机器学习算法整理(五)决策树_随机森林——鹃尾花实例 Python实现
以下均为自己看视频做的笔记,自用,侵删!
还参考了:http://www.ai-start.com/ml2014/
%matplotlib inline
import pandas as pd
import matplotlib.pylab as plt iris_data = pd.read_csv('iris.data')
iris_data.columns = ['sepal_length_cm', 'sepal_width_cm', 'petal_length_cm', 'petal_width_cm', 'class']
iris_data.head()
| sepal_length_cm | sepal_width_cm | petal_length_cm | petal_width_cm | class | |
|---|---|---|---|---|---|
| 0 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 2 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 3 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| 4 | 5.4 | 3.9 | 1.7 | 0.4 | Iris-setosa |
from PIL import Image
img = Image.open('test.jpg')
plt.imshow(img)
plt.show()
iris_data.describe()
| sepal_length_cm | sepal_width_cm | petal_length_cm | petal_width_cm | |
|---|---|---|---|---|
| count | 149.000000 | 149.000000 | 149.000000 | 149.000000 |
| mean | 5.848322 | 3.051007 | 3.774497 | 1.205369 |
| std | 0.828594 | 0.433499 | 1.759651 | 0.761292 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.400000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
画出每个种类的分布
%matplotlib inline import matplotlib.pyplot as plt
import seaborn as sb # pairplot传入的数据不能有缺失值
sb.pairplot(iris_data.dropna(), hue='class')
<seaborn.axisgrid.PairGrid at 0x166afc88>
plt.figure(figsize=(10, 10))
# 列名的索引,改列名
for column_index, column in enumerate(iris_data.columns):
if column == 'class':
continue
plt.subplot(2, 2, column_index + 1)
sb.violinplot(x='class', y=column, data=iris_data)
划分训练集和测试集
from sklearn.cross_validation import train_test_split all_inputs = iris_data[['sepal_length_cm', 'sepal_width_cm',
'petal_length_cm', 'petal_width_cm']].values all_classes = iris_data['class'].values (training_inputs,
testing_inputs,
training_classes,
testing_classes) = train_test_split(all_inputs, all_classes, train_size=0.75, random_state=1)
构建决策树模型
from sklearn.tree import DecisionTreeClassifier
# 1.criterion gini or entropy 评判标准 # 2.splitter best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中(数据量大的时候) # 3.max_features None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的 # 4.max_depth 数据少或者特征少的时候可以不管这个值,如果模型样本量多,特征也多的情况下,可以尝试限制下(预剪枝) # 5.min_samples_split 如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分
# 如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。(停止的操作) # 6.min_samples_leaf 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被
# 剪枝,如果样本量不大,不需要管这个值,大些如10W可是尝试下5 # 7.min_weight_fraction_leaf 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起
# 被剪枝默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,
# 或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。 # 8.max_leaf_nodes 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。
# 如果加了限制,算法会建立在最大叶子节点数内最优的决策树。
# 如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制
# 具体的值可以通过交叉验证得到。 # 9.class_weight 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多
# 导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重
# 如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。 # 10.min_impurity_split 这个值限制了决策树的增长,如果某节点的不纯度
# (基尼系数,信息增益,均方差,绝对差)小于这个阈值
# 则该节点不再生成子节点。即为叶子节点 。(用的比较多)
decision_tree_classifier = DecisionTreeClassifier() # Train the classifier on the training set
decision_tree_classifier.fit(training_inputs, training_classes) # Validate the classifier on the testing set using classification accuracy
decision_tree_classifier.score(testing_inputs, testing_classes)
0.97368421052631582
from sklearn.cross_validation import cross_val_score
import numpy as np decision_tree_classifier = DecisionTreeClassifier() # cross_val_score returns a list of the scores, which we can visualize
# to get a reasonable estimate of our classifier's performance
cv_scores = cross_val_score(decision_tree_classifier, all_inputs, all_classes, cv=10)
print(cv_scores)
#kde=False
sb.distplot(cv_scores, kde=False)
plt.title('Average score: {}'.format(np.mean(cv_scores)))
[ 1. 0.93333333 1. 0.93333333 0.93333333 0.86666667
0.93333333 0.93333333 1. 1. ]
Text(0.5,1,'Average score: 0.9533333333333334')
decision_tree_classifier = DecisionTreeClassifier(max_depth=1) cv_scores = cross_val_score(decision_tree_classifier, all_inputs, all_classes, cv=10)
print (cv_scores)
sb.distplot(cv_scores, kde=False)
plt.title('Average score: {}'.format(np.mean(cv_scores)))
[ 0.66666667 0.66666667 0.66666667 0.66666667 0.66666667 0.66666667
0.66666667 0.66666667 0.66666667 0.64285714]
Text(0.5,1,'Average score: 0.6642857142857144')
from sklearn.grid_search import GridSearchCV
from sklearn.cross_validation import StratifiedKFold decision_tree_classifier = DecisionTreeClassifier() parameter_grid = {'max_depth': [1, 2, 3, 4, 5],
'max_features': [1, 2, 3, 4]} cross_validation = StratifiedKFold(all_classes, n_folds=10) grid_search = GridSearchCV(decision_tree_classifier,
param_grid=parameter_grid,
cv=cross_validation) grid_search.fit(all_inputs, all_classes)
print('Best score: {}'.format(grid_search.best_score_))
print('Best parameters: {}'.format(grid_search.best_params_))
Best score: 0.9664429530201343
Best parameters: {'max_depth': 3, 'max_features': 3}
grid_visualization = [] for grid_pair in grid_search.grid_scores_:
grid_visualization.append(grid_pair.mean_validation_score) grid_visualization = np.array(grid_visualization)
grid_visualization.shape = (5, 4)
sb.heatmap(grid_visualization, cmap='Blues')
plt.xticks(np.arange(4) + 0.5, grid_search.param_grid['max_features'])
plt.yticks(np.arange(5) + 0.5, grid_search.param_grid['max_depth'][::-1])
plt.xlabel('max_features')
plt.ylabel('max_depth')
Text(45.7222,0.5,'max_depth')
decision_tree_classifier = grid_search.best_estimator_
decision_tree_classifier
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=3,
max_features=3, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
import sklearn.tree as tree
from sklearn.externals.six import StringIO with open('iris_dtc.dot', 'w') as out_file:
out_file = tree.export_graphviz(decision_tree_classifier, out_file=out_file)
#http://www.graphviz.org/
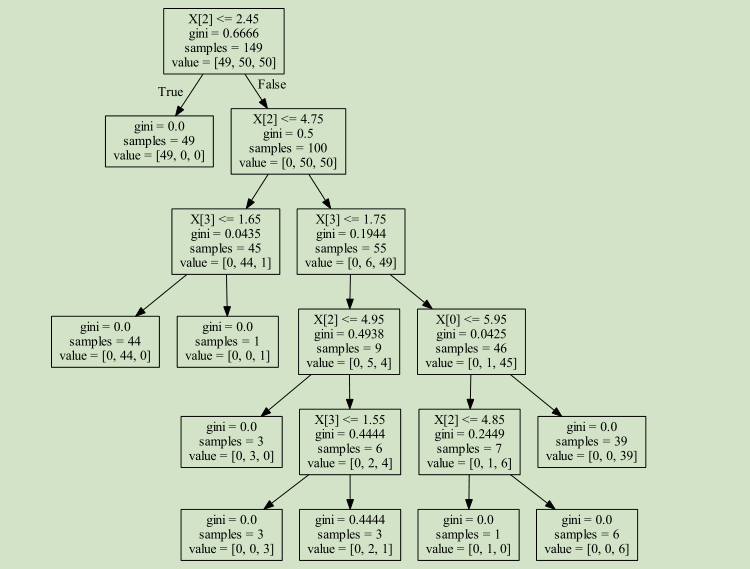
from sklearn.ensemble import RandomForestClassifier
random_forest_classifier = RandomForestClassifier()
parameter_grid = {'n_estimators': [5, 10, 25, 50],
'criterion': ['gini', 'entropy'],
'max_features': [1, 2, 3, 4],
'warm_start': [True, False]}
cross_validation = StratifiedKFold(all_classes, n_folds=10)
grid_search = GridSearchCV(random_forest_classifier,
param_grid=parameter_grid,
cv=cross_validation)
grid_search.fit(all_inputs, all_classes)
print('Best score: {}'.format(grid_search.best_score_))
print('Best parameters: {}'.format(grid_search.best_params_))
grid_search.best_estimator_
Best score: 0.9664429530201343
Best parameters: {'n_estimators': 10, 'max_features': 2, 'criterion': 'gini', 'warm_start': True}
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features=2, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
oob_score=False, random_state=None, verbose=0, warm_start=True)
机器学习算法整理(五)决策树_随机森林——鹃尾花实例 Python实现的更多相关文章
- web安全之机器学习入门——3.2 决策树与随机森林
目录 简介 决策树简单用法 决策树检测P0P3爆破 决策树检测FTP爆破 随机森林检测FTP爆破 简介 决策树和随机森林算法是最常见的分类算法: 决策树,判断的逻辑很多时候和人的思维非常接近. 随机森 ...
- 机器学习算法整理(二)梯度下降求解逻辑回归 python实现
逻辑回归(Logistic regression) 以下均为自己看视频做的笔记,自用,侵删! 还参考了:http://www.ai-start.com/ml2014/ 用梯度下降求解逻辑回归 Logi ...
- R语言︱决策树族——随机森林算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:有一篇<有监督学习选择深度学习 ...
- 常见算法(logistic回归,随机森林,GBDT和xgboost)
常见算法(logistic回归,随机森林,GBDT和xgboost) 9.25r早上面网易数据挖掘工程师岗位,第一次面数据挖掘的岗位,只想着能够去多准备一些,体验面这个岗位的感觉,虽然最好心有不甘告终 ...
- 逻辑斯蒂回归VS决策树VS随机森林
LR 与SVM 不同 1.logistic regression适合需要得到一个分类概率的场景,SVM则没有分类概率 2.LR其实同样可以使用kernel,但是LR没有support vector在计 ...
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- Machine Learning笔记整理 ------ (五)决策树、随机森林
1. 决策树 一般的,一棵决策树包含一个根结点.若干内部结点和若干叶子结点,叶子节点对应决策结果,其他每个结点对应一个属性测试,每个结点包含的样本集合根据属性测试结果被划分到子结点中,而根结点包含样本 ...
- 决策树与随机森林Adaboost算法
一. 决策树 决策树(Decision Tree)及其变种是另一类将输入空间分成不同的区域,每个区域有独立参数的算法.决策树分类算法是一种基于实例的归纳学习方法,它能从给定的无序的训练样本中,提炼出树 ...
随机推荐
- Leetcode题库——27.移除元素
@author: ZZQ @software: PyCharm @file: removeElement.py @time: 2018/9/23 14:04 要求:给定一个数组 nums 和一个值 v ...
- 网络1711-12&信管1711-12 图 作业评分
先放上本次作业的推荐博客,以及评分细则总表,在最后,会放几张图表对本学期大家的成果进行一个小小的总结,有兴趣的同学可以看看,感受一下自己这个学期的积累和进步.(主要针对网络的同学,信管的同学只有两次作 ...
- 深入理解JAVA集合系列一:HashMap源码解读
初认HashMap 基于哈希表(即散列表)的Map接口的实现,此实现提供所有可选的映射操作,并允许使用null值和null键. HashMap继承于AbstractMap,实现了Map.Cloneab ...
- virsh 操作kvm虚拟机
#查看你的硬件是否支持虚拟化.命令: [root@VM_166_143 data]#egrep '(vmx|svm)' /proc/cpuinfo #安装基础包 [root@VM_166_143 da ...
- 【硬件】- 英特尔CPU命名规则
前言 一款Intel CPU的命名,一般由5个部分组成:品牌,品牌标识符,Gen标识,SKU数值,产品线后缀. 以下图为例: 品牌 英特尔旗下处理器有许多子品牌,包括我们熟悉的凌动(ATOM).赛扬( ...
- httpstat的简单使用
httpstat 应该是一个 python 封装后的 curl 工具能够展现 一些客户端连接网站的时间消耗,最近在看tls 感觉挺有用处的 简单学习一下 1. centos7 安装python 和 p ...
- 13个实用的Linux find命令示例
除了在一个目录结构下查找文件这种基本的操作,你还可以用find命令实现一些实用的操作,使你的命令行之旅更加简易. 本文将介绍15种无论是于新手还是老鸟都非常有用的Linux find命令. 首先,在你 ...
- 数组 javaScript权威指南笔记
创建数组 var a=[1,2,3,4] var arr=new Array() var arr=new Array(10);//创建长度为10的数组 var arr=new Array(1,2, ...
- 虚拟机centos 安装 redis 环境 linux 使用 java 远程连接 redis
redis官网地址:http://www.redis.io/ 最新版本:2.8.3 在Linux下安装Redis非常简单,具体步骤如下(官网有说明): 1.下载源码,解压缩后编译源码. $ wget ...
- IE 低版本 透明度
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...