Sparse AutoEncoder简介
1. AutoEncoder
AutoEncoder是一种特殊的三层神经网络, 其输出等于输入:\(y^{(i)}=x^{(i)}\), 如下图所示:
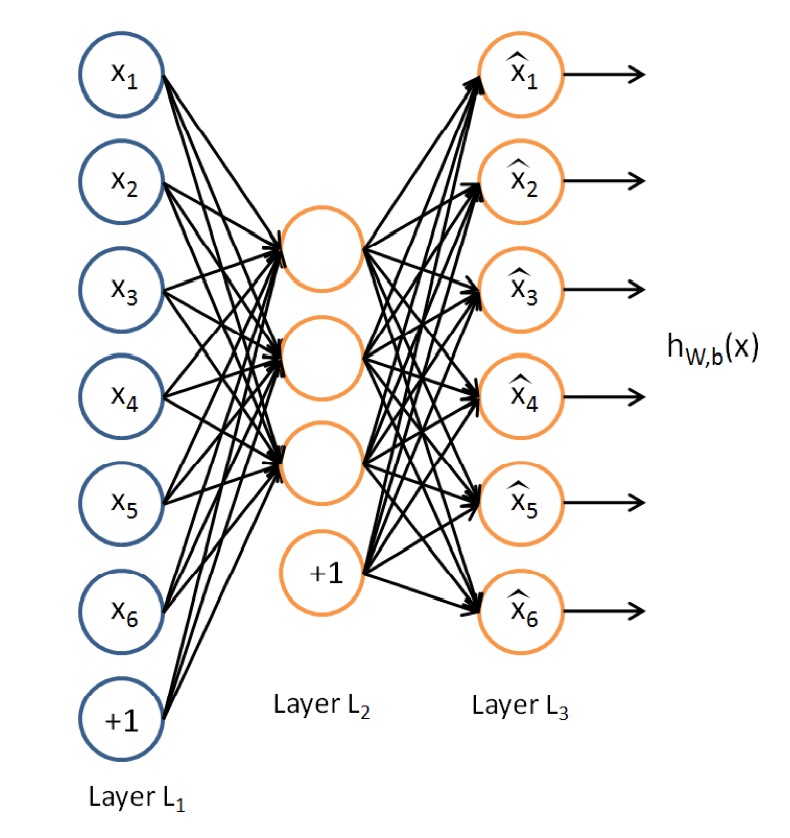
亦即AutoEncoder想学到的函数为\(f_{W,b} \approx x\), 来使得输出\(\hat{x}\)比较接近x. 乍看上去学到的这种函数很平凡, 没啥用处, 实际上, 如果我们限制一下AutoEncoder的隐藏单元的个数小于输入特征的个数, 便可以学到数据的很多有趣的结构. 如果特征之间存在一定的相关性, 则AutoEncoder会发现这些相关性.
2. Sparse AutoEncoder
我们可以限制隐藏单元的个数来学到有用的特征, 或者可以对网络施加其他的限制条件, 而不限制隐藏单元的个数. 特别的, 我们可以对隐藏单元施加稀疏性限制. 具体的, 一个神经元是激活的当且仅当其输出值比较接近1, 一个神经元是不激活的当且仅当其输出值比较接近0. 我们可以限制神经元在大多数时间下都是不激活的(亦即Sparse Filtering中的Lifetime Sparsity概念).
定义\(a_j^{(2)}\)为AutoEncoder中隐藏单元的激活值, 我们形式化的定义如下的限制:$${\hat{\rho}}_j=\frac{1}{m}\sum_{i=1}^{m}[a_j^{2}(x^{(i)})]=\rho$$
其中\(\rho\)是稀疏性参数, 一般取值为一个比较接近0的数, 比如0.05.
为了使得学到的AutoEncoder达到上述的稀疏性要求, 我们在优化目标里添加了新的一项, 用于惩罚那些偏离\(\rho\)太多的\(\hat{\rho}_j\). 可以使用KL Divergence:$$\sum_{j=1}^{s_2} \rho log \frac{\rho}{\hat{\rho}_j}+(1-\rho)log\frac{1-\rho}{1-\hat{\rho}_j}$$
上式可也以写作:$$\sum_{j=1}^{s_2}KL(\rho||\hat{\rho}_j)$$
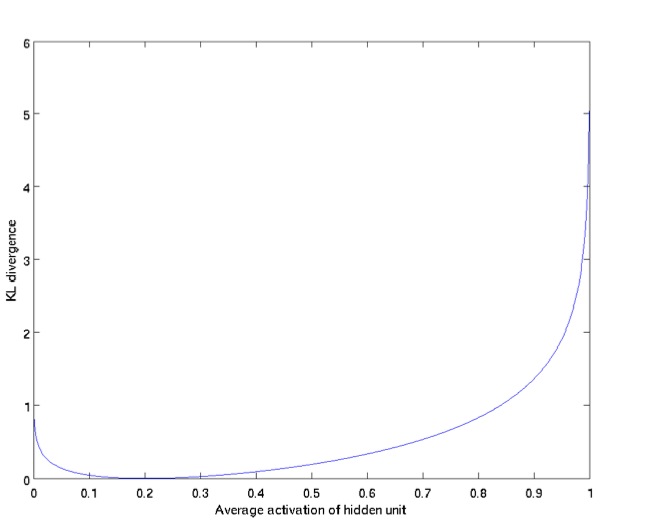
下图展示了KL Divergence的特性: \(\hat{\rho}_j\)越接近\(\rho\)(此处为0.2), 则KL Divergence越小.
所以, Sparse AutoEncoder的损失函数为:$$\mathit{J}_{sparse}(\mathit{W},\mathit{b})=\mathit{J}(\mathit{W},\mathit{b}) + \beta\sum_{j=1}^{s_2}KL(\rho||\hat{\rho}_j)$$
其中$$\mathit{J}(\mathit{W},\mathit{b})=\left[\frac{1}{m}\sum_{i=1}^{m}\mathit{J}(\mathit{W},\mathit{b};\mathit{x}^{(i)},\mathit{j}^{(i)})\right]+\frac{\lambda}{2}\sum_{l=1}^{n_l-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_l+1}\left(\mathit{W}_{ji}^{(l)}\right) ^2=\left[\frac{1}{m}\sum_{i=1}^{m}\left(\frac{1}{2}\left|\left|h_{\mathit{W,b}}(x^{(i)})-y^{(i)}\right|\right| ^2\right)\right]+\frac{\lambda}{2}\sum_{l=1}^{n_l-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_l+1}\left(\mathit{W}_{ji}^{(l)}\right) ^2$$
添加KL Divergence后的cost function后的偏导数为:


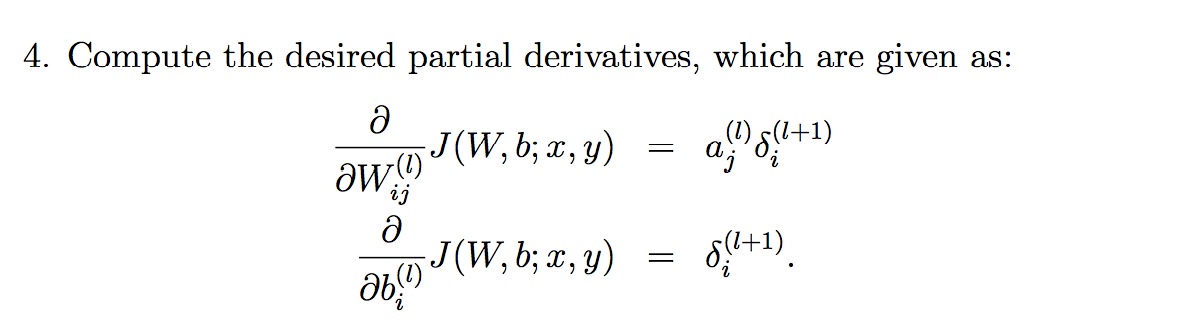
有个新的偏导数之后, 使用Back Propagation来优化整个神经网络:

参考文献:
[1]. Sparse AutoEncoder. Andrew Ng.
Sparse AutoEncoder简介的更多相关文章
- Deep Learning 1_深度学习UFLDL教程:Sparse Autoencoder练习(斯坦福大学深度学习教程)
1前言 本人写技术博客的目的,其实是感觉好多东西,很长一段时间不动就会忘记了,为了加深学习记忆以及方便以后可能忘记后能很快回忆起自己曾经学过的东西. 首先,在网上找了一些资料,看见介绍说UFLDL很不 ...
- (六)6.5 Neurons Networks Implements of Sparse Autoencoder
一大波matlab代码正在靠近.- -! sparse autoencoder的一个实例练习,这个例子所要实现的内容大概如下:从给定的很多张自然图片中截取出大小为8*8的小patches图片共1000 ...
- UFLDL实验报告2:Sparse Autoencoder
Sparse Autoencoder稀疏自编码器实验报告 1.Sparse Autoencoder稀疏自编码器实验描述 自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值, ...
- 七、Sparse Autoencoder介绍
目前为止,我们已经讨论了神经网络在有监督学习中的应用.在有监督学习中,训练样本是有类别标签的.现在假设我们只有一个没有带类别标签的训练样本集合 ,其中 .自编码神经网络是一种无监督学习算法,它使用 ...
- CS229 6.5 Neurons Networks Implements of Sparse Autoencoder
sparse autoencoder的一个实例练习,这个例子所要实现的内容大概如下:从给定的很多张自然图片中截取出大小为8*8的小patches图片共10000张,现在需要用sparse autoen ...
- 【DeepLearning】Exercise:Sparse Autoencoder
Exercise:Sparse Autoencoder 习题的链接:Exercise:Sparse Autoencoder 注意点: 1.训练样本像素值需要归一化. 因为输出层的激活函数是logist ...
- Sparse Filtering简介
当前很多的特征学习(feature learning)算法需要很多的超参数(hyper-parameter)调节, Sparse Filtering则只需要一个超参数--需要学习的特征的个数, 所以非 ...
- Exercise:Sparse Autoencoder
斯坦福deep learning教程中的自稀疏编码器的练习,主要是参考了 http://www.cnblogs.com/tornadomeet/archive/2013/03/20/2970724 ...
- DL二(稀疏自编码器 Sparse Autoencoder)
稀疏自编码器 Sparse Autoencoder 一神经网络(Neural Networks) 1.1 基本术语 神经网络(neural networks) 激活函数(activation func ...
随机推荐
- Delphi 使用TAdoQuery执行存储过程的样例
procedure TCustomerForm.FindCustomerInfo;var strSql:string;begin // BL_HV_FindCustomerInfo 存储过程的名称 ...
- PHP 内置函数strlen 和mbstring扩展函数mb_strlen的区别
#EXAMPLE $str_uncode = "简体中文Chinese(Simplified)"; //统计字符串长度 echo strlen($str_uncode).'< ...
- app流畅度测试--使用SM
通过测量应用的帧率FPS并不能准确评价App的流畅度,FPS较低并不能代表当前App在UI上界面不流畅,而1s内VSync这个Loop运行了多少次更加能说明当前App的流畅程度. 那么我们可以直接在A ...
- 函数防抖与函数节流 封装好的debounce和throttle函数
/** * 空闲控制 返回函数连续调用时,空闲时间必须大于或等于 wait,func 才会执行 * * @param {function} func 传入函数,最后一个参数是额外增加的this对象,. ...
- 【刷题】BZOJ 1926 [Sdoi2010]粟粟的书架
Description 幸福幼儿园 B29 班的粟粟是一个聪明机灵.乖巧可爱的小朋友,她的爱好是画画和读书,尤其喜欢 Thomas H. Cormen 的文章.粟粟家中有一个 R行C 列的巨型书架,书 ...
- 【AGC010F】Tree Game
Description 有一棵\(n\)个节点的树(\(n \le 3000\)),第\(i\)条边连接\(a_i,b_i\),每个节点\(i\)上有\(A_i\)个石子,高桥君和青木君将在树上玩游戏 ...
- 【Cf #503 B】The hat(二分)
为什么Cf上所有的交互题都是$binary \; Search$... 把序列分成前后两个相等的部分,每一个都可以看成一条斜率为正负$1$的折线.我们把他们放在一起,显然,当折线的交点的横坐标为整数时 ...
- Linux内核分析第八周——进程的切换和系统的一般执行过程
Linux内核分析第八周--进程的切换和系统的一般执行过程 李雪琦+原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study.163.com/cou ...
- php 百家姓
private $surname = array('赵','钱','孙','李','周','吴','郑','王','冯','陈','褚','卫','蒋','沈','韩','杨','朱','秦','尤' ...
- Python之旅:并发编程之多线程理论部分
一 什么是线程 在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程 线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程 车间负责把资源整合 ...