利用python实现《数据挖掘——概念与技术》一书中描述的Apriori算法
from itertools import combinations data = [['I1', 'I2', 'I5'], ['I2', 'I4'], ['I2', 'I3'], ['I1', 'I2', 'I4'], ['I1', 'I3'],
['I2', 'I3'], ['I1', 'I3'], ['I1', 'I2', 'I3', 'I5'], ['I1', 'I2', 'I3']] # 候选集生成
# 输入:
# f_set: k-1项集, k:项集个数
# 输出:
# k_cand:k项候选集
def apriori_gen(f_set, k):
k_cand = []
temp = [frozenset(l) for l in combinations(f_set, k)]
for t in temp:
if has_infrequent_subset(t, f_set):
del t
else:
k_cand.append(t)
return k_cand # 非频繁项集的超集也是非频繁的
def has_infrequent_subset(c_set, f_set):
for subset in c_set:
if not frozenset([subset]).issubset(f_set):
return True
return False # 输入(绝对)最小支持度, min_sup
# 输出:全部频繁项集(不包括一项集), all_f_set
def get_f_set(min_sup=2):
all_f_set = []
L1 = frozenset([d for ds in data for d in ds])
k = 2
size = len(L1)
while k <= size:
c_k = frozenset(apriori_gen(L1, k))
for c in c_k:
count = 0
for d in data:
if c.issubset(frozenset(d)):
count += 1
if count >= min_sup:
all_f_set.append((c, count))
k += 1
return all_f_set if __name__ == '__main__':
all_frequent_set = get_f_set()
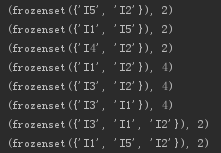
for i in all_frequent_set:
print(i)
利用python实现《数据挖掘——概念与技术》一书中描述的Apriori算法的更多相关文章
- 从《数据挖掘概念与技术》到《Web数据挖掘》
从<数据挖掘概念与技术>到<Web数据挖掘> 认真读过<数据挖掘概念与技术>的第一章后,对数据挖掘有了更加深刻的了解.数据挖掘是知识发展过程的一个步骤.知识发展的过 ...
- 数据挖掘入门系列教程(四点五)之Apriori算法
目录 数据挖掘入门系列教程(四点五)之Apriori算法 频繁(项集)数据的评判标准 Apriori 算法流程 结尾 数据挖掘入门系列教程(四点五)之Apriori算法 Apriori(先验)算法关联 ...
- 【EatBook】-NO.2.EatBook.2.JavaArchitecture.1.001-《修炼Java开发技术在架构中体验设计模式和算法之美》-
1.0.0 Summary Tittle:[EatBook]-NO.2.EatBook.2.JavaArchitecture.1.001-<修炼Java开发技术在架构中体验设计模式和算法之美&g ...
- 利用 Python 练习数据挖掘
本文由 伯乐在线 - 顾星竹 翻译,Namco 校稿.未经许可,禁止转载!英文出处:Giuseppe Vettigli.欢迎加入翻译组. 覆盖使用Python进行数据挖掘查找和描述数据结构模式的实践工 ...
- 【读书笔记-数据挖掘概念与技术】数据仓库与联机分析处理(OLAP)
之前看了认识数据以及数据的预处理,那么,处理之后的数据放在哪儿呢?就放在一个叫“数据仓库”的地方. 数据仓库的基本概念: 数据仓库的定义——面向主题的.集成的.时变的.非易失的 操作数据库系统VS数据 ...
- 数据挖掘概念与技术15--为快速高维OLAP预计算壳片段
1. 论数据立方体预计算的多种策略的优弊 (1)计算完全立方体:需要耗费大量的存储空间和不切实际的计算时间. (2)计算冰山立方体:优于计算完全立方体,但在某种情况下,依然需要大量的存储空间和计算时间 ...
- 《修炼Java开发技术 在架构中体验设计模式和算法之美》 - 书摘精要
(P7) 建议直接加入到软件公司中去,这样会学到很多实际的东西: 程序员最主要的发展方向是资深技术专家,无论是 Java..Net 还是数据库领域,都要首先成为专家,然后才可能继续发展为架构师: 增强 ...
- 利用Python进行数据分析_Pandas_数据加载、存储与文件格式
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 pandas读取文件的解析函数 read_csv 读取带分隔符的数据,默认 ...
- 利用Python进行数据分析_Pandas_层次化索引
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 层次化索引主要解决低纬度形式处理高纬度数据的问题 import pandas ...
随机推荐
- HTML表单(form)的“enctype”属性
Form元素的语法中,EncType表明提交数据的格式 属性值: application/x-www-form-urlencoded:在发送前编码所有字符(默认) multipart/form-dat ...
- 自封装ajax
项目中有时候用不到jq,需要了解xmlhttp原理,自己写一套函数请求和发送数据! /* 封装ajax函数 * @param {string}opt.type http连接的方式,包括POST和GET ...
- ASP.NET MVC 音乐商店 - 6. 使用 DataAnnotations 进行模型验证
在前面的创建专辑与编辑专辑的表单中存在一个问题:我们没有进行任何验证.字段的内容可以不输入,或者在价格的字段中输入一些字符,在执行程序的时候,这些错误会导致数据库保存过程中出现错误,我们将会看到来自数 ...
- 【阿里云产品公测】PTS压力测试最低配ECS性能及评测
PTS是一个性能测试工具,可以使用PTS对自身系统性能在阿里云环境里的状况进行整体评估来找出你的系统性能瓶颈从而优化系统,同时你还可以在了解自己的系统性能指标情况下便于未来新增扩容.在使用PTS前你必 ...
- ASP.NET MVC4 with MySQL: Configuration Error (MySql.Web.v20)
今天在浏览ASP.NET项目时,提示如下错误: Could not load file or assembly ‘MySql.Web.v20, Version=6.9.4.0, Culture=neu ...
- SharePoint 2010配置PDF文件全文检索
一.安装Adobe PDF 64 bit IFilter version 9合Adobe Reader 9下载地址: http://www.adobe.com/support/downloads/de ...
- Fiori里花瓣的动画效果实现原理
Fiori里的busy dialog有两种表现形式,一种是下图里的花朵形状,由5个不断旋转的花瓣组成.另一种是下图的3/4个圆环不断旋转的效果. 关于前者的效果,可以看我制作的这个视频.这个视频是手动 ...
- 传统数据仓库项目的优化手段 (针对 Oracle+DataStage )
普通手段 分区,HASH-JOIN,数据仓库函数,物化视图,位图索引等等为大伙在数据仓库常用的技术, 而下面列举的tips为项目中常用的优化手段/技巧,绿色背景highlight的部分属于非常规手段, ...
- [转]Linux学习
Linux简介与厂商版本 http://www.cnblogs.com/vamei/archive/2012/09/04/2671103.html Linux开机启动(bootstrap) http: ...
- 【洛谷5283】[十二省联考2019] 异或粽子(可持久化Trie树+堆)
点此看题面 大致题意: 求前\(k\)大的区间异或和之和. 可持久化\(Trie\)树 之前做过一些可持久化\(Trie\)树题,结果说到底还是主席树. 终于,碰到一道真·可持久化\(Trie\)树的 ...