Hadoop学习笔记(1):WordCount程序的实现与总结
开篇语:
这几天开始学习Hadoop,花费了整整一天终于把伪分布式给搭好了,激动之情无法言表······
搭好环境之后,按着书本的代码,实现了这个被誉为Hadoop中的HelloWorld的程序--WordCount,以此开启学习Hadoop的篇章。
本篇旨在总结WordCount程序的基本结构和工作原理,有关环境的搭建这块,网上有很多的教程,大家可以自行找谷歌或百度。
何为MapReduce:
在开始看WordCount的代码之前,先简要了解下什么是MapReduce。HDFS和MapReduce是Hadoop的两个重要核心,其中MR是Hadoop的分布式计算模型。MapReduce主要分为两步Map步和Reduce步,引用网上流传很广的一个故事来解释,现在你要统计一个图书馆里面有多少本书,为了完成这个任务,你可以指派小明去统计书架1,指派小红去统计书架2,这个指派的过程就是Map步,最后,每个人统计完属于自己负责的书架后,再对每个人的结果进行累加统计,这个过程就是Reduce步。
WordCount程序:
程序的功能:假设现在有n个文本,WordCount程序就是利用MR计算模型来统计这n个文本中每个单词出现的总次数。
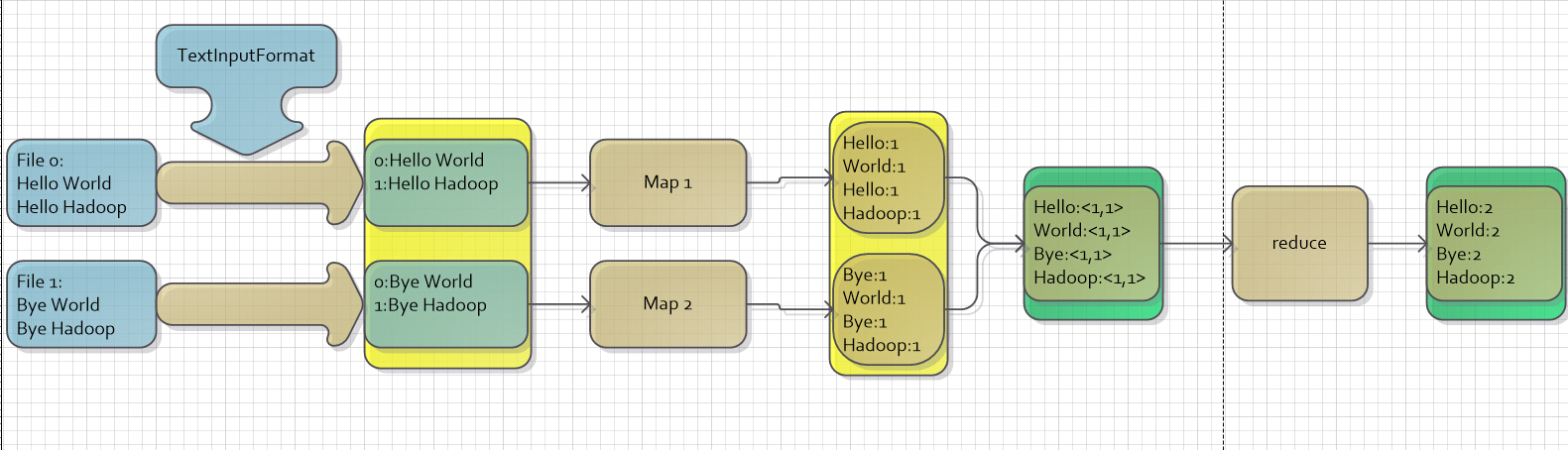
图一
现在有两个文件:
- File 0:有两行,第一行的内容为“Hello World”,第二行的内容为“Hello Hadoop”
- File 1:有两行,第一行的内容为“Bye World”,第二行的内容为“Bye Hadoop”
假设我们现在要统计这两个文件每种单词出现的次数,首先我们要对每个文本进行处理,即把其中的句子划分成词语,按照上面讲到的统计图书的故事,我们会将这两个文件分派给两个人,让这两个人各自去处理,待这两个人都处理完成之后,再对结果进行汇总统计,在图中充当这两个人角色的就是Map1和Map2,Map步的输入为<key,value>对,输出也为<key,value>对,实现Map步的代码如下:

1 // 继承Mapper类,Mapper类的四个泛型参数分别为:输入key类型,输入value类型,输出key类型,输出value类型
2 public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
3
4 private final static IntWritable one = new IntWritable(1); //输出的value的类型,可以理解为int
5 private Text word = new Text(); //输出的key的类型,可以理解为String
6
7 @Override
8 public void map(LongWritable key, Text value, Context context)
9 throws IOException, InterruptedException {
10
11 String line = value.toString(); //每行句子
12 StringTokenizer tokenizer = new StringTokenizer(line);
13
14 while (tokenizer.hasMoreTokens()) {
15 word.set(tokenizer.nextToken());
16 context.write(word, one); //输出
17 }
18
19 }
20 }
现在来分析和解读一下代码中的Map步:
- 首先,要实现Map步,应该实现一个类,这个类继承了Mapper类并且重写其中的map方法。
- 现在来说下重写这个map方法有什么意义。继续拿统计图书的例子来说,当小明被指派到书架1统计图书的时候,小明可以偷懒,对于那些他不想统计的书,他可以不统计;小明也可以很尽责,统计的结果达到百分百准确。总而言之,小明只要拿出统计结果给负责汇总的人就可以了,至于他是怎么处理的,负责汇总的人管不着。而重写这个map方法,就对应于实现这个处理的过程,负责将输入的<key,value>对进行处理统计,并且输出<key,value>对给下一步处理。这部分代码参见图二中的第一个黄色框(Map步的输入)和第二个黄色框(Map步的输出)。
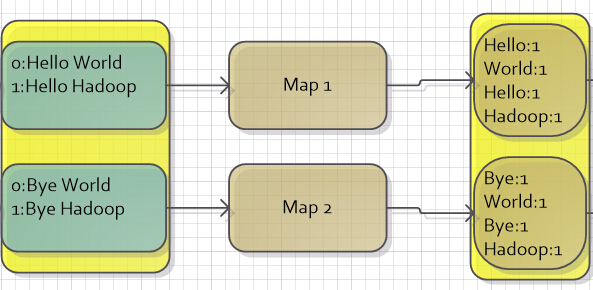
图二
WordCount程序中的Map步的输出结果为<单词,1>对,在这里有一个合并处理步骤,将拥有相同key值的键值对进行合并,形成一个<key,valuelist>,这个<key,valuelist>的键值对集合,作为Reduce步的输入。现在来看一下实现Reduce步的代码:
1 // Reduce类,继承了Reducer类
2 public static class Reduce extends
3 Reducer<Text, IntWritable, Text, IntWritable> {
4
5 @Override
6 //在这里,reduce步的输入相当于<单词,valuelist>,如<Hello,<1,1>>
7 public void reduce(Text key, Iterable<IntWritable> values,
8 Context context) throws IOException, InterruptedException {
9 int sum = 0;
10 for (IntWritable val : values) {
11 sum += val.get();
12 }
13 context.write(key, new IntWritable(sum));
14 }
15 }
现在来分析和解读一下代码中的Reduce步:
- 要实现Reduce步,应该实现一个类,这个类继承了Reducer类并且重写其中的reduce方法。
- 这个Reduce步就相当于在统计图书中那个汇总统计的人,负责对手下的工作结果进行汇总,Reduce步的输入和输出同样为<key,value>。这部分代码参见图三中的第一个绿色框(Reduce步的输入)和第二个绿色框(Reduce步的输出)。

图三
最后再来看一下主函数吧,在Hadoop中,每个MapReduce任务被当做一个Job(作业),在执行任务之前,首先要对任务进行一些配置,代码如下:
1 Job job = new Job(); // 创建一个作业对象
2 job.setJarByClass(WordCount.class); // 设置运行/处理该作业的类
3 job.setJobName("WordCount");
4
5 FileInputFormat.addInputPath(job, new Path(args[0]));//设置这个作业输入数据的路径
6 FileOutputFormat.setOutputPath(job, new Path(args[1]));//设置这个作业输出结果的路径
7
8 job.setMapperClass(Map.class);//设置实现了Map步的类
9 job.setReducerClass(Reduce.class);//设置实现了Reduce步的类
10
11 job.setOutputKeyClass(Text.class);//设置输出结果key的类型
12 job.setOutputValueClass(IntWritable.class);//设置输出结果value的类型
13
14 System.exit(job.waitForCompletion(true) ? 0 : 1);//执行作业
来看一下Job设置了哪些东西:
- 设置处理该作业的类,setJarByClass()
- 设置这个作业的名字,setJobName()
- 设置这个作业输入数据所在的路径
- 设置这个作业输出结果保存的路径
- 设置实现了Map步的类,setMapperClass()
- 设置实现了Reduce步的类,setReducerClass()
- 设置输出结果key的类型,setOutputKeyClass()
- 设置输出结果value的类型,setOuputValueClass()
- 执行作业
倒回看图一,会发现还有一个如图四的东西:

图四
那么图四中的这个TextInputFormat又是干吗的呢?
TextInputFormat是Hadoop默认的输入方法,在TextInputFormat中,每个文件(或其一部分)都会单独作为Map的输入,之后,每一行数据都会产生一个<key,value>形式:其中key值是每个数据的记录在数据分片中的字节偏移量,而value值是每行的内容。所以,图5中画红圈的两个数据应该是有误的(在上面只是为了方便表示),正确的值应该是第二行第一个字符的偏移量才对。
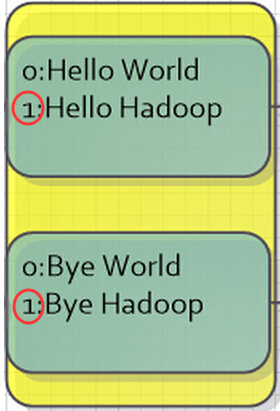
图五
学习资料:
陆嘉恒,《Hadoop实战》,机械工业出版社。
最后附上完整源代码:
1 import java.io.IOException;
2 import java.util.StringTokenizer;
3
4 import org.apache.hadoop.conf.Configuration;
5 import org.apache.hadoop.fs.Path;
6 import org.apache.hadoop.io.IntWritable;
7 import org.apache.hadoop.io.LongWritable;
8 import org.apache.hadoop.io.Text;
9 import org.apache.hadoop.mapreduce.Job;
10 import org.apache.hadoop.mapreduce.Mapper;
11 import org.apache.hadoop.mapreduce.Reducer;
12 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
13 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
15 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
16 import org.apache.hadoop.util.GenericOptionsParser;
17 import org.apache.hadoop.mapreduce.Reducer.Context;
18
19 public class WordCount {
20
21 // 继承Mapper类,Mapper类的四个泛型参数分别为:输入key类型,输入value类型,输出key类型,输出value类型
22 public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
23
24 private final static IntWritable one = new IntWritable(1); // output value
25 private Text word = new Text(); // output key
26
27 @Override
28 public void map(LongWritable key, Text value, Context context)
29 throws IOException, InterruptedException {
30
31 String line = value.toString();
32 StringTokenizer tokenizer = new StringTokenizer(line);
33
34 while (tokenizer.hasMoreTokens()) {
35 word.set(tokenizer.nextToken());
36 context.write(word, one);
37 }
38
39 }
40 }
41
42 // Reduce类,继承了Reducer类
43 public static class Reduce extends
44 Reducer<Text, IntWritable, Text, IntWritable> {
45
46 @Override
47 public void reduce(Text key, Iterable<IntWritable> values,
48 Context context) throws IOException, InterruptedException {
49 int sum = 0;
50 for (IntWritable val : values) {
51 sum += val.get();
52 }
53 context.write(key, new IntWritable(sum));
54 }
55 }
56
57 public static void main(String[] args) throws Exception {
58
59 if (args.length != 2) {
60 System.err
61 .println("Usage: MaxTemperature <input path> <output path>");
62 System.exit(-1);
63 }
64
65 Job job = new Job(); // 创建一个作业对象
66 job.setJarByClass(WordCount.class); // 设置运行/处理该作业的类
67 job.setJobName("WordCount");
68
69 FileInputFormat.addInputPath(job, new Path(args[0]));
70 FileOutputFormat.setOutputPath(job, new Path(args[1]));
71
72 job.setMapperClass(Map.class);
73 job.setReducerClass(Reduce.class);
74
75 job.setOutputKeyClass(Text.class);
76 job.setOutputValueClass(IntWritable.class);
77
78 System.exit(job.waitForCompletion(true) ? 0 : 1);
79
80 }
81
82 }
Hadoop学习笔记(1):WordCount程序的实现与总结的更多相关文章
- [原创] hadoop学习笔记:wordcout程序实践
看了官网上的示例:但是给的不是很清楚,这里依托官网给出的示例,加上自己的实践,解析worcount程序的操作 1.首先你的确定你的集群正确安装,并且启动你的集群,应为这个是hadoop2.6.0,所以 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(1)(转)
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(4) ——搭建开发环境及编写Hello World
Hadoop学习笔记(4) ——搭建开发环境及编写Hello World 整个Hadoop是基于Java开发的,所以要开发Hadoop相应的程序就得用JAVA.在linux下开发JAVA还数eclip ...
- Hadoop环境搭建及wordcount程序
目的: 前期学习了一些机器学习基本算法,实际企业应用中算法是核心,运行的环境和数据处理的平台是基础. 手段: 搭建简易hadoop集群(由于机器限制在自己的笔记本上通过虚拟机搭建) 一.基础环境介绍 ...
随机推荐
- 【转】【WPF】WPF为stackpanel设置滚动条
<ScrollViewer x:Name="scrolls" VerticalScrollBarVisibility="Auto" HorizontalS ...
- window.location.href 跳转失败
我恨这个问题,因为困扰已久,做为一个不称职的半开发人员,对前端非常不熟,程度仅限于alert调试的水平 这个问题似乎是IE的一个傻逼哄哄的BUG引起的,在AJAX盛行的今天,当在返回success状态 ...
- vi 新建文件后保存文件时遇到的问题:E212: 无法打开并写入文件
问题描述 使用vi编辑器写好内容后保存并退出时遇到以下问题 解决方案 该问题的原因是用户权限不够,因为普通用户用 vi 不能保存文件,需要使用超级用户才可以. 先转换为超级用户:su 再用vi打开文件 ...
- zend framework分析总结[转]
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版.作者信息和本声明.否则将追究法律责任.http://blog.csdn.net/mayongzhan - 马永占,myz,may ...
- install sun-java6-jdk in ubuntu12.04
http://blog.sina.com.cn/s/blog_6296abc601018p86.html 在文件/etc/apt/sources.list 的最后添加下面的源: deb http:// ...
- RabbitMQ学习笔记(一):安装及Springboot集成
前言 MQ,即消息队列Message Queue的缩写. RabbitMQ 是MQ的一种,就像招商银行是银行的一种一样.主要是用来实现应用程序的异步和解耦,同时也能起到消息缓冲,消息分发的作用. 消息 ...
- Struts2/XWork 安全漏洞及解决办法
exploit-db网站在7月14日爆出了一个Struts2的远程执行任意代码的漏洞. 漏洞名称:Struts2/XWork < 2.2.0 Remote Command Execution V ...
- Umbraco中使用Related Links显示内部链接和外部链接
在Umbraco的论坛里看到的办法,演示了如何在Umbraco中使用Related Links并显示的过程. 原文地址:http://www.nibble.be/?p=48
- Axure实例演示—登录界面
实例演示 ——登录界面 ...
- 【LFM】隐语义模型
模型解释: http://blog.csdn.net/harryhuang1990/article/details/9924377