论文讨论&&思考《Deformable Convolutional Networks》
这篇论文真是让我又爱又恨,可以说是我看过的最认真也是最多次的几篇paper之一了,首先deformable conv的思想我觉得非常好,通过end-to-end的思想来做这件事也是极其的make sense的,但是一直觉得哪里有问题,之前说不上来,最近想通了几点,先初步说几句,等把他们的代码跑通并且实验好自己的几个想法后可以再来聊一聊。首先我是做semantic segmentation的,所以只想说说关于这方面的问题。
直接看这篇paper的话可能会觉得ji feng的这篇工作非常棒,但实际上在我看来还是噱头多一点(我完全主观的胡说八道),deformable conv是STN和DFF两篇工作的结合,前者提供了bilinear sample的思路和具体的bp,后者提供了warp的思路和方法,不过好像说的也不是很准确。。我暂时的理解是这样的:deformable conv就是把deep feature flow中的flow换成了可学习的offset。接下来分为亮点和槽点来说一说。
一、亮点
亮点说实话还是很多的,首先解决了STN(spatial transform network)的实用性问题,因为STN是对整个feature map做transform的动作,例如学习出一个linear transform的 matrix,这个在做minist的时候当然是极其合理的,但是在真实世界中,这个动作不仅不合理而且意义不大的,因为复杂场景下的信息很多,背景也很多,那么它是怎么做的呢?
首先我想先说一个很重要的误区,很多人以为deformable conv学习的是个deformabe 的kernel,比方说本来是一个3*3相互连接的kernel,最后变成了一个没个位置都有一个offset的kernel。实际情况并不是这样的,作者并没有对kernel学习offset,而是对feature的每个位置学习一个offset,一步一步的解释就是:首先有一个原始的feature map F,在上面做channel为18的3*3的卷积,得到channel=18的feature map F_offset,然后再对F做deformable conv并且传入offset 的值F_offset,在新得到的结果上,每个值对应原来的feature map F上是从一个3*3的kernel上计算得到的,每个值对应的F上的3*3的区域上的每个值都有x、y方向上的两个offset,这3*3*2=18的值就由刚才传入的F_offset决定。。。。貌似说的有点绕,其实理清楚关键的一点就是:学习出来的offset是channel=18并且和原 feature map一样大小的,对应的是main branch上做deformable conv时候每位置上的kernel的每个位置的offset。
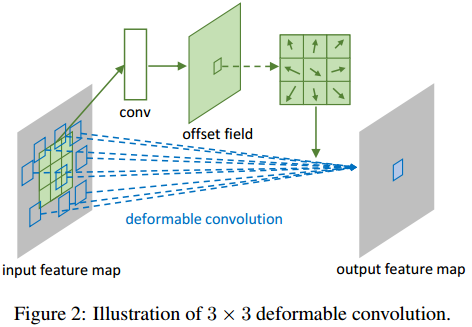
知乎上有个人说了一句我特别赞同的话:用bilinear的方法代替weight的方法,即用采样代替权重的方法。这个思维是可以发散开来做更多的工作的,这也是我觉得这篇paper最棒的地方。
二、槽点
这个其实我今天写篇blog的重点。。。我对offset能否学习到极其的的不看好,虽然最后还要看实验的效果和实际的结果,当我想说两点。
1、从feature的需求来看,senmantic segmentation对于feature的需求是跟detection不同的,这个问题其实jifeng Dai和kaiming的R-FCN中都提到过,然后semantic segmentation需要的feature不会过于关注什么旋转平移不变性,也就是物体的旋转平移对结果是有影响的,他们对position是care的,这个问题有时间我想再看看R-FCN讨论一发,因此这里直接用feature 通过一层卷积就可以学习到offset,我是怀疑的。
2.上面的怀疑其实有点没道理,这次有个稍微有那么一丢丢的怀疑,bilinear sample其实是一个分段线性函数,所以逻辑上在bp的时候,你要想你的目的是让loss下降的话,就不能让你的step太大以至于超过来当前的线性区间,也就是你在当前四个点中算出来梯度,如果你更新后跳到另外四个点上来,理论上这次的gradient的更新就是错误的,loss是不一定下降的,但是话说回来,如果不跳到另外四个点,这个offset永远限制在当前四个点里面的话,也是毫无意义的。话再说回来,因为整个feature map还是smooth的,这也跟图像的性质有关,所以我们还是比较相信只要你的lr不是很大,loss还是会下降的。
三、总结
总的来说这是一篇很有意义的工作,在我看来,任何能启发之后的工作和引起人思考的工作都是很有意义的,无论它work不work,在benchmark跑的怎么样。
还有些东西我想等实验跑完再来说说,所以待续~
论文讨论&&思考《Deformable Convolutional Networks》的更多相关文章
- 图像处理论文详解 | Deformable Convolutional Networks | CVPR | 2017
文章转自同一作者的微信公众号:[机器学习炼丹术] 论文名称:"Deformable Convolutional Networks" 论文链接:https://arxiv.org/a ...
- 目标检测论文阅读:Deformable Convolutional Networks
https://blog.csdn.net/qq_21949357/article/details/80538255 这篇论文其实读起来还是比较难懂的,主要是细节部分很需要推敲,尤其是deformab ...
- 论文阅读笔记三十八:Deformable Convolutional Networks(ECCV2017)
论文源址:https://arxiv.org/abs/1703.06211 开源项目:https://github.com/msracver/Deformable-ConvNets 摘要 卷积神经网络 ...
- 深度学习方法(十三):卷积神经网络结构变化——可变形卷积网络deformable convolutional networks
上一篇我们介绍了:深度学习方法(十二):卷积神经网络结构变化--Spatial Transformer Networks,STN创造性地在CNN结构中装入了一个可学习的仿射变换,目的是增加CNN的旋转 ...
- Deformable Convolutional Networks
1 空洞卷积 1.1 理解空洞卷积 在图像分割领域,图像输入到CNN(典型的网络比如FCN)中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预 ...
- VGGNet论文翻译-Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition Karen Simonyan[‡] & Andrew Zi ...
- [论文理解] Learning Efficient Convolutional Networks through Network Slimming
Learning Efficient Convolutional Networks through Network Slimming 简介 这是我看的第一篇模型压缩方面的论文,应该也算比较出名的一篇吧 ...
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
- [论文阅读]VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION(VGGNet)
VGGNet由牛津大学的视觉几何组(Visual Geometry Group)提出,是ILSVRC-2014中定位任务第一名和分类任务第二名.本文的主要贡献点就是使用小的卷积核(3x3)来增加网络的 ...
随机推荐
- 9-C++远征之多态篇-学习笔记
C++远征之多态篇 面向对象三大特征:封装,继承,多态 多态: 发出一条命令时,不同的对象接收到同样的命令做出的动作不同 多态篇会学习到的目录: 普通虚函数 & 虚析构函数 纯虚函数:抽象类 ...
- JSON初体验(一):JsonObject解析
在学校的呆了一段时间,马上又要回去工作了,不说了,我现在介绍一下json相关的内容 1.JSON数据格式(总的来说,json就是一个字符串) 1.整体结构 String json1 = "{ ...
- 编译net core时nuget里全部报错,\obj\project.assets.json找不到
除了Nuget管理设置允许下载缺少的程序包 如果你自己设置的程序包源里有一个源访问不到,则可能出现下面错误,导致所有nuget无法还原. 而且在VS2017里不会出现这个 SDK,特别是你网上下载的其 ...
- Moodle 3.4中添加小组、大组、群
Moodle在高中应用时经常要用到年级.班级和小组,我们可以用群.大组.小组来代替. 小组设置:网站首页-->现有课程-->右上角的设置按钮-->更多-->用户-->小组 ...
- Electron入门应用打包exe(windows)
最近在学习nodejs,得知Electron是通过将Chromium和Node.js合并到同一个运行时环境中,用HTML,CSS和JavaScript来构建跨平台桌面应用程序的一门技术.对于之前一直从 ...
- Android应用AsyncTask处理机制详解及源码分析
1 背景 Android异步处理机制一直都是Android的一个核心,也是应用工程师面试的一个知识点.前面我们分析了Handler异步机制原理(不了解的可以阅读我的<Android异步消息处理机 ...
- 项目总结(二)->一些常用的工具浅谈
程序员是否应该沉迷于一个编程的世界,为了磨砺自己的编程技能而两耳不闻窗外事,一心只为写代码:还是说要做到各有涉猎,全而不精.关于这点每个人心中都有一套自己的工作体系和方法体系. 我一直认为,程序员你首 ...
- github 初始化操作小记
Git作为一种越来越重要的工具,github又如此流行,现在就简单记录一下git的基础操作,希望能帮助大家快速体验入门! 1 查看本地是否存在”公钥”和”私钥” 如果没有,则执行: ssh-keyg ...
- CSS实现自适应下保持宽高比
在项目中,我们可能经常使得自己设计的网页能自适应.特别是网站中的图片,经常要求在网页放大(或缩小)时,宽高同时放大(或缩小),而且不变形(即保持正常的长宽比).为了不变形,常用的方法就是设置width ...
- 梳理 Opengl ES 3.0 (三)顶点坐标变换
先来个宏观上的理解: 其实这块逻辑是个标准流程,而且其他地方介绍的也很多了,这里简单提下. 坐标转换,其实是不同坐标系之间的变换,一个渲染顶点,要想让它呈现在屏幕上的某个位置,是需要让这个顶点经过一个 ...