区分大小写的
最近在做数据从Excel批量导入MSSQL时,传统的是使用Insert Into Table方法,不过这个方便比较慢 通过使用 SqlBulkCopy 可以批量导入到数据库. 默认批量导入数据库,需要 ...
- Qt中printsupport的注意点和使用方法
问题:Qt中包含QPrintDialog.QPrinter.QPrintPreviewDialog失败:在引入printsupport后报cpp:651: error: undefined refer ...
- MD5加密算法中的加盐值 ,和彩虹表攻击 防止彩虹表撞库
一.什么是彩虹表? 彩虹表(Rainbow Tables)就是一个庞大的.针对各种可能的字母组合预先计算好的哈希值的集合,不一定是针对MD5算法的,各种算法的都有,有了它可以快速的破解各类密码.越是复 ...
- Java Collection Framework : List
摘要: List 是 Java Collection Framework的重要成员,详细包括List接口及其全部的实现类.由于List接口继承了Collection接口,所以List拥有Collect ...
- 解决:CentOS下的 error while loading shared libraries: libmysqlclient.so.16: cannot open shared object file: No such file or dir
进入别人的centos,输入命令 mysql mysqladm都会报错,缺少这个共享库 libmysqlclient.so.16 . 查找下,一般都是ldconfig 没有找到共享库的位置,或者 软链 ...
- iOS:麦克风权限检测和获取
一.检测 该方法是用来判断麦克风是否进行过授权,如果授权过就直接进行需要的功能操作:如果没有进行授权,那么就要获取授权. AVAuthorizationStatus authStatus = [AVC ...
- Apache URL重写的配置 及其 apache500错误
1:如果apache报500错误时 ----->原因:可能是你的ReWrite模块没有打开(有时在apache重装时会忘记打开该模块) 将apache--->httpd.conf文件中Lo ...
- Letter Combinations of a Phone Number leetcode java
题目: Given a digit string, return all possible letter combinations that the number could represent. A ...
- jQuery EasyUI 入门简介
对于前端开发者来说,在开发过程中应用“框架”这一工具,可以极大的缩短开发时间,提高开发效率.今天我们就开介绍一款常用的框架——jQuery EasyUI. 那什么是jQuery EasyUI呢? jQ ...