Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的
使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据
爬虫工具
使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文档对象,并提取职位信息。
爬取过程
1.请求地址
https://www.lagou.com/zhaopin/Python/
2.需要爬取的内容
(1)岗位名称
(2)薪资
(3)公司所在地
3.查看html
使用FireFox浏览器,登陆拉勾网,按F12可以进入开发者工具页面:
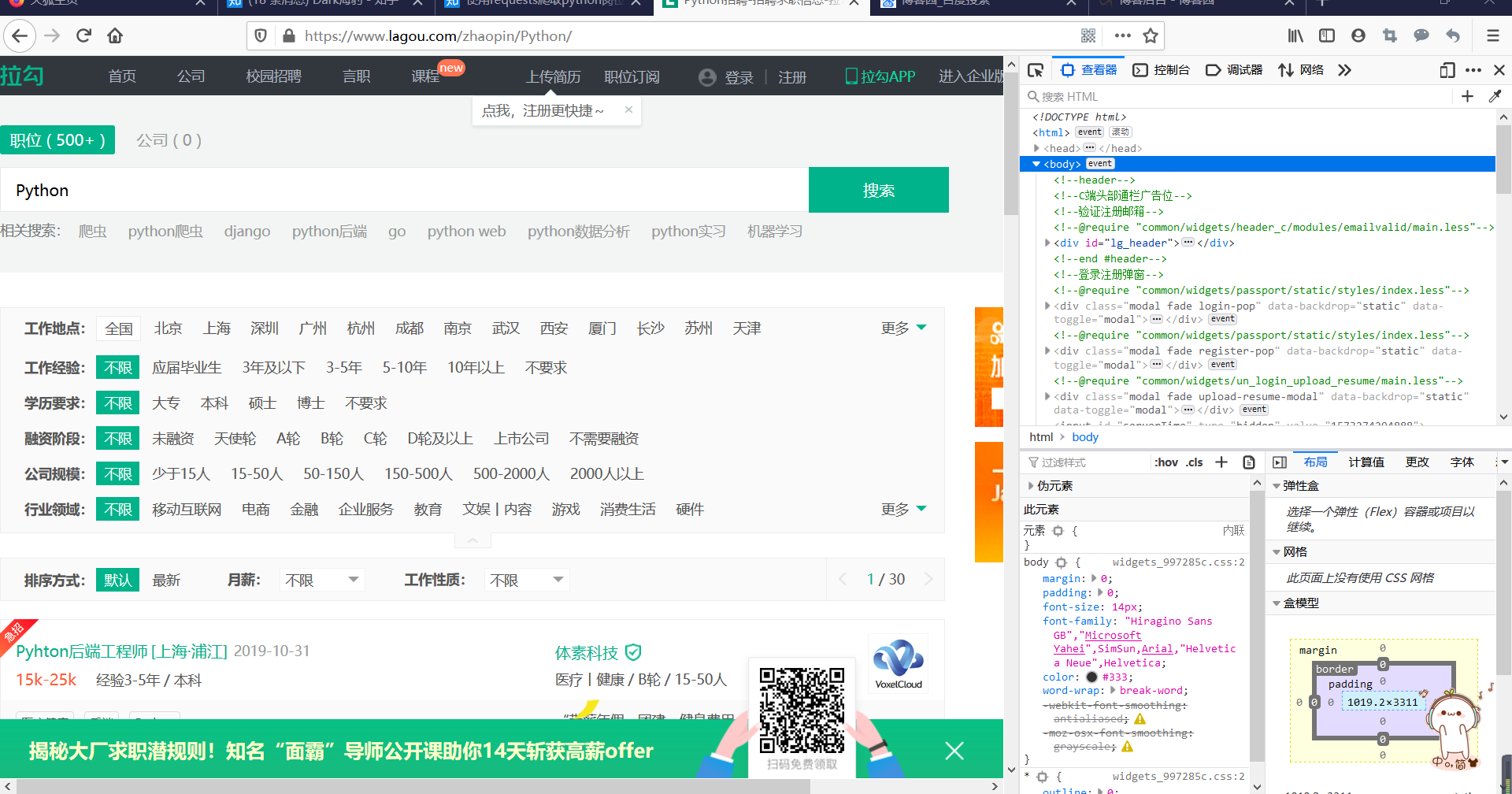
这时候会看到该页面的html网页源码。
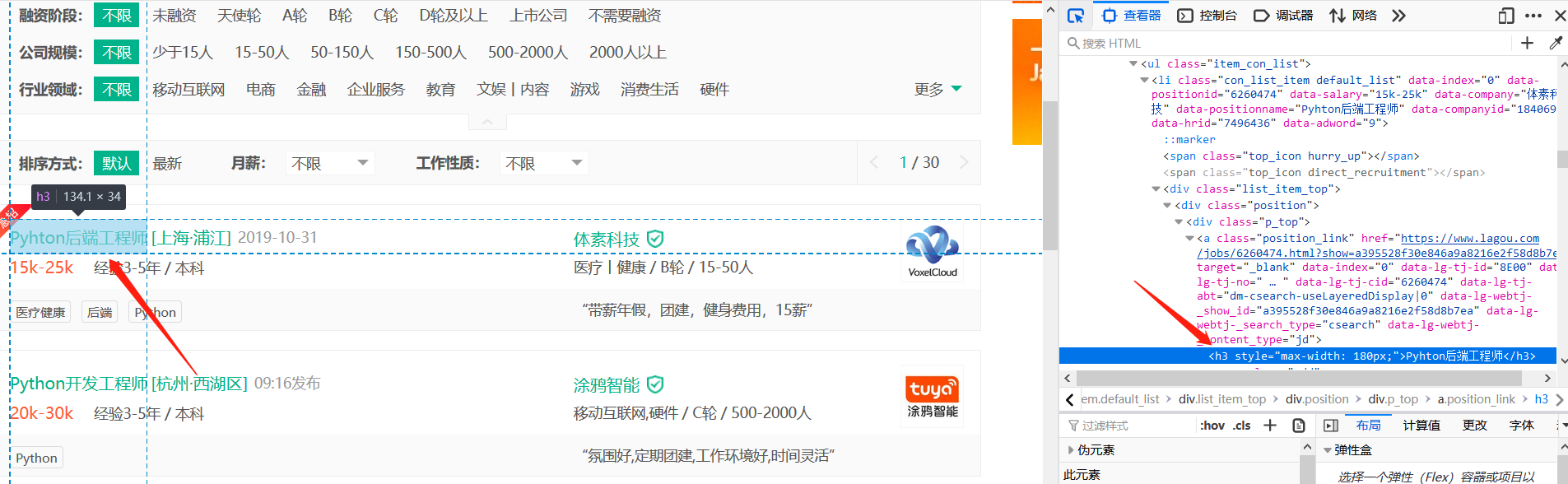
接下来需要寻找岗位信息对应的源码,比如岗位名称:

在开发者工具页面左上角有个箭头标志,点击它,然后再点击岗位名称,就能看到对应的源码。
知道对应的源码后,还需要知道请求头:
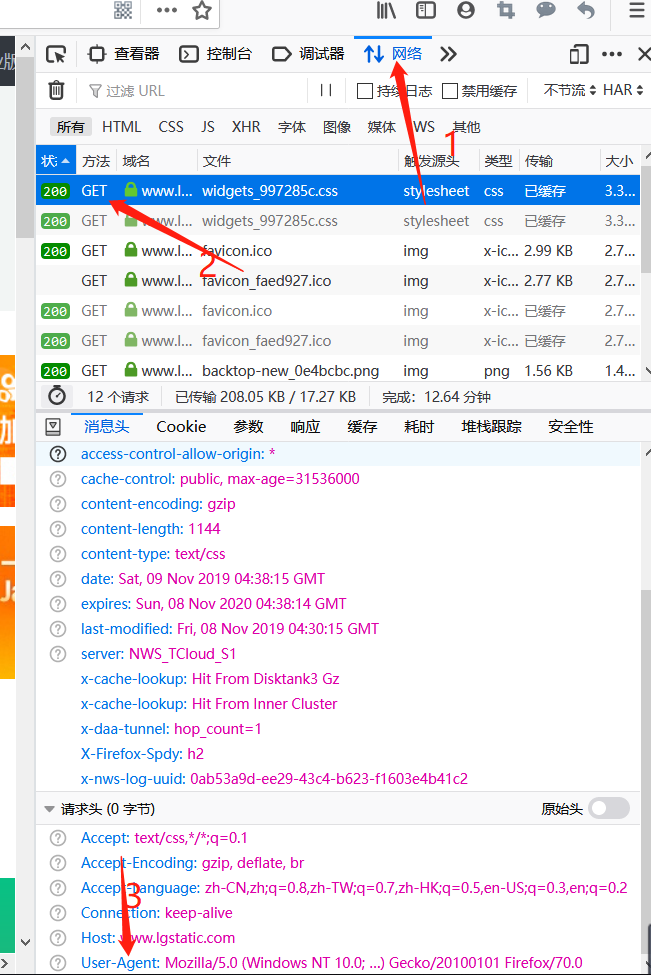
点击“网络”,之后点击“get”,在最下方User-Agent中的内容就是请求头
(如果是使用Chrome浏览器或者其它浏览器方法会有所不同)
完成上述操作后就可以利用BeautifulSoup4提取里面的文本。
利用requests发出数据请求
import requests
import io
import sys
from bs4 import BeautifulSoup
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36',}
r = requests.get('https://www.lagou.com/zhaopin/Python/',headers=headers) #设置请求头
r.encoding=r.apparent_encoding
result=r.text
bs=BeautifulSoup(result,'html.parser') #创建一个BeautifulSoup对象
利用BeautifulSoup提取网页数据
b=[] #创建空列表用来存储爬取的数据
a=[]
d=[]
name = bs.find_all('h3') #获取所有包含'h3'标签的内容
’
for h3 in name:
b.append(h3.string)
money = bs.find_all('span',attrs={'class':'money'})
for span in money:
a.append(span.string) #获取字符串形式的数据
ltd=bs.find_all('em')
for em in ltd:
d.append(em.string)
i=0
print("职业:"," 薪资:"," 地点:")
try:
while True:
print(b[i],a[i],d[i])
i+=1
except IndexError:
print()
Python爬虫入门——使用requests爬取python岗位招聘数据的更多相关文章
- Python爬虫入门教程 42-100 爬取儿歌多多APP数据-手机APP爬虫部分
1. 儿歌多多APP简单分析 今天是手机APP数据爬取的第一篇案例博客,我找到了一个儿歌多多APP,没有加固,没有加壳,没有加密参数,对新手来说,比较友好,咱就拿它练练手,熟悉一下Fiddler和夜神 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- python爬虫入门10分钟爬取一个网站
一.基础入门 1.1什么是爬虫 爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序. 从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HT ...
- Python 爬虫入门实例(爬取小米应用商店的top应用apk)
一,爬虫是什么? 爬虫就是获取网络上各种资源,数据的一种工具.具体的可以自行百度. 二,如何写简单爬虫 1,获取网页内容 可以通过 Python(3.x) 自带的 urllib,来实现网页内容的下载. ...
- Python爬虫之简单的爬取百度贴吧数据
首先要使用的第类库有 urllib下的request 以及urllib下的parse 以及 time包 random包 之后我们定义一个名叫BaiduSpider类用来爬取信息 属性有 url: ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
随机推荐
- 本地win下JConsole监控远程linux下的JVM
环境:服务器端: Linux + jdk1.7.0_75 + tomcat 7本地: Win + jdk1.7.0_55 一.修改/etc/hosts文件 hostname -i 如果显示127.0. ...
- [Linux]Ubuntu设置时区和更新时间
Ubuntu 下执行 date -R 查看现在时区 执行 tzselect查看时区,注意这个命令只能查询不能真正的修改时区 执行下面命令,复制文件到 /etc/可修改时区 sudo cp /usr/s ...
- 重置 Macbook 登录密码
1.按 开机键 的同时 按 Command + R,等进度条走完,会出现如下图 2.在菜单栏,选取“实用工具”>“终端”. 3.在终端窗口,键入下面的命令:resetpassword 按下回车键 ...
- css3响应式布局教程—css3响应式
响应式布局 一个网站能够兼容多个终端,并且在各个终端都可以很好展示体验. 媒体类型 在何种设备或者软件上将页面打开 123456789 all:所有媒体braille:盲文触觉设备embossed:盲 ...
- HTTP: Request中的post和get区别
* GET和POST之间的主要区别 1.GET是从服务器上获取数据,POST是向服务器传送数据. 2.在客户端, get是把参数数据队列加到提交表单的ACTION属性所指的URL中,值和表单内各个字段 ...
- xorm-删除和软删除实例
删除数据Delete方法,参数为struct的指针并且成为查询条件.注意:当删除时,如果user中包含有bool,float64或者float32类型,有可能会使删除失败 package main i ...
- coco2dx--Permission denied
在终端输入./cocos.py....创建项目时,出现Permission denied,是权限问题,可以先使用chmod命令获得权限,输入chmod u+x ./cocos.py 回车,接着再使用c ...
- ubuntu 安装harbor仓库
一.介绍 Harbor,是一个英文单词,意思是港湾,港湾是干什么的呢,就是停放货物的,而货物呢,是装在集装箱中的,说到集装箱,就不得不提到Docker容器,因为docker容器的技术正是借鉴了集装箱的 ...
- Gradle 翻译 tips and recipes 使用技巧 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- Java11新特性 - 标准Java异步HTTP客户端
Java9开始引入的一个处理 HTTP 请求的的 HTTP Client API,该 API 支持同步和异步,而在 Java 11 中已经为正式可用状态,你可以在 java.net 包中找到这个 AP ...