针对特定网站scrapy爬虫的性能优化
在使用scrapy爬虫做性能优化时,一定要根据不同网站的特点来进行优化,不要使用一种固定的模式去爬取一个网站,这个是真理,以下是对58同城的爬取优化策略:
一、先来分析一下影响scrapy性能的settings设置(部分常用设置):
1,DOWNLOAD_TIMEOUT,下载超时,默认180S,若超时则会被retry中间件进行处理,重新加入请求队列
2019-04-18 20:23:18 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET https://bj.58.com/ershoufang/37767297466392x.shtml> (failed 1 times): User timeout caused connection failure: Getting https://bj.58.com/ershoufang/37767297466392x.shtml took longer than 180.0 seconds..
一般来说访问一个网站都是以ms作为单位的,180S确实有些太长了,而且,由于默认设置了最大并发数为16,导致这些request没有下载到东西还一直占据着并发数,在我的日志文件中就能大量看到retry日志
2.DOWNLOAD_DELAY,该选项默认为0,即在下载是并发执行,若设置为x,则每隔 0.5*random~1.5*random 秒下载下一个url,影响当然很大,很多时候还是建议给个正值,避免直接把服务器弄炸了,而且在IP准备不充分情况下,也有利于爬虫的持续运行,对双方都有好处
3.CONCURRENT_REQUESTS ,默认为16,下载器下载的并发数,建议调高,根据scrapy发挥到cpu核心性能80~90%取适应值,若服务器有反爬措施,自身准备IP又不充足情况下,建议调低;
scrapy 是基于 twisted 的异步 IO,只用到单线程,若考虑部署一台服务器专用于爬虫,请选择更高的单核性能,关于scrapy单线程的证明:
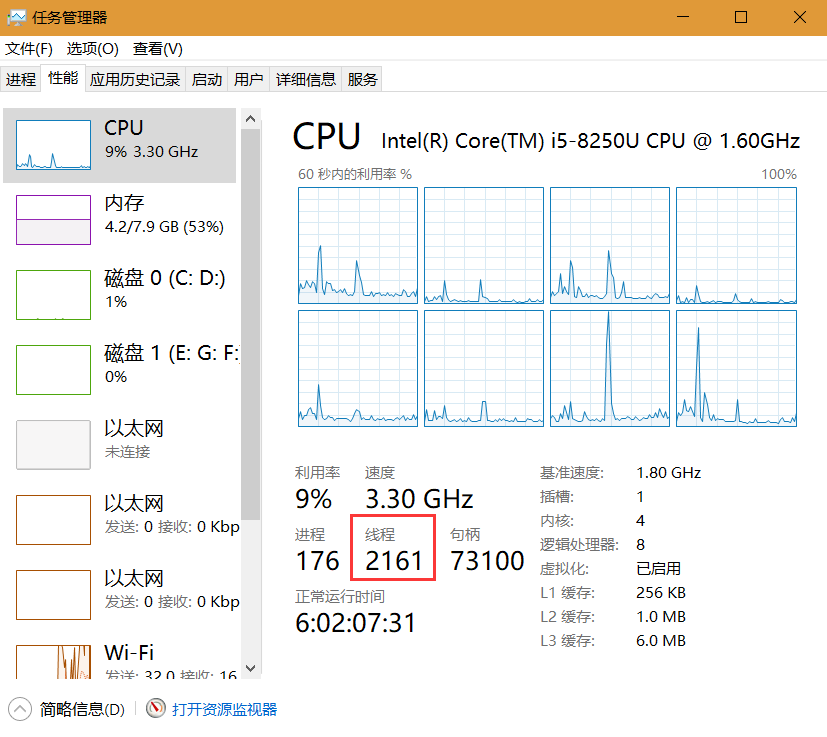
设置CONCURRENT_REQUESTS=100,让scrapy爬取一个超过100个链接的页面,检测下载前后线程数量,windows上直接在任务管理器就能看到了,没有放对比图,就我的观测来看,爬取前后线程数量是没有增加的
4.CONCURRENT_REQUESTS_PER_IP ,下载器下载时针对每个IP的并发数,默认是0,这里0指不限制的意思,取值视IP充足情况和CONCURRENT_REQUESTS决定,若DOWNLOAD_DELAY非零,搭配使用可以实现针对IP做并发下载的download_delay,如CONCURRENT_REQUESTS=16,CONCURRENT_REQUESTS_PER_IP =3,DOWNLOAD_DELAY = 2
当前下载器正在并发下载16个Request,ip:https://201.182.248.10:8080被随机分配到4个Request中,那么有一个使用这个ip代理Request从下载队列中出局,并且在2秒钟内下一个Request携带的代理仍是这个ip时,仍然会被出局,这还是我的一个猜想,有空做一个合适的模型证明一下。
二、优化方案
在执行以下每个策略之前都会清除掉上一次保存在数据库中的item,并且重新获取一定数量的优秀代理供使用,这次优化评判标准是爬取到50条ITEM,比较哪种设置的爬虫用到的时间更短,
初始设置:
CLOSESPIDER_ITEMCOUNT = 50
DOWNLOAD_DELAY=0.5
CONCURRENT_REQUESTS = 16
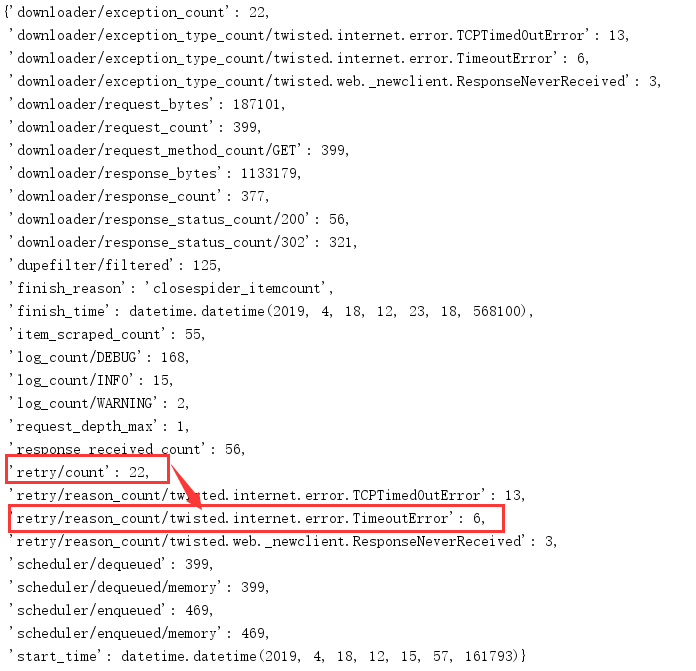
结果:

用时:7分21秒
策略1:比原设置更少的DOWNLOAD_TIMEOUT
设置:
CLOSESPIDER_ITEMCOUNT = 50
DOWNLOAD_DELAY=0.5
CONCURRENT_REQUESTS = 16
DOWNLOAD_TIMEOUT = 15
结果:

用时:2分20秒
结果分析:更少的DOWNLOAD_TIMEOUT换来更多的重试次数,但是由于下载超时大大减少,使scrapy性能大大提升。这个结果同时提供一种后续继续优化思路:逐渐减小DOWNLOAD_TIMEOUT的值,使得爬虫用时减少而重试次数增加的较慢,那么这应该就是一个合适的DOWNLOAD_TIMEOUT取值
策略2:比策略1更少的DOWNLOAD_DELAY,直接注释,使用默认0延迟
设置:
CLOSESPIDER_ITEMCOUNT = 50
#DOWNLOAD_DELAY=0.5
CONCURRENT_REQUESTS = 16
DOWNLOAD_TIMEOUT = 15
结果:
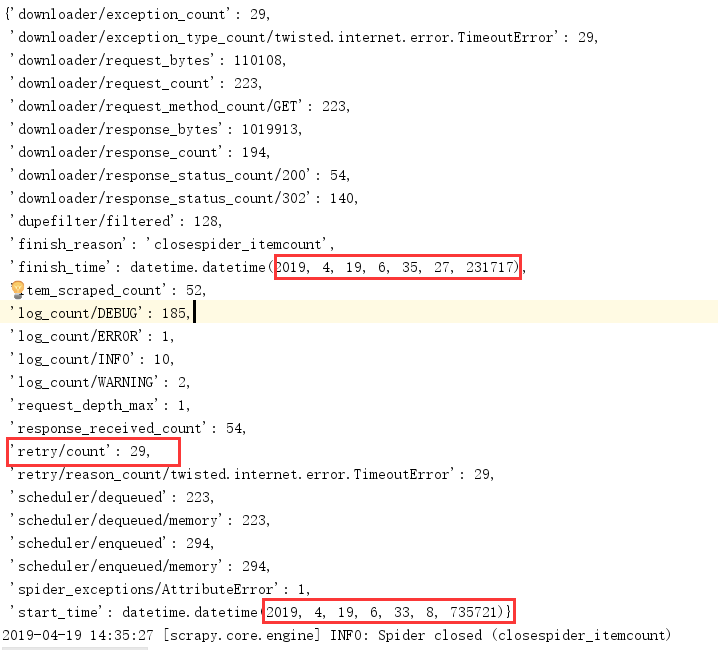
用时:2分19秒
结果分析:似乎和策略1结果差别不大,应该是策略1中设置的TIMEOUT_DELAY较小,在我把策略1换更大的TIMEOUT_DELAY之后,爬取用了10多分钟,后来没等,直接关闭了,就没上结果图片了。
策略3:提供比策略2更大的CONCURRENT_REQUESTS
设置:
CLOSESPIDER_ITEMCOUNT = 50
#DOWNLOAD_DELAY=0.5
CONCURRENT_REQUESTS = 50
DOWNLOAD_TIMEOUT = 15
结果:
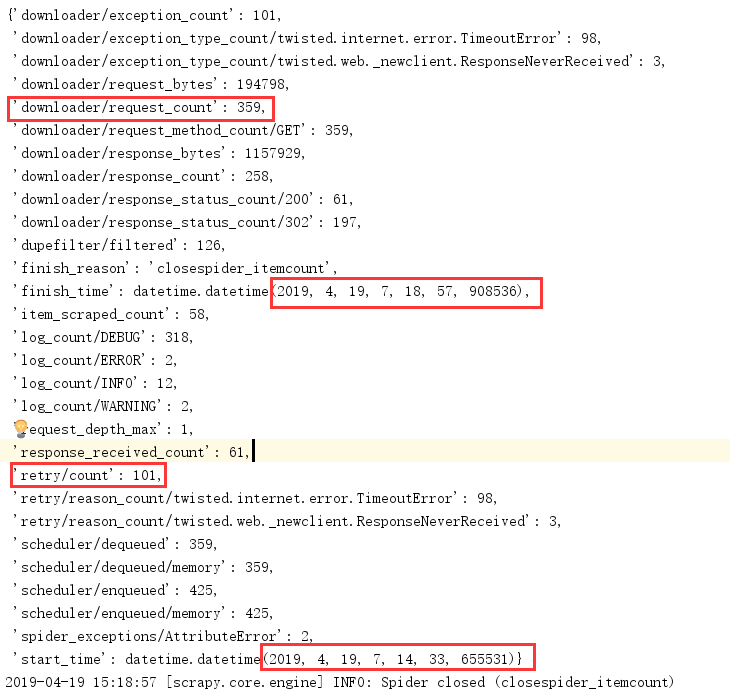
用时:4分25秒
结果分析:这和前面的scrapy性能分析完全不符,并发数越大应该爬取速度更快才对,现在用了原来近2倍时间。来分析一下原因,可以看到,对比策略2的日志图片,策略3请求数量明显增大,223 -- >318,重试次数也明显增大,29->101,并且,此项目中使用的ip都是从本地文件中的ip随机获得的,且并没有在获取一个ip之后删除掉这个ip,可以这样分析:并发增多 -- >携带同一ip的并发请求也增多 -- > 被ban的ip也会增多 --> redirect到firewall的请求增多 -- > Request数量增多 --> retry数量增多,这样很好解释了日志中的结果。这个结果同时提供我们启示:要想增大并发数以提高爬虫效率,必须保证单次请求IP更高有效性,为了解决这个问题,后面我会借鉴git大神写的Flask线程池,提高单次请求成功率。
策略4:CONCURRENT_REQUESTS_PER_IP,对ip做并发限制
CLOSESPIDER_ITEMCOUNT = 50
#DOWNLOAD_DELAY=0.5
CONCURRENT_REQUESTS = 16
CONCURRENT_REQUESTS_PER_IP = 1
DOWNLOAD_TIMEOUT = 15
结果:
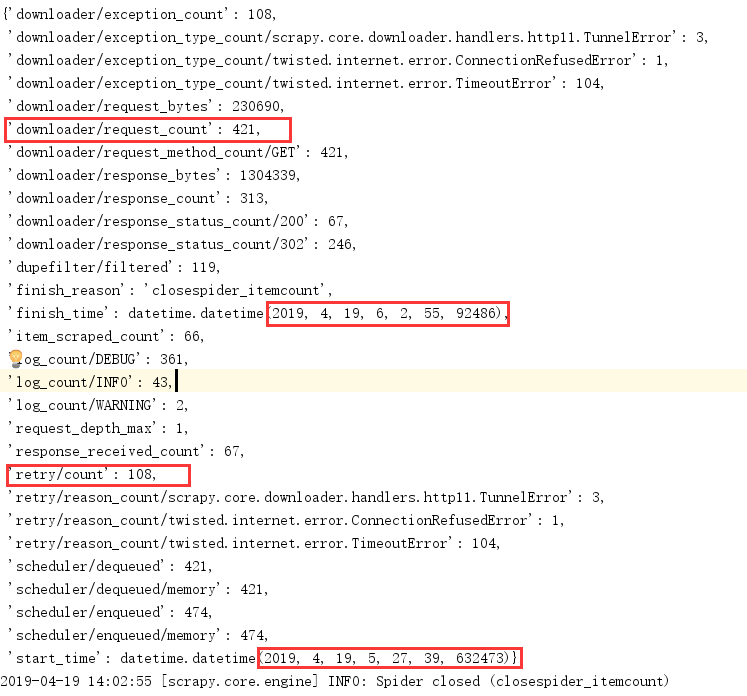
用时:35分16秒
结果分析:scrapy对使用相同ip的并发请求的处理机制对这个结果有一定影响,更加根本原因还是和策略3一样,源于ip有效性较差,下篇我将会使用flask搭建线程池以比较这四种策略的性能差异
总结:
从本例看,策略1应该就是最好的方案了,在允许少量下载延迟的情况下,也不需要大并发,照样提供更好的性能,这也正如开头所说的,对scrapy做性能优化还是要针对具体项目,具体条件。
针对特定网站scrapy爬虫的性能优化的更多相关文章
- Angular 的性能优化
目录 序言 变更检查机制 性能优化原理 性能优化方案 小结 参考 序言 本文将谈一谈 Angular 的性能优化,并且主要介绍与运行时相关的优化.在谈如何优化之前,首先我们需要明确什么样的页面是存在性 ...
- Web前端性能优化教程05:网站样式和脚本
本文是Web前端性能优化系列文章中的第五篇,主要讲述内容:网站样式和脚本代码的放置位置.使用外部javascript和css.完整教程可查看:Web前端性能优化 一.将样式表放在顶部 可视性回馈的重要 ...
- 网站性能优化(Yahoo 35条)
Yahoo 网站性能优化 35条 一.内容部分 尽量减少 HTTP请求 减少 DNS查找 避免跳转 缓存 Ajxa 推迟加载 提前加载 减少 DOM元素数量 用域名划分页面内容 使 frame数量最少 ...
- Yahoo团队经验:网站性能优化的34条黄金法则
Yahoo团队总结的关于网站性能优化的经验,非常有参考价值.英文原文:http://developer.yahoo.com/performance/rules.html 1.尽量减少HTTP请求次数 ...
- Yahoo网站性能优化的34条军规
1.尽量减少HTTP请求次数 终端用户响应的时间中,有80%用于下载各项内容,这部分时间包括下载页面中的图像.样式表.脚本.Flash等.通过减少页面中的元素可以减少HTTP请求的次数,这是提高网页速 ...
- Yahoo网站性能优化的34条规则
摘自:http://blog.chinaunix.net/uid/20714478/cid-74195-list-1.html Yahoo网站性能优化的34条规则 1.尽量减少HTTP请求次数 终端用 ...
- input屏蔽历史记录 ;function($,undefined) 前面的分号是什么用处 JSON 和 JSONP 两兄弟 document.body.scrollTop与document.documentElement.scrollTop兼容 URL中的# 网站性能优化 前端必知的ajax 简单理解同步与异步 那些年,我们被耍过的bug——has
input屏蔽历史记录 设置input的扩展属性autocomplete 为off即可 ;function($,undefined) 前面的分号是什么用处 ;(function($){$.ex ...
- Yahoo! 35条网站性能优化建议
Yahoo! 35条网站性能优化建议 Yahoo!的 Exceptional Performance团队为改善 Web性能带来最佳实践.他们为此进行了一系列的实验.开发了各种工具.写了大量的文章和博客 ...
- HTML5前端(移动端网站)性能优化指南
HTML5是一种最新发布网页构架的普遍模型,是构建对程序.对用户都更有价值的数据驱动的Web的前端技术框架,它的价值在于融合CSS/javaScript/flash等众多前端开发技术,更多的体现在对交 ...
随机推荐
- note 7 递归函数
递归:程序调用自身 形式:在函数定义有直接或间接调用自身 阶乘:N!=123...N def p(n): x = 1 i = 1 while i <= n: x = x * i i = i + ...
- SQL中的排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介
排名函数是Sql Server2005新增的功能,下面简单介绍一下他们各自的用法和区别. 在使用排名函数的时候需要注意以下三点: 1.排名函数必须有 OVER 子句. 2.排名函数必须有包含 ORDE ...
- 去除 ServiceStack.Redis 的6000次限制。
方法一. 下载 https://github.com/ServiceStack/ServiceStack.Text 修改LicenseUtils.cs文件中的AssertValidUsage var ...
- 团队第七次 # scrum meeting
github 本此会议项目由PM召开,召开时间为4-11日晚上9点,以大家在群里讨论为主 召开时长10分钟 任务表格 袁勤 负责协调前后端 https://github.com/buaa-2016/p ...
- Solr中的group与facet的区别
Solr中的group与facet的区别 如果是简单的使用的话,那么Facet与group都可以用来进行数据的聚合查询,但是他们还是有很大的区别的. 首先上facet跟group的操作: Facet的 ...
- mosquitto broker 安装服务后启动失败
一.失败原因 由于做项目用到Mqtt协议,需要安装mosquitto broker 服务,在自己本地笔记本电脑安装后直接启动服务是可以的.后来部署到服务器启动,报错缺少msvcr100.dll ,由于 ...
- mysql导入excel表格
https://jingyan.baidu.com/album/fc07f9891cb56412ffe5199a.html?picindex=1
- 关于C#关闭窗体后,依旧有后台进程在运行的解决方法
http://www.cnblogs.com/HappyEDay/p/5713707.html 这里粘贴原文权当备份了. C#中WinForm程序退出方法技巧总结 一.关闭窗体 在c#中退出WinFo ...
- 2018-2019-2 网络对抗技术 20165304 Exp4 恶意代码分析
2018-2019-2 网络对抗技术 20165304 Exp4 恶意代码分析 原理与实践说明 1.实践目标 监控你自己系统的运行状态,看有没有可疑的程序在运行. 分析一个恶意软件,就分析Exp2或E ...
- C# Func与Action
Func与Action是C#的内置委托,在使用委托时,可不必再定义. (1)Func:有返回类型的委托. Func类型的委托,肯定有一个返回类型,如果Func只有一个参数,那么它就是代表没有参数但是有 ...