nginx中关于并发数的问题worker_connections,worker_processes
我认为,要搞清楚这个公式是否正确,以及如何计算的,那首先要对nginx的各个配置说明有清晰的认识:
从用户的角度,http 1.1协议下,由于浏览器默认使用两个并发连接,因此计算方法:
nginx作为http服务器的时候:
max_clients = worker_processes * worker_connections/2
nginx作为反向代理服务器的时候:
max_clients = worker_processes * worker_connections/4 (
官方wiki(页面标记已经过时,但是网上很多文章都在引用)看到一个关于为什么除以4的解释:
如果作为反向代理,因为浏览器默认会开启2个连接到server,而且Nginx还会使用fds(file descriptor)从同一个连接池建立连接到upstream后端。则最大连接数的计算公式如下:
)
或者从一般建立连接的角度:客户并发连接为1.
nginx作为http服务器的时候:
max_clients = worker_processes * worker_connections
nginx作为反向代理服务器的时候:
max_clients = worker_processes * worker_connections/2
nginx做反向代理时,和客户端之间保持一个连接,和后端服务器保持一个连接。
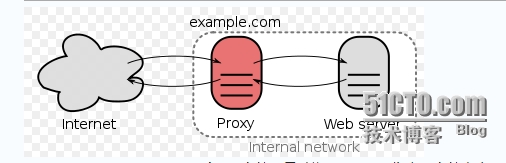
但是怎样合理的设置worker_processes与worker_connections这两个参数?
worker_processes :
worker角色的进程个数(nginx启动后有多少个worker处理http请求。master不处理请求,而是根据相应配置文件信息管理worker进程. master进程主要负责对外揽活(即接收客户端的请求),并将活儿合理的分配给多个worker,每个worker进程主要负责干活(处理请求))。
最理想的worker_processes值取决于很多因素,包含但不限于CPU的核数,存储数据的硬盘驱动器个数(跟这个有什么关系?难道和cpu一样,存在跨区域读取数据问题),以及负载模式(?这个是什么?)当其中任何一个因素不确定的时候,将其设置为cpu核数或许是一个比较好的初始值,“自动”也基本是如此确认一个参数值的。
“自动”这个参数值是从nginx 1.3.8和nginx 1.2.5 开始进行支持的,自动参数可以自动检测 cpu cores 并设置 worker_processes 参数 。
在网上也看到以下建议:
nginx doesn't benefit from more than one worker per CPU.
一个cpu配置多于一个worker数,对nginx而言没有任何益处。
If Nginx is doing CPU-intensive work such as SSL or gzipping and you have 2 or more CPUs/cores, then you may set worker_processes to be equal to the number of CPUs or cores.
如果nginx处理的是cpu密集型(比较耗费cpu的)的操作,建议将此值设置为cpu个数或cpu的核数。
cpu相关信息查看:
逻辑CPU个数:
# cat /proc/cpuinfo | grep "processor" | wc -l
物理CPU个数:
# cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
每个物理CPU中Core的个数:
# cat /proc/cpuinfo | grep "cpu cores" | wc -l
worker_connections:
官方解释如下,个人认为是每一个worker进程能并发处理(发起)的最大连接数(包含所有连接数)。
不能超过最大文件打开数:在linux终端中输入ulimit -a进行查看
http://www.jb51.net/LINUXjishu/164573.html 最大文件打开数相关描述
nginx中关于并发数的问题worker_connections,worker_processes的更多相关文章
- nginx限制ip并发数
nginx限制ip并发数,也是说限制同一个ip同时连接服务器的数量 1.添加limit_zone 这个变量只能在http使用 vi /usr/local/nginx/conf/nginx.conf l ...
- 【转载】nginx 并发数问题思考:worker_connections,worker_processes与 max clients
注:这个文章主要是作者一直在研究nginx作为http server和反向代理服务器时候所谓最大的max_clients和 worker_connections的计算公式, 其实最后的结论也没有卡上公 ...
- nginx 并发数问题思考:worker_connections,worker_processes与 max clients
我相信,很多人都跟我一样,看书都不会太细致也不太认真思考,感觉书中讲的东西都应该是对的,最近读书时我发现以前认为理所当然的东西事实上压根都没有弄明白,最终的结果是,书是别人的,书中的知识也是别人的. ...
- Nginx中worker_connections的问题
查看日志,有一个[warn]: 3660#0: 20000 worker_connections are more than open file resource limit: 1024 !! 原来安 ...
- nginx如何限制并发连接请求数?
简介 限制并发连接数的模块为:http_limit_conn_module,地址:http://nginx.org/en/docs/http/ngx_http_limit_conn_module.ht ...
- 如果nginx 中worker_connections 值设置是1024,worker_processes 值设置是4,按反向代理模式下最大连接数的理论计算公式: 最大连接数 = worker_processes * worker_connections/4
如果nginx 中worker_connections 值设置是1024,worker_processes 值设置是4,按反向代理模式下最大连接数的理论计算公式: 最大连接数 = worker_pro ...
- MySQL 并发测试中,线程数和数据库连接池的实验
我一直以来,对性能测试中,连接池的大小要如何配置,不是太清楚: 就我所知道的,就DB自带对连接数的限制,在sqlserver中用select @@connection 可以查到, 在代码中,可以配置D ...
- Nginx限制访问次数和并发数
Nginx限制访问速率和最大并发连接数模块--limit (防止DDOS攻击) http: ##zone=one或allips 表示设置名为"one"或"allips&q ...
- zabbix自定义key监控nginx和fpm(网站并发数)
一. nginx编译参数 监控nginx,主要讲解监控并发数 --prefix=/usr/local/nginx --with-http_stub_status_module zabbix编译参数的查 ...
随机推荐
- oracle扩容
动态添加表空间: alter tablespace cbs_cos add datafile '/dba/oradata/ORADEVdatafile/cbs_cos02.dbf' size 100m ...
- 小程序 height100% Android ios上的不同表现
Android还是按原图显示 ios,会完全覆盖
- Python 开发者节省时间的 10 个小技巧
Python 是一个美丽的语言,可以激发用户对它的爱.所以如果你试图加入程序员行列,或者你有点厌倦C++,Perl,Java 和其他语言,我推荐你尝试Python. Python有很多吸引程序员的功能 ...
- UI控件之UIScrollView
UIScrollView:提供了滚动功能,用来显示超过一屏的视图 创建滚动视图 UIScrollView *scrollView=[[UIScrollView alloc]initWithFrame: ...
- 每天一个Linux命令(53)service命令
service命令用于对系统服务进行管理. (1)用法: 用法: service [服务] [操作] (2)功能: 功能: service命令用于启动.停止.重 ...
- 023_数量类型练习——Hadoop MapReduce手机流量统计
1) 分析业务需求:用户使用手机上网,存在流量的消耗.流量包括两部分:其一是上行流量(发送消息流量),其二是下行流量(接收消息的流量).每种流量在网络传输过程中,有两种形式说明:包的大小,流量的大小. ...
- 大数据架构之:Spark
Spark是UC Berkeley AMP 实验室基于map reduce算法实现的分布式计算框架,输出和结果保存在内存中,不需要频繁读写HDFS,数据处理效率更高Spark适用于近线或准实时.数据挖 ...
- 【转载】linux下使用 TC 对服务器进行流量控制
tc 介绍 在linux中,tc 有二种控制方法 CBQ 和 HTB.HTB 是设计用来替换 CBQ 的.HTB比CBQ更加灵活,但是CPU 开销也更大,通常高速的链路会使用CBQ,一般而言HTB使用 ...
- Java开发者或许应该经常去看看的网站?...
Java开发者或许应该经常去看看的网站?...Google top3 1.Oracle Technology Network for Java Developers | Oracle Technolo ...
- DNS 递归/迭代 原理
递归查询 递归:客户端只发一次请求,要求对方给出最终结果.一般客户机和服务器之间属递归查询,即当客户机向DNS服务器发出请求后,若DNS服务器本身不能解析,则会向另外的DNS服务器发出查询请求,得到结 ...