利用python实现《数据挖掘——概念与技术》一书中描述的Apriori算法
from itertools import combinations data = [['I1', 'I2', 'I5'], ['I2', 'I4'], ['I2', 'I3'], ['I1', 'I2', 'I4'], ['I1', 'I3'],
['I2', 'I3'], ['I1', 'I3'], ['I1', 'I2', 'I3', 'I5'], ['I1', 'I2', 'I3']] # 候选集生成
# 输入:
# f_set: k-1项集, k:项集个数
# 输出:
# k_cand:k项候选集
def apriori_gen(f_set, k):
k_cand = []
temp = [frozenset(l) for l in combinations(f_set, k)]
for t in temp:
if has_infrequent_subset(t, f_set):
del t
else:
k_cand.append(t)
return k_cand # 非频繁项集的超集也是非频繁的
def has_infrequent_subset(c_set, f_set):
for subset in c_set:
if not frozenset([subset]).issubset(f_set):
return True
return False # 输入(绝对)最小支持度, min_sup
# 输出:全部频繁项集(不包括一项集), all_f_set
def get_f_set(min_sup=2):
all_f_set = []
L1 = frozenset([d for ds in data for d in ds])
k = 2
size = len(L1)
while k <= size:
c_k = frozenset(apriori_gen(L1, k))
for c in c_k:
count = 0
for d in data:
if c.issubset(frozenset(d)):
count += 1
if count >= min_sup:
all_f_set.append((c, count))
k += 1
return all_f_set if __name__ == '__main__':
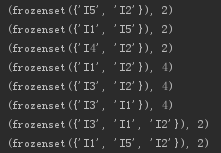
all_frequent_set = get_f_set()
for i in all_frequent_set:
print(i)
利用python实现《数据挖掘——概念与技术》一书中描述的Apriori算法的更多相关文章
- 从《数据挖掘概念与技术》到《Web数据挖掘》
从<数据挖掘概念与技术>到<Web数据挖掘> 认真读过<数据挖掘概念与技术>的第一章后,对数据挖掘有了更加深刻的了解.数据挖掘是知识发展过程的一个步骤.知识发展的过 ...
- 数据挖掘入门系列教程(四点五)之Apriori算法
目录 数据挖掘入门系列教程(四点五)之Apriori算法 频繁(项集)数据的评判标准 Apriori 算法流程 结尾 数据挖掘入门系列教程(四点五)之Apriori算法 Apriori(先验)算法关联 ...
- 【EatBook】-NO.2.EatBook.2.JavaArchitecture.1.001-《修炼Java开发技术在架构中体验设计模式和算法之美》-
1.0.0 Summary Tittle:[EatBook]-NO.2.EatBook.2.JavaArchitecture.1.001-<修炼Java开发技术在架构中体验设计模式和算法之美&g ...
- 利用 Python 练习数据挖掘
本文由 伯乐在线 - 顾星竹 翻译,Namco 校稿.未经许可,禁止转载!英文出处:Giuseppe Vettigli.欢迎加入翻译组. 覆盖使用Python进行数据挖掘查找和描述数据结构模式的实践工 ...
- 【读书笔记-数据挖掘概念与技术】数据仓库与联机分析处理(OLAP)
之前看了认识数据以及数据的预处理,那么,处理之后的数据放在哪儿呢?就放在一个叫“数据仓库”的地方. 数据仓库的基本概念: 数据仓库的定义——面向主题的.集成的.时变的.非易失的 操作数据库系统VS数据 ...
- 数据挖掘概念与技术15--为快速高维OLAP预计算壳片段
1. 论数据立方体预计算的多种策略的优弊 (1)计算完全立方体:需要耗费大量的存储空间和不切实际的计算时间. (2)计算冰山立方体:优于计算完全立方体,但在某种情况下,依然需要大量的存储空间和计算时间 ...
- 《修炼Java开发技术 在架构中体验设计模式和算法之美》 - 书摘精要
(P7) 建议直接加入到软件公司中去,这样会学到很多实际的东西: 程序员最主要的发展方向是资深技术专家,无论是 Java..Net 还是数据库领域,都要首先成为专家,然后才可能继续发展为架构师: 增强 ...
- 利用Python进行数据分析_Pandas_数据加载、存储与文件格式
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 pandas读取文件的解析函数 read_csv 读取带分隔符的数据,默认 ...
- 利用Python进行数据分析_Pandas_层次化索引
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 层次化索引主要解决低纬度形式处理高纬度数据的问题 import pandas ...
随机推荐
- 【代码笔记】Java学习一阶段总结
写笔记需要打开eclipse写 哈哈哈哈,不然写什么都屡不清了 ……还需要打开API说明文档. JFrame 窗体组件. JFrame里面常用的函数: setSize 设置窗体大小 setDefaul ...
- vue授权页面登陆之后返回之前的页面
import Vue from 'vue'import Router from 'vue-router'Vue.use(Router)import home from "@/pages/ho ...
- boost库的配置——Linux篇
Boost库分为两个部分来使用,一是直接使用对应的头文件,二是需要编译安装相应的库才可以使用. 下面是boost在Linux上安装和使用过程(整个boost库全部安装): (1)在www.boost. ...
- 设计模式之简单工厂模式(Simple Factory)
原文地址:http://www.cnblogs.com/BeyondAnyTime/archive/2012/07/06/2579100.html 今天呢,要学习的设计模式是“简单工厂模式”,这是一个 ...
- git相关操作(githug)
Level 15 restructure 关卡描述 你添加了一些文件到你的仓库,但现在知道你的项目需要进行调整.创建一个新的文件夹命名为“src”,使用git将所有的".html" ...
- diskpart分区
分区知识充电: 主分区:主分区,也称为主磁盘分区,和拓展分区.逻辑分区一样,是一种分区类型.主分区中不能再划分其他类型的分区,因此每个主分区都相当于一个逻辑磁(在这一点上主分区和逻辑分区很相似,但主分 ...
- 【转】OpenGL概述
英文原文 中文译文 1. 计算机图像硬件 1.1 GPU(图像处理单元) 如今,计算机拥有用来专门做图像处理显示的GPU模块,拥有独立的图像处理储存(显存). 1.2 像素和画面 任何图像显示都是基于 ...
- scrum和团队合作
一. 队名及宣言 队名 the better for you 宣言Change our lives with code 二. 队员及分工 a.承担软件工程的角色 姓名 学号 角色 张美庆 B20150 ...
- python入门3 python变量,id(),is运算符
python变量无需声明数据类型,可以直接赋值使用. 比如: num=100 #整数 str="字符串" #字符串 turple1 =('mon','tue','wed','thu ...
- EXCRT
是个好东西,可以处理在模数不互质的同余方程组 核心就是用扩欧来合并方程 如果我们有两个形如\(x\equiv b_1(mod\ a_1)\) \(x\equiv b_2(mod\ a_2)\)的方程我 ...