RabbitMQ系列之高可用集群
为了实现高可用,我采用LVS+双节点RabbitMq , 架构图如下:
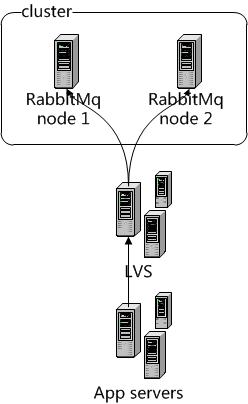
在RabbitMQ之前放了LVS, LVS 采用 rr 轮询算法 , 目的是将请求平均分配到两个真实节点,并配置5672端口监控,异常时转移到另外的节点。
在 ,做完之后测试发现,用上LVS之后,测试会报错,服务器端的队列名称都是一致的,但是队列内容却并不是一致,看来需要做同步。
Rabbit提供镜像功能,需要基于rabbitmq策略来实现,政策是用来控制和修改群集范围的某个vhost队列行为和Exchange行为 :
set_policy [-p vhostpath] {name} {pattern} {definition} [priority]
eg.
rabbitmqctl set_policy ha-allqueue "^" '{"ha-mode":"all"}'
pattern 是匹配队列名称的正则表达式 , 进行区分哪些队列使用哪些策略
definition 其实就是一些arguments, 支持如下参数:
ha-mode:One ofall,exactlyornodes(the latter currently not supported by web UI).ha-params:Absent ifha-modeisall, a number ifha-modeisexactly, or an array of strings ifha-modeisnodes.ha-sync-mode:One ofmanualorautomatic. //如果不指定该参数默认为manual,这个在高可用集群测试的时候详细分析federation-upstream-set:A string; only if the federation plugin is enabled.
ha-mode 的参数:
| ha-mode | ha-params | Result |
|---|---|---|
| all | (absent) | Queue is mirrored across all nodes in the cluster. When a new node is added to the cluster, the queue will be mirrored to that node. |
| exactly | count | Queue is mirrored to count nodes in the cluster. If there are less than count nodes in the cluster, the queue is mirrored to all nodes. If there are more than countnodes in the cluster, and a node containing a mirror goes down, then a new mirror will not be created on another node. (This is to prevent queues migrating across a cluster as it is brought down.) |
| nodes | node names | Queue is mirrored to the nodes listed in node names. If any of those node names are not a part of the cluster, this does not constitute an error. If none of the nodes in the list are online at the time when the queue is declared then the queue will be created on the node that the declaring client is connected to. |
在管理policy的时候WebUI是非常不错:
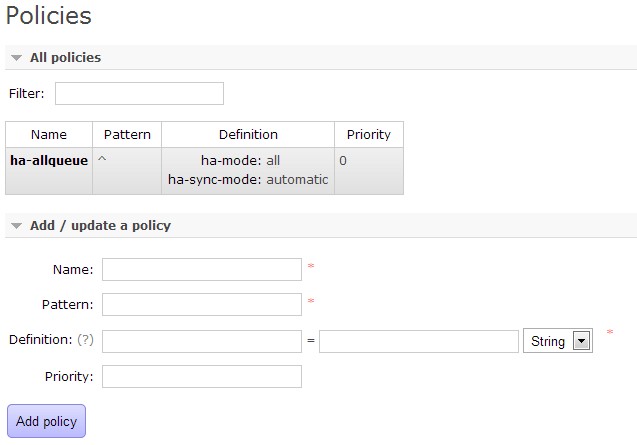
Definition加入两项:
ha-mode:all
ha-sync-mode:automatic
到这里配置已经完成,接下来进行测试。
两个节点之间就会开始同步消息了。
这时借助前面的LVS / HA 就可以使用高可用了 。
RabbitMQ系列之高可用集群的更多相关文章
- (十)RabbitMQ消息队列-高可用集群部署实战
原文:(十)RabbitMQ消息队列-高可用集群部署实战 前几章讲到RabbitMQ单主机模式的搭建和使用,我们在实际生产环境中出于对性能还有可用性的考虑会采用集群的模式来部署RabbitMQ. Ra ...
- rabbitmq+ keepalived+haproxy高可用集群详细命令
公司要用rabbitmq研究了两周,特把 rabbitmq 高可用的研究成果备下 后续会更新封装的类库 安装erlang wget http://www.gelou.me/yum/erlang-18. ...
- rabbitmq安装与高可用集群配置
rabbitmq版本:3.6.12 rabbitmq安装 1.安装openssl wget http://www.openssl.org/source/openssl-1.0.0a.tar.gz &a ...
- rabbitmq+haproxy+keepalived高可用集群环境搭建
1.先安装centos扩展源: # yum -y install epel-release 2.安装erlang运行环境以及rabbitmq # yum install erlang ... # yu ...
- Redis总结(五)缓存雪崩和缓存穿透等问题 Web API系列(三)统一异常处理 C#总结(一)AutoResetEvent的使用介绍(用AutoResetEvent实现同步) C#总结(二)事件Event 介绍总结 C#总结(三)DataGridView增加全选列 Web API系列(二)接口安全和参数校验 RabbitMQ学习系列(六): RabbitMQ 高可用集群
Redis总结(五)缓存雪崩和缓存穿透等问题 前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhon ...
- RabbitMQ学习系列(六): RabbitMQ 高可用集群
前面讲过一些RabbitMQ的安装和用法,也说了说RabbitMQ在一般的业务场景下如何使用.不知道的可以看我前面的博客,http://www.cnblogs.com/zhangweizhong/ca ...
- RabbitMQ从零到集群高可用(.NetCore5.0) -高可用集群构建落地
系列文章: RabbitMQ从零到集群高可用(.NetCore5.0) - RabbitMQ简介和六种工作模式详解 RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列 ...
- rabbitmq+haproxy+keepalived实现高可用集群搭建
项目需要搭建rabbitmq的高可用集群,最近在学习搭建过程,在这里记录下可以跟大家一起互相交流(这里只是记录了学习之后自己的搭建过程,许多原理的东西没有细说). 搭建环境 CentOS7 64位 R ...
- 搭建 RabbitMQ Server 高可用集群
阅读目录: 准备工作 搭建 RabbitMQ Server 单机版 RabbitMQ Server 高可用集群相关概念 搭建 RabbitMQ Server 高可用集群 搭建 HAProxy 负载均衡 ...
随机推荐
- python基础之面向对象02
---继承 当我们定义完成某个类时,可以再定义一个新类,新类可以继承第一个类.新类被称为子类,而被继承的类称为父类/基类/超类. 继承就是子类继承父类的属性和方法(注意是类属性和类方法). 继承可以使 ...
- P3572 [POI2014]PTA-Little Bird
P3572 [POI2014]PTA-Little Bird 一只鸟从1跳到n.从1开始,跳到比当前矮的不消耗体力,否则消耗一点体力,每次询问有一个步伐限制k,求每次最少耗费多少体力 很简短的题目哼. ...
- SpringBoot(十一):Spring boot 中 mongodb 的使用
原文出处: 纯洁的微笑 mongodb是最早热门非关系数据库的之一,使用也比较普遍,一般会用做离线数据分析来使用,放到内网的居多.由于很多公司使用了云服务,服务器默认都开放了外网地址,导致前一阵子大批 ...
- java基础-Integer类常用方法介绍
java基础-Integer类常用方法介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在实际程序使用中,程序界面上用户输入的数据都是以字符串类型进行存储的.而程序开发中,我们需 ...
- 同一个IIS绑定多个Htts 站点问题
默认情况一个服务器的IIS只能绑定一个HTTPS也就是443端口 要实现多个站点对应HTTPS只能更改IIS配置 地址:C:Windowssystem32inetsrvconfigapplicatio ...
- 奇怪的C代码
; int ans = (++i)+(++i)+(++i); ans等于多少?我想大多数同学都会和我一样的认为: ans = 4 + 5 + 6 = 15. 而实际结果呢? - Linux下用gcc编 ...
- ashx误删后,未能创建类型
描述 今天,因为临时有事儿,需要去一趟其他城市,项目比较赶.所以只能在车上继续敲代码,倒霉的触摸板让我误删一个ashx一般处理程序.好死不死的这个文件的代码还很长. 我的做法是[垃圾桶]→[还原]→V ...
- C 语言中指针初始化为字符串常量 不可通过该指针修改其内容
char b[] = "hello"; 则“hello”存于栈中,因为定义的是一个数组. char *b = "hello"; 则"hello&quo ...
- 倍增 Tarjan 求LCA
...
- HTML5之2D物理引擎 Box2D for javascript Games 系列 翻外篇--如何结合createJS应用box2d.js
太久没有更新了,新年回来工作,突然有收到网友的邮件提问,居然还有人在关注,惭愧,找了下电脑上还有一点儿存着,顺便先发这一个番外篇吧,好歹可以看到真实的效果,等我考完英语,一定会更新下一章," ...