scrapy shell命令的【选项】简介
在使用scrapy shell测试某网站时,其返回400 Bad Request,那么,更改User-Agent请求头信息再试。
DEBUG: Crawled () <GET https://www.某网站.com> (referer: None)
可是,怎么更改呢?
使用scrapy shell --help命令查看其用法:
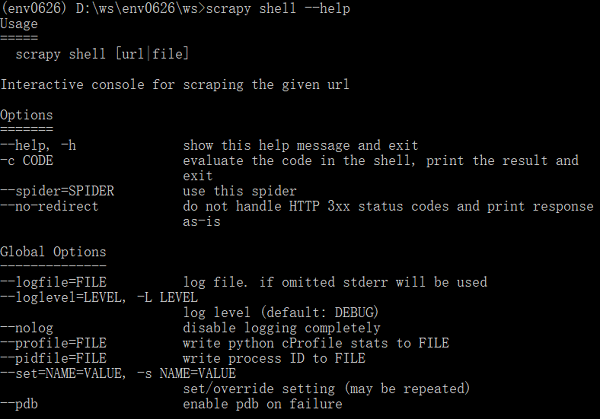
Options中没有找到相应的选项;
Global Options呢?里面的--set/-s命令可以设置/重写配置。
使用-s选项更改了User-Agent配置,再测试某网站,成功返回页面(状态200):
...>scrapy shell -s USER_AGENT="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36" https://www.某网站.com
2018-07-15 12:11:00 [scrapy.core.engine] DEBUG: Crawled () <GET https://www.某网站.com> (referer: None)
--------翻篇--------
说明,其实,这个-s的用法并非自己通过上面步骤知道的(之前一直关注Options下面的选项,忽略了Global Options,觉得没用吗?),而是通过网页搜索,然后见到下面的文章:
scrapy shell 用法(慢慢更新...) 原文作者:木木&侃侃(一位园友,原文链接)

更进一步:在Scrapy的源码中会对相关配置项有更详细的信息。
打开C:\Python36\Lib\site-packages\scrapy\commands目录,可以在里面看到各种内置的Scrapy命令的Python文件,其中,shell.py正是scrapy shell命令的源文件。

从源码可以看到,里面定义了Command类——继承了scrapy.commands.ScrapyCommand,在Command的add_options函数中,添加了三个选项:
-c:evaluate the code in the shell, print the result and exit(执行一段解析代码?)
--spider:use this spider
--no-redirect:do not handle HTTP 3xx status codes and print response as-is
没有发现-s选项,那么,-s选项来自哪儿呢?看看scrapy.commands.ScrapyCommand的源码(__init__.py文件中)。可以发现,其下的add_options函数中添加了-s选项:
def add_options(self, parser):
"""
Populate option parse with options available for this command
"""
group = OptionGroup(parser, "Global Options")
group.add_option("--logfile", metavar="FILE",
help="log file. if omitted stderr will be used")
group.add_option("-L", "--loglevel", metavar="LEVEL", default=None,
help="log level (default: %s)" % self.settings['LOG_LEVEL'])
group.add_option("--nolog", action="store_true",
help="disable logging completely")
group.add_option("--profile", metavar="FILE", default=None,
help="write python cProfile stats to FILE")
group.add_option("--pidfile", metavar="FILE",
help="write process ID to FILE")
group.add_option("-s", "--set", action="append", default=[], metavar="NAME=VALUE",
help="set/override setting (may be repeated)")
group.add_option("--pdb", action="store_true", help="enable pdb on failure") parser.add_option_group(group)
好了,源头找到了。
可是,之前在寻找方法时发现,scrapy crawl、runspider提供了-a选项来设置/重写配置,可是,已经有了-s选项了,为何还要增加-a选项呢?两者有什么区别?
从其解释来看,-a选项仅仅修改spider的参数,而-s可以设置的范围更广泛,包括官文Settings中所有配置吧!(未测试)
parser.add_option("-a", dest="spargs", action="append", default=[], metavar="NAME=VALUE",
help="set spider argument (may be repeated)")
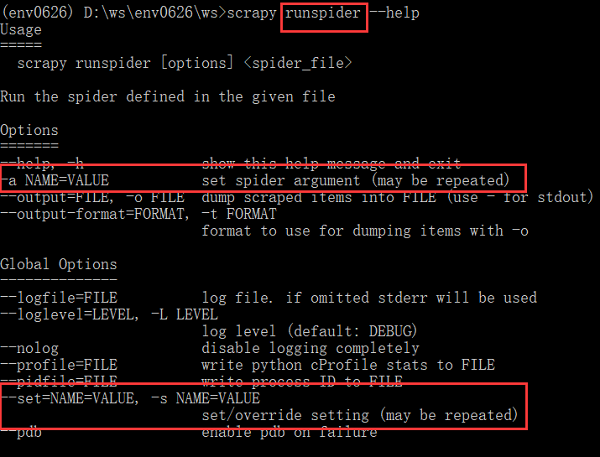
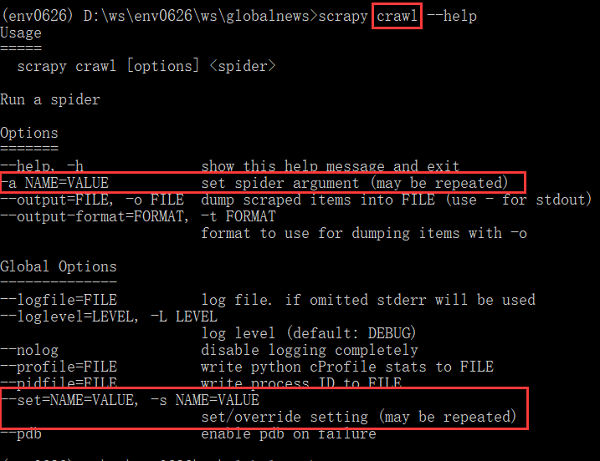
--------翻篇--------
实践1:scrapy shell的-c选项
(env0626) D:\ws\env0626\ws>scrapy shell -c "response.xpath('//title/text()')" https://www.baidu.com
输出:
2018-07-15 13:07:23 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.baidu.com> (referer: None)
[<Selector xpath='//title/text()' data='百度一下,你就知道'>]
实践2:scrapy runspider -a选项和-s选项修改User-Agent请求头
# -*- coding: utf-8 -*-
import scrapy class MousiteSpider(scrapy.Spider):
name = 'mousite'
allowed_domains = ['www.zhihu.com']
start_urls = ['https://www.zhihu.com/'] def parse(self, response):
yield response.xpath('//title/text()')
测试结果:-a选项无法获取数据,返回400;-s选项可以,返回200;
-a选项:
(env0626) D:\ws\env0626\ws>scrapy runspider -a USER_AGENT="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36" mousite.py
DEBUG: Crawled (400) <GET https://www.zhihu.com/> (referer: None)
INFO: Ignoring response <400 https://www.zhihu.com/>: HTTP status code is not handled or not allowed
-s选项:
(env0626) D:\ws\env0626\ws>scrapy runspider -s USER_AGENT="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36" mousite.py
DEBUG: Crawled (200) <GET https://www.zhihu.com/> (referer: None)
{'title': [<Selector xpath='//title/text()' data='知乎 - 发现更大的世界'>]}
看来,两者还是有差别的。
注意,上面的试验都是在Scrapy项目外执行()。
scrapy shell命令的【选项】简介的更多相关文章
- 在Scrapy项目【内外】使用scrapy shell命令抓取 某网站首页的初步情况
Windows 10家庭中文版,Python 3.6.3,Scrapy 1.5.0, 时隔一月,再次玩Scrapy项目,希望这次可以玩的更进一步. 本文展示使用在 Scrapy项目内.项目外scrap ...
- Linux下shell命令执行过程简介
Linux是如何寻找命令路径的:http://c.biancheng.net/view/5969.html Linux上命令运行的基本过程:https://blog.csdn.net/hjx5200/ ...
- 安装ipython,使用scrapy shell来验证xpath选择的结果 | How to install iPython and how does it work with Scrapy Shell
1. scrapy shell 是scrapy包的一个很好的交互性工具,目前我使用它主要用于验证xpath选择的结果.安装好了scrapy之后,就能够直接在cmd上操作scrapy shell了. 具 ...
- scrapy shell 用法(慢慢更新...)
scrapy shell 命令 1.scrapy shell url #url指你所需要爬的网址 2.有些网址数据的爬取需要user-agent,scrapy shell中可以直接添加头文件, 第①种 ...
- Scrapy的shell命令(转)
scrapy python MrZONT 2015年08月29日发布 ...
- Scrapy命令行工具简介
Windows 10家庭中文版,Python 3.6.4,virtualenv 16.0.0,Scrapy 1.5.0, 在最初使用Scrapy时,使用编辑器或IDE手动编写模块来创建爬虫(Spide ...
- 4-3 调试代码命令 scrapy shell http://blog.jobbole.com/114496/(入口url)
调试代码命令 scrapy shell http://blog.jobbole.com/114496/(入口url)
- linux + shell 命令等
Linux命令[注意:建议用UltraEdit打开] 一.文件处理命令 1.命令格式与目录处理命令 ls –a[查看隐藏文件] ls –l[查看文件信息长格式显示] ls –d[查看指定目录的详细信息 ...
- VxWorks操作系统shell命令与调试方法总结
VxWorks下的调试手段 主要介绍在Tornado集成开发环境下的调试方法,和利用支撑定位问题的步骤.思路. 1 Tornado的调试工具 嵌入式实时操作系统VxWorks和集成开发 ...
随机推荐
- 【poj3133】 Manhattan Wiring
http://poj.org/problem?id=3133 (题目链接) 题意 $n*m$的网格里有空格和障碍,还有两个$2$和两个$3$.要求把这两个$2$和两个$3$各用一条折线连起来.障碍里不 ...
- codeforces contest 1111
A. Superhero Transformation 题意: 元音和元音,辅音和辅音字母之间可以互相转换,问两个字符串是否想同: 题解:直接判断即可: #include<bits/stdc++ ...
- pycharm配置总结
1. 快捷键 格式化代码:Ctrl + Alt + L 2. A scheme with this name already exists or was deleted without applyin ...
- Java入门:基础算法之计算园的面积
本部分内容介绍如何使用Java计算圆的周长和面积.分两种方法来实现: 1)圆的半径由用户输入 2)圆的半径由程序指定 代码1: /** * @作者: 理工云课堂 * @描述: 用户输入圆的半径,程序结 ...
- Docker入门与应用系列(三)容器管理
一.启动容器 启动容器有两种方式,一种是基于镜像新建一个容器并启动,另一个是将终止状态的容器重新启动. 1.1 新建并启动 主要命令为 docker run 下面的命令输出一个”Hello,world ...
- unicode utf8 学习记录
显示器- unicode -系统- utf8 -存储设备 Unicode是一套复杂的字符编码标准,简单来说就是将人类使用的每个所谓字符与一个非负整数对应,并且保证不同的字符对应的整数一定不同.UTF- ...
- Go_16:GoLang中flag标签使用
正如其他语言一样,在 linux 系统上通过传入不同的参数来使得代码执行不同逻辑实现不同功能,这样的优点就是执行想要的既定逻辑而不需要修改代码重新编译与打包.在 Golang 语言中也为我们提供了相应 ...
- P1783 二分并查集写法
并查集 + 二分 我是 并查集 + 二分 做的QVQ 思路:两两枚举点之间的距离,sort排序,使距离有序.二分答案,每次判断是否符合条件,然后缩小查询范围,直到满足题目要求(保留2位小数精度就为 0 ...
- Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法
Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. fs.listFiles方法,返回Loc ...
- SFTP上传下载文件、文件夹常用操作
SFTP上传下载文件.文件夹常用操作 1.查看上传下载目录lpwd 2.改变上传和下载的目录(例如D盘):lcd d:/ 3.查看当前路径pwd 4.下载文件(例如我要将服务器上tomcat的日志文 ...