selenium+python自动化90-unittest多线程执行用例
前言
假设执行一条脚本(.py)用例一分钟,那么100个脚本需要100分钟,当你的用例达到一千条时需要1000分钟,也就是16个多小时。。。
那么如何并行运行多个.py的脚本,节省时间呢?这就用到多线程了,理论上开2个线程时间节省一半,开5个线程,时间就缩短五倍了。
项目结构
1.项目结构跟之前的设计是一样的:
- case test开头的.py用例脚本
- common 放公共模块,如HTMLTestRunner
- report 放生成的html报告
- run_all.py 用于执行全部脚本
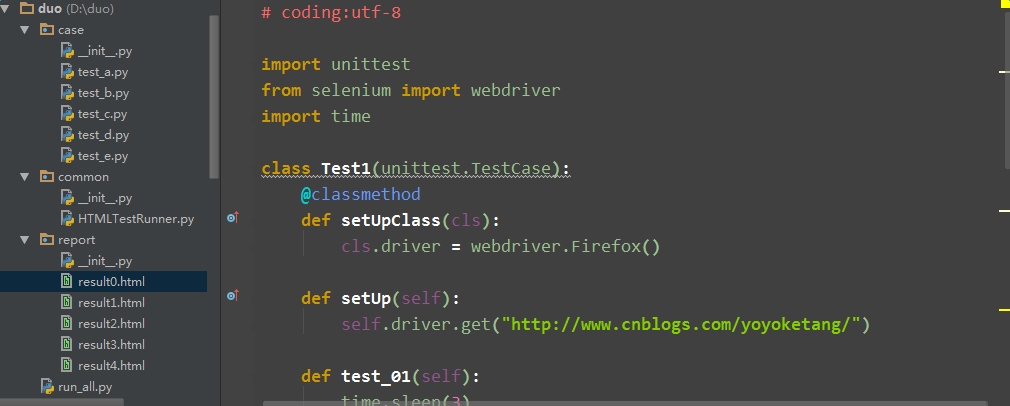
2.case文件夹里面用例参考
# coding:utf-8
import unittest
from selenium import webdriver
import time
class Test1(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Firefox()
def setUp(self):
self.driver.get("http://www.cnblogs.com/yoyoketang/")
def test_01(self):
time.sleep(3)
t = self.driver.title
print t
# 随便写的用例,没写断言
def test_02(self):
time.sleep(3)
t = self.driver.title
print t
h = self.driver.window_handles
print h
# 随便写的用例,没写断言
@classmethod
def tearDownClass(cls):
cls.driver.quit()
if __name__ == "__main__":
unittest.main()
多线程执行
1.多线程设计思路:
- 先写一个run的函数
- 保证for循环能跑的通
- 在run函数上加个装饰器 @threads(n),n是线程数
2.run_all参考代码
# coding=utf-8
import unittest
from common import HTMLTestRunner
import os
from tomorrow import threads
# python2需要这三行,python3不需要
import sys
reload(sys)
sys.setdefaultencoding('utf8')
# 获取路径
curpath = os.path.dirname(os.path.realpath(__file__))
casepath = os.path.join(curpath, "case")
reportpath = os.path.join(curpath, "report")
def add_case(case_path=casepath, rule="test*.py"):
'''加载所有的测试用例'''
discover = unittest.defaultTestLoader.discover(case_path,
pattern=rule,
top_level_dir=None)
return discover
@threads(3)
def run_case(all_case, report_path=reportpath, nth=0):
'''执行所有的用例, 并把结果写入测试报告'''
report_abspath = os.path.join(report_path, "result%s.html"%nth)
fp = open(report_abspath, "wb")
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,
title=u'自动化测试报告,测试结果如下:',
description=u'用例执行情况:')
# 调用add_case函数返回值
runner.run(all_case)
fp.close()
if __name__ == "__main__":
# 用例集合
cases = add_case()
# 之前是批量执行,这里改成for循环执行
for i, j in zip(cases, range(len(list(cases)))):
run_case(i, nth=j) # 执行用例,生成报告
3.生成报告,这里生成的报告是多个的,每个.py脚本生成一个html的报告,接下来遇到的难点就是合并报告了
如何把多个html报告合并成一个报告呢?
selenium+python自动化90-unittest多线程执行用例的更多相关文章
- unittest多线程执行用例
前言 假设执行一条脚本(.py)用例一分钟,那么100个脚本需要100分钟,当你的用例达到一千条时需要1000分钟,也就是16个多小时... 那么如何并行运行多个.py的脚本,节省时间呢?这就用到多线 ...
- selenium+python自动化98--文件下载弹窗处理(PyKeyboard)
前言 在web自动化下载操作时,有时候会弹出下载框,这种下载框不属于web的页面,是没办法去定位的(有些同学一说到点击,脑袋里面就是定位!定位!定位!) 有时候我们并不是非要去定位到这个按钮再去点击, ...
- selenium+python自动化79-文件下载(SendKeys)
前言 文件下载时候会弹出一个下载选项框,这个弹框是定位不到的,有些元素注定定位不到也没关系,就当没有鼠标,我们可以通过键盘的快捷键完成操作. SendKeys库是专业的处理键盘事件的,所以这里需要用S ...
- Python-Unittest多线程执行用例
前言 假设执行一条脚本(.py)用例一分钟,那么100个脚本需要100分钟,当你的用例达到一千条时需要1000分钟,也就是16个多小时... 那么如何并行运行多个.py的脚本,节省时间呢?这就用到多线 ...
- python--selenium多线程执行用例实例/执行多个用例
python--selenium多线程执行用例实例/执行多个用例 我们在做selenium测试的时候呢,经常会碰到一些需要执行多个用例的情况,也就是多线 程执行py程序,我们前面讲过单个的py用例怎么 ...
- unittest(执行用例)
from selenium import webdriver from time import sleep import unittest#导入unittest库 import HTMLTestRun ...
- selenium+python自动化91-unittest多线程生成报告(BeautifulReport)
前言 selenium多线程跑用例,这个前面一篇已经解决了,如何生成一个测试报告这个是难点,刚好在github上有个大神分享了BeautifulReport,完美的结合起来,就能生成报告了. 环境必备 ...
- python自动化-unittest批量执行用例(discover)
前言 我们在写用例的时候,单个脚本的用例好执行,那么多个脚本的时候,如何批量执行呢?这时候就需要用到unittet里面的discover方法来加载用例了. 加载用例后,用unittest里面的Text ...
- selenium+python-unittest多线程执行用例
前言 假设执行一条脚本(.py)用例一分钟,那么100个脚本需要100分钟,当你的用例达到一千条时需要1000分钟,也就是16个多小时...那么如何并行运行多个.py的脚本,节省时间呢?这就用到多线程 ...
随机推荐
- zoj 1108 FatMouse's Speed 基础dp
FatMouse's Speed Time Limit: 2 Seconds Memory Limit:65536 KB Special Judge FatMouse believe ...
- ElasticSearch(五):简单的ElasticSearch搜索功能
这里主要是一些简单的ElasticSearch的搜索功能,复杂的搜索,比如过滤,聚合等以后单独在写 1. 搜索全部 GET book/_search 直接搜索全部,下面是对搜索结果的详细介绍:默认情况 ...
- .net core grpc 实现通信(一)
现在系统都服务化,.net core 实现服务化的方式有很多,我们通过grpc实现客户端.服务端通信. grpc(https://grpc.io/)是google发布的一个开源.高性能.通用RPC(R ...
- (2)socket的基础使用(基于TCP协议)
socket()模块函数用法 基于TCP协议的套接字程序 netstart -an | findstr 8080 #查看所有TCP和UDP协议的状态,用findstr进行过滤监听8080端口 服务端套 ...
- 【maven】在idea上创建maven多模块项目
参考:https://www.cnblogs.com/wangmingshun/p/6383576.html 一:创建父项目 (1)idea引导页 (2)创建父项目,不需要选择maven插件 (3)完 ...
- ArrayList和LinkedList插入删除效率的测试(完全不在一个数量级8/20)
通过index获取元素的值 java里面的链表可以添加索引,而C中的链表,是没有索引的 package ArrayListVSLinkedList; import java.util.ArrayLis ...
- 时间操作(JavaScript版)—年月日三级联动(默认显示系统时间)
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/wangshuxuncom/article/details/35263317 这个功能 ...
- Erlang
Erlang The Erlang BEAM Virtual Machine Specificationhttp://www.cs-lab.org/historical_beam_instructio ...
- 淘宝 code 使用
淘宝 code上 svn 使用,基本流程: 新建项目 mkdir 创建 branches 文件夹(新建项目的时候,只有 trunk) copy 来创建新分支 checkout 主干和(或)分支到本地 ...
- angularJS自定义服务的几种方式
在angularJS中定义服务共有四种常见的方式:factory,service,provider,constant,value 使用形式的不同: 1)factory以返回对象的形式定义服务: mya ...