流式大数据计算实践(1)----Hadoop单机模式
一、前言
1、从今天开始进行流式大数据计算的实践之路,需要完成一个车辆实时热力图
2、技术选型:HBase作为数据仓库,Storm作为流式计算框架,ECharts作为热力图的展示
3、计划使用两台虚拟机来打一个小型的分布式系统,使用Ubuntu系统
二、HBase简介
1、HBase是基于HDFS(Hadoop分布式文件系统)的NoSQL数据库,采用k-v的存储方式,所以查询速度相对比较快。
2、下面画图比较HBase与传统的RDS(关系型数据库)数据库的区别
(1)RDS,经常用的比如MySQL、SQLServer等数据库,通过指定第几行第几列就可以唯一确定找到数据

(2)HBase
①首先需要指定row key(行键)来找到某一行,row key是一个可以由用户指定的字符串,保证其唯一,排序则是按照字典顺序
②指定column family(列族)找到某个列族,在设计时,官方建议列族设置的越少越好(保证查询速度,并且不容易出bug)
③指定colume(列名)找到某一列,一个列族会有多个列
④指定version来找到cell(单元格,单元格内存放着具体的数据),单元格的目的是为每一列设置多个版本,可以用时间戳代替
综上可以看出,当需要查询一个数据时的表达式应是------(行键:列族:列:版本号),才能唯一确定一个值,当然版本号可以省略,当省略时,默认取最后一个版本的值返回

三、环境搭建
1、首先准备两台Ubuntu虚拟机,我使用的是VirtualBox虚拟机,Ubuntu系统为16.04 x64,并保证其在同一局域网
2、我直接用su切换到root下,方便使用,但要注意不要输错命令
3、安装ssh,用xshell登录方便使用
apt-get install openssh-server
4、集群中机器访问使用主机名访问,所以修改主机名,一台为storm1,一台为storm2,修改完成后需要重启机器生效
vim /etc/hostname storm1 reboot
5、配置hosts文件,保证集群内的机器可以通过主机名找到其他机器
vim /etc/hosts 192.168.3.77 storm1
192.168.3.78 storm2
6、配置SSH免密登录,具体配置参见教程,确保两台机可以互相ssh登录对方
7、安装JDK
(1)下载jdk的tar.gz包,然后解压
tar zxvf jdk-8u191-linux-x64.tar.gz
(2)配置环境变量
vim /etc/profile #set java env
export JAVA_HOME=/work/soft/jdk1.8.0_191
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH source /etc/profile
8、安装Hadoop
(1)搭建单机模式
(2)下载hadoop的tar.gz包,然后解压
(3)配置环境变量(注意默认的JAVA_HOME会报错,所以要改路径)
vim /etc/profile #set hadoop env
export HADOOP_HOME=/work/soft/hadoop-2.6.4
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME export JAVA_HOME=/work/soft/jdk1.8.0_191 source /etc/profile
(3)配置hadoop-env.sh(设置jvm的使用内存和日志文件夹),要记得创建好日志文件夹
vim /work/soft/hadoop-2.6.4/etc/hadoop/hadoop-env.sh export HADOOP_NAMENODE_OPTS=" -Xms1024m -Xmx1024m -XX:+UseParallelGC"
export HADOOP_DATANODE_OPTS=" -Xms1024m -Xmx1024m"
export HADOOP_LOG_DIR=/work/hadoop/logs
(4)配置core-site.xml(配置Hadoop的Web属性 )
vim /work/soft/hadoop-2.6.4/etc/hadoop/core-site.xml <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://storm1:8020</value>
</property>
</configuration>
(5)配置hdfs-site.xml(要记得创建好对应的文件夹,所有的节点的配置文件都是一样设置)
①设置hdfs的数据备份数量
②设置namenode节点存储文件的位置
③设置datanode节点存储文件的位置
vim /work/soft/hadoop-2.6.4/etc/hadoop/hdfs-site.xml <configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///work/hadoop/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///work/hadoop/dn</value>
</property>
</configuration>
(6)格式化namenode
hdfs namenode -format
(7)启动单机模式
$HADOOP_PREFIX/sbin/start-dfs.sh
(8)访问hadoop的控制台http://192.168.3.77:50070/
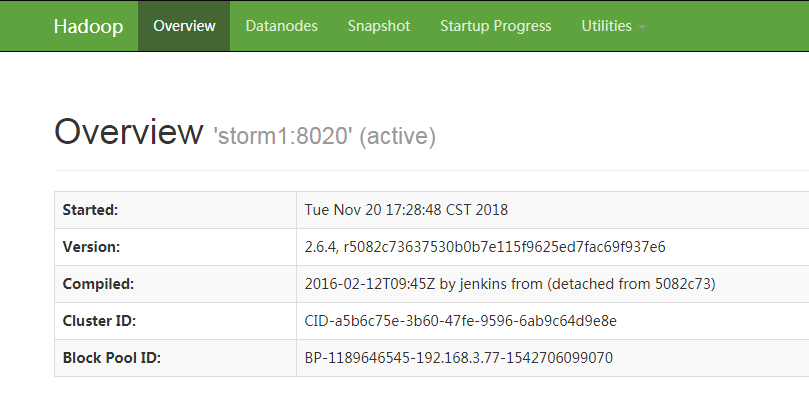
(9)停止单机版集群
stop-dfs.sh
流式大数据计算实践(1)----Hadoop单机模式的更多相关文章
- 流式大数据计算实践(2)----Hadoop集群和Zookeeper
一.前言 1.上一文搭建好了Hadoop单机模式,这一文继续搭建Hadoop集群 二.搭建Hadoop集群 1.根据上文的流程得到两台单机模式的机器,并保证两台单机模式正常启动,记得第二台机器core ...
- 流式大数据计算实践(6)----Storm简介&使用&安装
一.前言 1.这一文开始进入Storm流式计算框架的学习 二.Storm简介 1.Storm与Hadoop的区别就是,Hadoop是一个离线执行的作业,执行完毕就结束了,而Storm是可以源源不断的接 ...
- 流式大数据计算实践(4)----HBase安装
一.前言 1.前面我们搭建好了高可用的Hadoop集群,本文正式开始搭建HBase 2.HBase简介 (1)Master节点负责管理数据,类似Hadoop里面的namenode,但是他只负责建表改表 ...
- 流式大数据计算实践(3)----高可用的Hadoop集群
一.前言 1.上文中我们已经搭建好了Hadoop和Zookeeper的集群,这一文来将Hadoop集群变得高可用 2.由于Hadoop集群是主从节点的模式,如果集群中的namenode主节点挂掉,那么 ...
- 流式大数据计算实践(7)----Hive安装
一.前言 1.这一文学习使用Hive 二.Hive介绍与安装 Hive介绍:Hive是基于Hadoop的一个数据仓库工具,可以通过HQL语句(类似SQL)来操作HDFS上面的数据,其原理就是将用户写的 ...
- 流式大数据计算实践(5)----HBase使用&SpringBoot集成
一.前言 1.上文中我们搭建好了一套HBase集群环境,这一文我们学习一下HBase的基本操作和客户端API的使用 二.shell操作 先通过命令进入HBase的命令行操作 /work/soft/hb ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- 大数据软件安装之Hadoop(Apache)(数据存储及计算)
大数据软件安装之Hadoop(Apache)(数据存储及计算) 一.生产环境准备 1.修改主机名 vim /etc/sysconfig/network 2.修改静态ip vim /etc/udev/r ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
随机推荐
- WPF一组Radio与enum绑定
工作中用到了一组RadioButton对应一组数据的情况,这个时候最好能将一组RadioButton绑定Enum. 步骤 1.MyControl库中Type.cs中定义Enum namespace M ...
- java策略设计模式
1.概述 策略模式定义了一系列的算法,并将每一个算法封装起来,而且使他们可以相互替换,让算法独立于使用它的客户而独立变化. 其实不要被晦涩难懂的定义所迷惑,策略设计模式实际上就是定义一个接口,只要实现 ...
- Codeforces Round #485 (Div. 2) C. Three displays
Codeforces Round #485 (Div. 2) C. Three displays 题目连接: http://codeforces.com/contest/987/problem/C D ...
- 洛谷P2689 东南西北
https://www.luogu.org/problemnew/show/P2689 #include<iostream> #include<algorithm> using ...
- U-Boot Makefile分析(5)主控Makefile分析
这次分析源码根目录下的Makefile,它负责读入配置过的信息,通过OBJS.LIBS等变量设置能够参与镜像链接的目标文件,设定编译的目标等等. HOSTARCH := $(shell uname - ...
- 基础项目构建,引入web模块,完成一个简单的RESTful API 转载来自翟永超
简介 在您第一次接触和学习Spring框架的时候,是否因为其繁杂的配置而退却了?在你第n次使用Spring框架的时候,是否觉得一堆反复粘贴的配置有一些厌烦?那么您就不妨来试试使用Spring Boot ...
- redis在linux云服务器上完整的搭建步骤
Redis的安装 搭建环境: 华为云linux服务器 Linux系统CneterOS-7.3 SSH客户端 Xshell6 安装c语言编译环境软件如下: 安装报错 然后找到了解决方法: 安装kerne ...
- matplotlib&numpy画图
import numpy as np import matplotlib.pyplot as plt x=np.linspace(0,6,100) y=np.cos(2*np.pi*x)*np.exp ...
- C++反汇编(一)
对象/结构体 对象的大小只包括数据成员,成员函数属于执行代码. 对象长度 = sizeof(数据成员1) + sizeof(数据成员2) + ...... + sizeof(数据成员n) 特殊情况公式 ...
- Android学习笔记(1):常用按钮点击事件处理方式
1.从布局文件获取对应的控件然后对其添加点击监听器. Button loginBtn; @Override protected void onCreate(Bundle savedInstanceSt ...