基于数据库构建分布式的ID生成方案
在分布式系统中,生成全局唯一ID,有很多种方案,但是在这多种方案中,每种方案都有有缺点,下面我们之针对通过常用数据库来生成分布式ID的方案,其它方法会在其它文中讨论:
1,RDBMS生成ID:
这里我们讨论mysql生成ID。因为MySQL本身可以auto_increment和auto_increment_offset来保证ID自增,很自然地,我们会想到借助这个特性来实现这个功能。
全局ID生成方案里采用了MySQL自增长ID的机制(auto_increment + replace into + MyISAM)。一个生成64位ID方案具体实现是这样的:
先创建单独的数据库(eg:ticket),然后创建一个表:
CREATE TABLE Tickets64 (
id bigint(20) unsigned NOT NULL auto_increment,
stub char(1) NOT NULL default '',
PRIMARY KEY (id),
UNIQUE KEY stub (stub)
) ENGINE=MyISAM
表创建之后我们要设置一个初始值,比如100000,执行SELECT * from Tickets64,查询结果就是这样的:
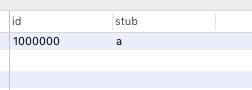
每当我们的应用需要ID的时候就会做如下操作,调用如下存储过程:
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;
架构如图:
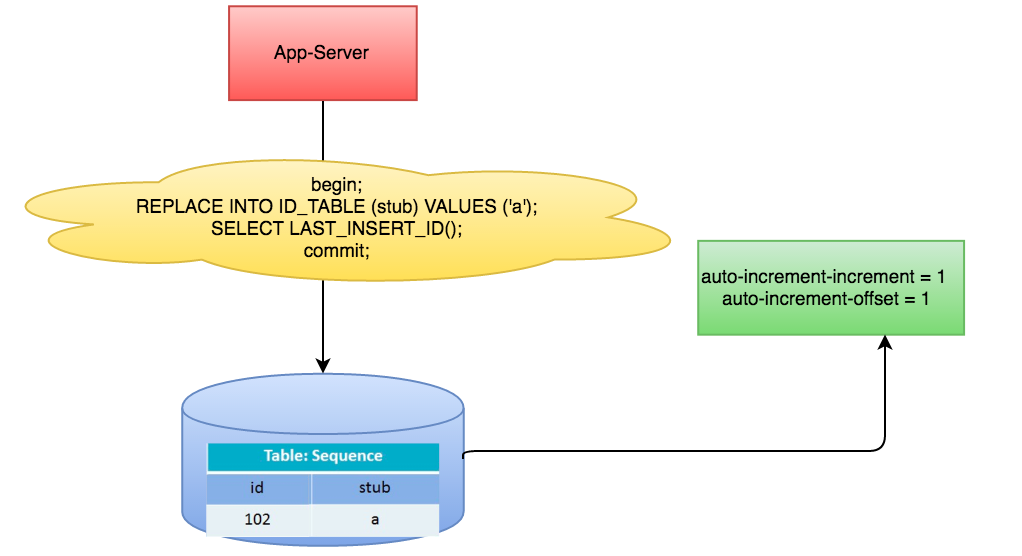
这样我们就能拿到不断增长且不重复的ID了。
这种方案的优缺点如下:
优点:
- 非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
- ID号单调自增,可以实现一些对ID有特殊要求的业务。
缺点:
- 强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
- ID发号性能瓶颈限制在单台MySQL的读写性能。
对于MySQL性能问题,可用如下方案解决:在分布式系统中我们可以多部署几台机器,每台机器设置不同的初始值,且步长和机器数相等。比如有两台机器。设置步长step为2,TicketServer1的初始值为1(1,3,5,7,9,11...)、TicketServer2的初始值为2(2,4,6,8,10...)。这是Flickr团队在2010年撰文介绍的一种主键生成策略(Ticket Servers: Distributed Unique Primary Keys on the Cheap)。如下所示,为了实现上述方案分别设置两台机器对应的参数,TicketServer1从1开始发号,TicketServer2从2开始发号,两台机器每次发号之后都递增2。
TicketServer1:
auto-increment-increment = 2
auto-increment-offset = 1 TicketServer2:
auto-increment-increment = 2
auto-increment-offset = 2
假设我们要部署N台机器,步长需设置为N,每台的初始值依次为0,1,2...N-1那么整个架构就变成了如下图所示:
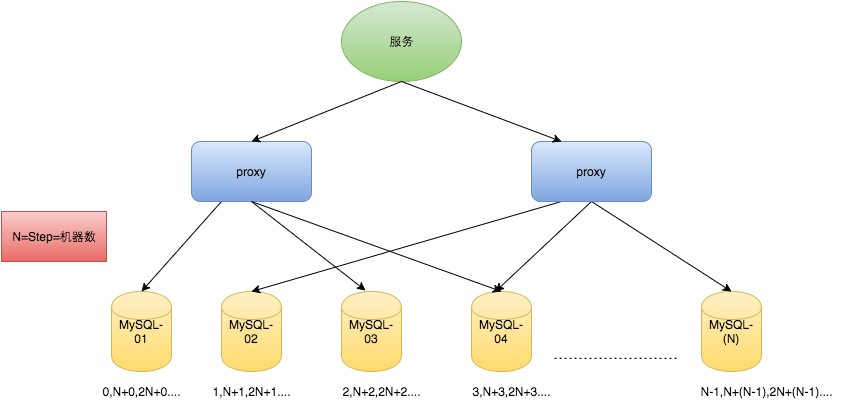
这种架构貌似能够满足性能的需求,但有以下几个缺点:
- 系统水平扩展比较困难,比如定义好了步长和机器台数之后,如果要添加机器该怎么做?假设现在只有一台机器发号是1,2,3,4,5(步长是1),这个时候需要扩容机器一台。可以这样做:把第二台机器的初始值设置得比第一台超过很多,比如14(假设在扩容时间之内第一台不可能发到14),同时设置步长为2,那么这台机器下发的号码都是14以后的偶数。然后摘掉第一台,把ID值保留为奇数,比如7,然后修改第一台的步长为2。让它符合我们定义的号段标准,对于这个例子来说就是让第一台以后只能产生奇数。扩容方案看起来复杂吗?貌似还好,现在想象一下如果我们线上有100台机器,这个时候要扩容该怎么做?简直是噩梦。所以系统水平扩展方案复杂难以实现。
- ID没有了单调递增的特性,只能趋势递增,这个缺点对于一般业务需求不是很重要,可以容忍。
- 数据库压力还是很大,每次获取ID都得读写一次数据库,只能靠堆机器来提高性能。
2,类snowflake方案
这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图(图片来自网络)所示:
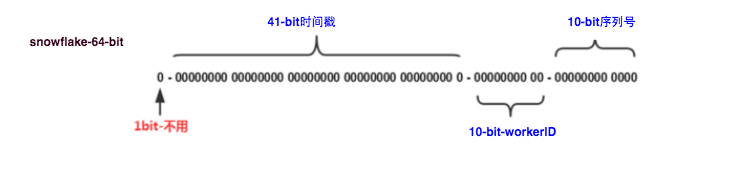
41-bit的时间可以表示(1L<<41)/(1000L*3600*24*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
这种方式的优缺点是:
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
以Mongdb objectID为例:
MongoDB官方文档 ObjectID可以算作是和snowflake类似方法:
为了考虑分布式,“_id”要求不同的机器都能用全局唯一的同种方法方便的生成它。因此不能使用自增主键(需要多台服务器进行同步,既费时又费力),
因此选用了生成ObjectId对象的方法。
ObjectId使用12字节的存储空间,其生成方式如下:
|0|1|2|3|4|5|6 |7|8|9|10|11|
|时间戳 |机器ID|PID|计数器 |
前四个字节时间戳是从标准纪元开始的时间戳,单位为秒,有如下特性:
1 时间戳与后边5个字节一块,保证秒级别的唯一性;
2 保证插入顺序大致按时间排序;
3 隐含了文档创建时间;
4 时间戳的实际值并不重要,不需要对服务器之间的时间进行同步(因为加上机器ID和进程ID已保证此值唯一,唯一性是ObjectId的最终诉求)。
机器ID是服务器主机标识,通常是机器主机名的散列值。
同一台机器上可以运行多个mongod实例,因此也需要加入进程标识符PID。
前9个字节保证了同一秒钟不同机器不同进程产生的ObjectId的唯一性。后三个字节是一个自动增加的计数器(一个mongod进程需要一个全局的计数器),保证同一秒的ObjectId是唯一的。同一秒钟最多允许每个进程拥有(256^3 = 16777216)个不同的ObjectId。
总结一下:时间戳保证秒级唯一,机器ID保证设计时考虑分布式,避免时钟同步,PID保证同一台服务器运行多个mongod实例时的唯一性,最后的计数器保证同一秒内的唯一性(选用几个字节既要考虑存储的经济性,也要考虑并发性能的上限)。
"_id"既可以在服务器端生成也可以在客户端生成,在客户端生成可以降低服务器端的压力。
3,使用Redis来生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
这个,随便负载到哪个机确定好,未来很难做修改。但是3-5台服务器基本能够满足器上,都可以获得不同的ID。但是步长和初始值一定需要事先需要了。使用Redis集群也可以方式单点故障的问题。
另外,比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量比较大。
参考:https://tech.meituan.com/MT_Leaf.html
基于数据库构建分布式的ID生成方案的更多相关文章
- 【系统设计】分布式唯一ID生成方案总结
目录 分布式系统中唯一ID生成方案 1. 唯一ID简介 2. 全局ID常见生成方案 2.1 UUID生成 2.2 数据库生成 2.3 Redis生成 2.4 利用zookeeper生成 2.5 雪花算 ...
- 分布式唯一ID生成方案是什么样的?(转)
一.前言 分布式系统中我们会对一些数据量大的业务进行分拆,如:用户表,订单表.因为数据量巨大一张表无法承接,就会对其进行分库分表. 但一旦涉及到分库分表,就会引申出分布式系统中唯一主键ID的生成问题, ...
- 一线大厂的分布式唯一ID生成方案是什么样的?
本人免费整理了Java高级资料,涵盖了Java.Redis.MongoDB.MySQL.Zookeeper.Spring Cloud.Dubbo高并发分布式等教程,一共30G,需要自己领取.传送门:h ...
- 分布式全局ID生成方案
传统的单体架构的时候,我们基本是单库然后业务单表的结构.每个业务表的ID一般我们都是从1增,通过AUTO_INCREMENT=1设置自增起始值,但是在分布式服务架构模式下分库分表的设计,使得多个库或多 ...
- 分布式唯一ID生成方案选型!详细解析雪花算法Snowflake
分布式唯一ID 使用RocketMQ时,需要使用到分布式唯一ID 消息可能会发生重复,所以要在消费端做幂等性,为了达到业务的幂等性,生产者必须要有一个唯一ID, 需要满足以下条件: 同一业务场景要全局 ...
- Java分布式唯一ID生成方案——比UUID效率更高的生成id工具类
package com.xinyartech.erp.core.util; import java.lang.management.ManagementFactory; import java.net ...
- 一种基于Orleans的分布式Id生成方案
基于Orleans的分布式Id生成方案,因Orleans的单实例.单线程模型,让这种实现变的简单,贴出一种实现,欢迎大家提出意见 public interface ISequenceNoGenerat ...
- 分布式id生成方案总结
本文已经收录自 JavaGuide (60k+ Star[Java学习+面试指南] 一份涵盖大部分Java程序员所需要掌握的核心知识.) 本文授权转载自:https://juejin.im/post/ ...
- 分布式ID生成方案汇总
1.目标 1.1.全局唯一 不能出现重复的ID,全局唯一是最基本的要求. 1.2.趋势有序 业务上分页查询需求,排序需求,如果ID直接有序,则不必建立更多的索引,增加查询条件. 而且Mysql Inn ...
随机推荐
- python反编译chm文件并生成pdf文件
# -*- coding: utf-8 -*- import os import os.path import logging import pdfkit original_chm = r'C:\Us ...
- Python实现支付宝当面付之——扫码支付
转载请注明原文地址:http://www.cnblogs.com/ygj0930/p/7680348.html 一:配置信息准备 登录蚂蚁金服开放平台:https://open.alipay.com/ ...
- 【leetcode】solution in java——Easy3
转载请注明原文地址:http://www.cnblogs.com/ygj0930/p/6412505.html 心得:看到一道题,优先往栈,队列,map,list这些工具的使用上面想.不要来去都是暴搜 ...
- SQL Server 默认跟踪(Default Trace)获取某个Trace跟踪了哪些Event和column
检查Default Trace是否已经开启,如果返回Figure1中value为1,那就说明已经开启默认跟踪了:如果value为0表示关闭默认跟踪: --查询Default Trace是否开启 ; 如 ...
- 【FinancialKnowledge】商业银行业务知识
商业银行业务思维导图 一.资产业务 资产业务是商业银行的主要收入来源 1.放款业务 1.1 信用放款 信用放款,是单凭借款人的信誉, 不需要提供任何抵押品的放款,是一种资本放款. 1.1.1 普通借款 ...
- SUMIF
SUMIF(range,criteria,sum_range) Range:条件区域,用于条件判断的单元格区域. Criteria:求和条件,由数字.逻辑表达式等组成的判定条件.criteria 参数 ...
- 转 php简单伪静态实例
mod_rewrite是Apache的一个非常强大的功能,它可以实现伪静态页面.下面我详细说说它的使用方法!对初学者很有用的哦! 1.检测Apache是否支持mod_rewrite 通过php提供的p ...
- Eureka客户端网卡和网段选择
当机器上有多个网卡或者机器上配置了回环地址的时候,Eureka客户端呈报给服务端的IP将不可预见,为了指定IP我们需要增加以下配置: 在bootstrap.yml中增加配置内容: spring: cl ...
- 删数问题(NOI94)
删数问题(NOI94) 输入一个高精度的正整数N,去掉其中任意S个数字后剩下的数字按原左右次序组成一个新的正整数.编程对给定的N和S,寻找一种方案使得剩下的数字组成的新数最小.输出新的正整数.(N不超 ...
- gnu screen的用法
在使用ssh或者telnet登录远程主机后执行一些耗时的命令, 如果此时ssh或者telnet中断, 那么远程主机上正在执行的程序或者说命令也会被迫终止. screen能够很好地解决这个问题, scr ...