python 使用selenium和requests爬取页面数据
目的:获取某网站某用户下市场大于1000秒的视频信息
1.本想通过接口获得结果,但是使用post发送信息到接口,提示服务端错误。
2.通过requests获取页面结果,使用html解析工具,发现麻烦而且得不到想要的结果
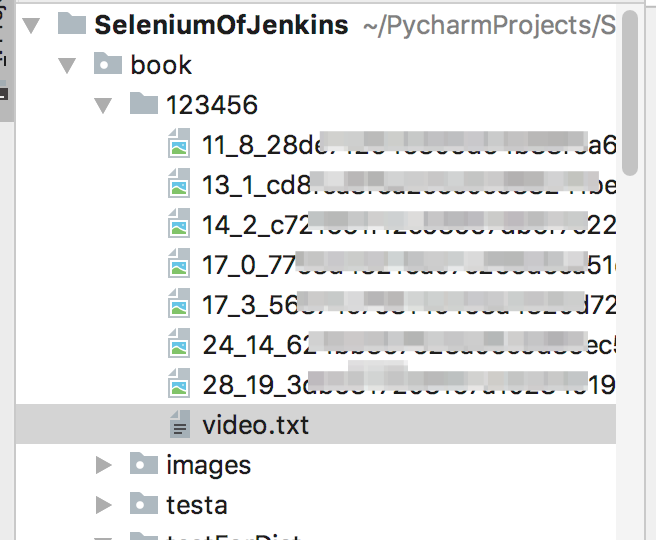
3.直接通过selenium获取控件的属性信息,如图片、视频地址,再对时间进行筛选。将信息保存到以id命名的文件夹下
# -*- coding:utf-8 -*-
from selenium import webdriver
import sys,os,requests,shutil
class GetUserVideo():
def __init__(self,driver,id):
self.id = str(id)
self.driver = driver
self.base_url = "http://www.xxxxx.com/user/%s?t=2"%(self.id)
def get_pagecounts(self):
#获取页面数
self.driver.get(self.base_url)
page_counts=int(self.driver.find_elements_by_xpath("//div[@class='page']/a")[-2].text)+1
return page_counts
def get_video(self,driver,page,f):
video_times = driver.find_elements_by_xpath("//i[@class='continue_time']")
video_urls = driver.find_elements_by_xpath("//div[@class='video']/a[@class='url']")
video_imgs = driver.find_elements_by_xpath("//a[@class='url']/img")
length = len(video_times)
for i in range(length):
" 当前页面内筛选出时长大于1000秒的,并将图片、时长、地址保存到指定目录"
time_list = video_times[i].text.split(":")
time_count = int(time_list[0]) * 3600 + int(time_list[1]) * 60 + int(time_list[2])
if time_count > 1000:
video_time = video_times[i].text
video_url = video_urls[i].get_attribute('href')
video_img = video_imgs[i].get_attribute("src")
img_name = str(page) + "_" + str(i)+"_"+os.path.basename(video_img)
f.write(img_name + "\t")
f.write(video_time + "\t")
f.write(video_url + "\n")
img_url = requests.get(video_img)
with open(self.id + "/" + img_name, "wb") as b:
b.write(img_url.content)
def test(self):
"如果存在同名文件夹,就删除"
if os.path.exists(self.id):
shutil.rmtree(self.id)
os.mkdir(self.id)
driver = self.driver
page_counts=self.get_pagecounts()
f=open(self.id+"/video.txt","w")
for page in range(1,page_counts):
detail_url = "&page=%s" % page
driver.get(self.base_url+detail_url)
self.get_video(driver,page,f)
f.close()
driver.quit()
if __name__=="__main__":
path = sys.path[0].split("/")
index = path.index("SeleniumOfJenkins") + 1
ph_driver = "/driver/phantomjs-2.1.1-macosx/bin/phantomjs"
if index == len(path):
driver_path = sys.path[0] + ph_driver
else:
driver_path = "/".join(path[:index]) + ph_driver
driver = webdriver.PhantomJS(executable_path=driver_path)
driver.maximize_window()
driver.implicitly_wait(10)
test = GetUserVideo(driver,123456)
test.test()

python 使用selenium和requests爬取页面数据的更多相关文章
- Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的 使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据 爬虫工具 使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文 ...
- python 爬虫之requests爬取页面图片的url,并将图片下载到本地
大家好我叫hardy 需求:爬取某个页面,并把该页面的图片下载到本地 思考: img标签一个有多少种类型的src值?四种:1.以http开头的网络链接.2.以“//”开头网络地址.3.以“/”开头绝对 ...
- python(27)requests 爬取网页乱码,解决方法
最近遇到爬取网页乱码的情况,找了好久找到了种解决的办法: html = requests.get(url,headers = head) html.apparent_encoding html.enc ...
- python+requests抓取页面图片
前言: 学完requests库后,想到可以利用python+requests爬取页面图片,想到实战一下.依照现在所学只能爬取图片在html页面的而不能爬取由JavaScript生成的图片,所以我选取饿 ...
- [实战演练]python3使用requests模块爬取页面内容
本文摘要: 1.安装pip 2.安装requests模块 3.安装beautifulsoup4 4.requests模块浅析 + 发送请求 + 传递URL参数 + 响应内容 + 获取网页编码 + 获取 ...
- scrapy中使用selenium来爬取页面
scrapy中使用selenium来爬取页面 from selenium import webdriver from scrapy.http.response.html import HtmlResp ...
- 爬虫-----selenium模块自动爬取网页资源
selenium介绍与使用 1 selenium介绍 什么是selenium?selenium是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作. sel ...
- 一个月入门Python爬虫,轻松爬取大规模数据
Python爬虫为什么受欢迎 如果你仔细观察,就不难发现,懂爬虫.学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得 ...
- Python3 Scrapy + Selenium + 阿布云爬取拉钩网学习笔记
1 需求分析 想要一个能爬取拉钩网职位详情页的爬虫,来获取详情页内的公司名称.职位名称.薪资待遇.学历要求.岗位需求等信息.该爬虫能够通过配置搜索职位关键字和搜索城市来爬取不同城市的不同职位详情信息, ...
随机推荐
- java 缓冲区大小与下载速度的关系
1.对于缓冲区空间的设定,要根据具体情况来定,如果存在大量的长信息(比如文件传输),将缓冲区定义的大些,可能更好的利用网络资源,如果更多的是短信息(比如聊天消息),使用小的缓冲区可能更好些,这样刷新的 ...
- python3.6 django2.06 使用QQ邮箱发送邮件
开通QQ邮箱IMAP/SMTP服务,忘记了,重新开通一下,记住密码串. import smtplib from email.mime.text import MIMEText # 收件人列表 mail ...
- UI基础:UITextField 分类: iOS学习-UI 2015-07-01 21:07 68人阅读 评论(0) 收藏
UITextField 继承自UIControl,他是在UILabel基础上,对了文本的编辑.可以允许用户输入和编辑文本 UITextField的使用步骤 1.创建控件 UITextField *te ...
- 将Mat类型坐标数据生成pts文件
前言 获取人脸特征点的坐标信息之后,想要将坐标信息shape保存为pts/asf/txt等文件格式,本文就对此进行实现. 实现过程 1.确定pts文件的书写格式: 以要生成的文件为例,书写格式如下: ...
- [Data Structure] Linked List Implementation in Python
class Empty(Exception): pass class Linklist: class _Node: # Nonpublic class for storing a linked nod ...
- Unity 3D编辑器扩展介绍、教程(一) —— 创建菜单项
Unity编辑器扩展教程 本文提供全流程,中文翻译.Chinar坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) 一 Brief Introduct ...
- linux搜索命令之find和grep
在使用linux时,经常需要进行文件查找,其中查找的命令主要有find和grep.两个命令是有区的. 区别:(1)find命令是根据文件的属性进行查找,如文件名,文件大小,所有者,所属组,是否为空,访 ...
- HDU 6188:Duizi and Shunzi(贪心)(广西邀请赛)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6188 题意 有n个数字,每个数字小于等于n,两个相同的数字价值为1,三个连续的数字价值为1 .问这n个 ...
- CTF之ROT加解密
常见的ROT加密包括ROT5,ROT13,ROT18,ROT47 ROT5:只是对数字进行编码.用当前数字往后数的第五个数字替换当前数字: 例:123sb——>678sb ROT13:只是对字母 ...
- java反射+java泛型,封装BaseDaoUtil类。供应多个不同Dao使用
当项目是ssh框架时,每一个Action会对应一个Service和一个Dao.但是所有的Ation对应的Dao中的方法是相同的,只是要查的表不一样.由于封装的思想,为了提高代码的重用性.可以使用jav ...