第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
css选择器
1、

2、
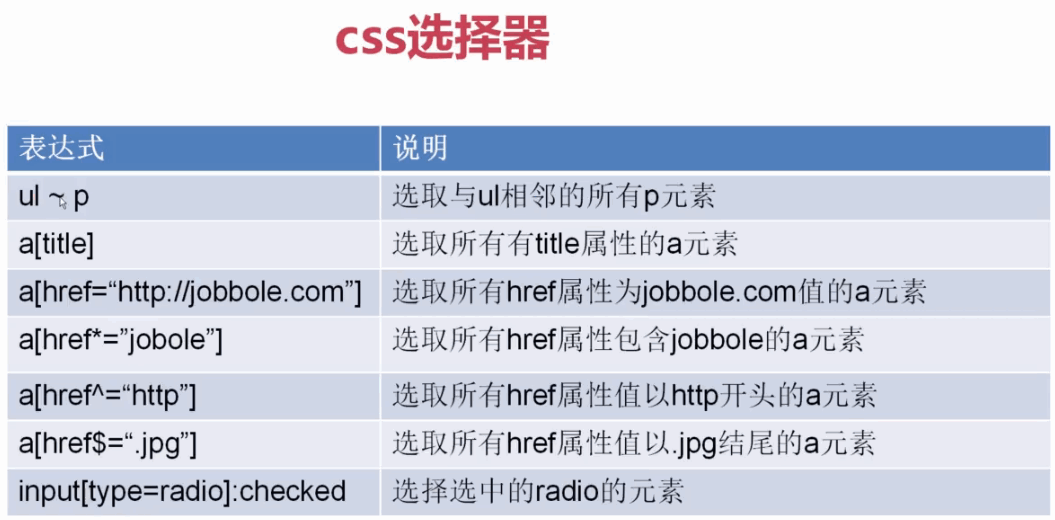
3、
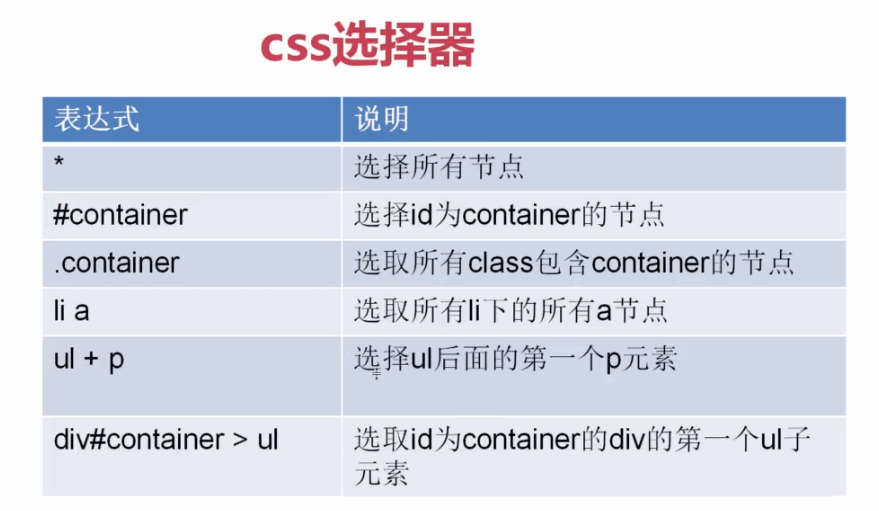
::attr()获取元素属性,css选择器
::text获取标签文本
举例:
extract_first('')获取过滤后的数据,返回字符串,有一个默认参数,也就是如果没有数据默认是什么,一般我们设置为空字符串
extract()获取过滤后的数据,返回字符串列表
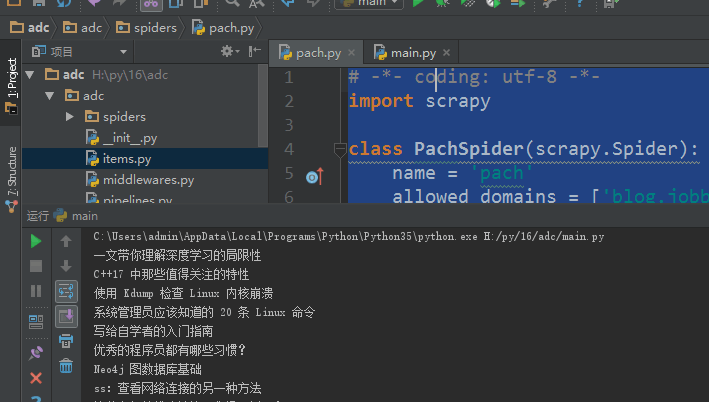
# -*- coding: utf-8 -*-
import scrapy class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): asd = response.css('.archive-title::text').extract() #这里也可以用extract_first('')获取返回字符串
# print(asd) for i in asd:
print(i)
第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器的更多相关文章
- 十九 Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
css选择器 1. 2. 3. ::attr()获取元素属性,css选择器 ::text获取标签文本 举例: extract_first('')获取过滤后的数据,返回字符串,有一个默认参数,也就是如 ...
- 第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存
第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存 注意:数据保存的操作都是在pipelines.py文件里操作的 将数据保存为json文件 spider是一个信号检测 ...
- 三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块 scrapy-redis的依赖 Python 2.7, 3.4 or 3.5,Python支持版本 Redis & ...
- 三十五 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 四十四 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1.elasticsearch(搜索引擎)的查询 elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据 查询分类: 基本查询:使用elasticsearch内 ...
- 三十二 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的URL不在爬取 实现暂停与重启记录状态 1.首先cd进入到scrapy项目里 2.在scrapy项 ...
- 三十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
- 三十四 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
信号一般使用信号分发器dispatcher.connect(),来设置信号,和信号触发函数,当捕获到信号时执行一个函数 dispatcher.connect()信号分发器,第一个参数信号触发函数,第二 ...
- 三十九 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点:一个节点是集群中的一个服务器,由一个名字来标识,默认是一个随机的漫微角色的名字 3.分片:将索引(相当于数据库)划 ...
随机推荐
- (原创)sqlite封装库SmartDB1.3发布
最近终于稍微有点空对SmartDB进行升级了,SmartDB1.3比之前的版本做了简化,增强了易用性和灵活性. SmartDB对sqlite做了一层封装,屏蔽了诸多细节,使得我们使用起来很方便.在注重 ...
- 每日英语:Patent Wars Erupt Again in Tech Sector
The long-running patent war among the technology industry's heavyweights just grew a whole lot bigge ...
- C# IOCP服务器项目(学习)
无论什么平台,编写支持高并发性的网络服务器,瓶颈往往出在I/O上,目前最高效的是采用Asynchronous I/O模型,Linux平台提供了epoll,Windows平台提供了I/O Complet ...
- C#学习笔记(29)——Linq的实现,Lambda求偶数和水仙花数
说明(2017-11-22 18:15:48): 1. Lambda表达式里面用了匿名委托,感觉理解起来还是挺难的.求偶数的例子模拟了Linq查询里的一个where方法. 2. 蒋坤说求水仙花数那个例 ...
- 基于9款CSS3鼠标悬停相册预览特效
基于9款CSS3鼠标悬停相册预览特效里面包含九款不同方式的相册展开特效代码.效果图如下: 在线预览 源码下载 实现的代码. html代码: <div class="albums&q ...
- 分布式唯一id生成器的想法
0x01 起因 前端时间遇到一个问题,怎么快速生成唯一的id,后来采用了hashid的方法.最近在网上读到了美团关于分布式唯一id生成器的解决方案, 其中提到了三种生成法:(建议看一下这篇文章,写得很 ...
- DeepNLP的核心关键/NLP词的表示方法类型/NLP语言模型 /词的分布式表示/word embedding/word2vec
DeepNLP的核心关键/NLP语言模型 /word embedding/word2vec Indexing: 〇.序 一.DeepNLP的核心关键:语言表示(Representation) 二.NL ...
- C语言 · 征税程序
算法提高 征税程序 时间限制:1.0s 内存限制:512.0MB 问题描述 税务局希望你帮他们编写一个征税程序,该程序的功能是:首先输入某公司的年销售额sale和税率rate,然后程 ...
- [看门狗]基于Linux的嵌入式系统全程喂狗策略
转自:http://blog.csdn.net/erickhuang1989/article/details/8721548 在嵌入式系统中,为了使系统在异常情况下能自动恢复,一般都会引入看门狗电路. ...
- Go Revel - Filters(过滤器链)
`Fitlers`过滤器链是一个中间件,它们具有单独的功能,并作为管道对请求做链式处理.过滤器链执行框架的所有功能. 对过滤器链的源码分析,请移步 Go Revel - Filter(过滤器)源码分析 ...