2.02_Python网络爬虫分类及其原理
一:通用爬虫和聚焦爬虫
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种.
通用爬虫
通用网络爬虫是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
通用搜索引擎(Search Engine)工作原理
通用网络爬虫 从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因
此其性能的优劣直接影响着搜索引擎的效果。
第一步:抓取网页
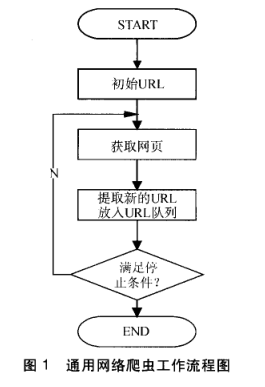
搜索引擎网络爬虫的基本工作流程如下:
首先选取一部分的种子URL,将这些URL放入待抓取URL队列;
取出待抓取URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,并且将这些URL放进已抓取URL队列。
分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环....
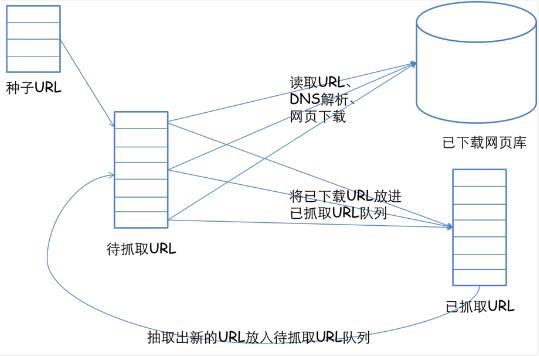
搜索引擎如何获取一个新网站的URL:
1. 新网站向搜索引擎主动提交网址:(如百度http://zhanzhang.baidu.com/linksubmit/url)
2. 在其他网站上设置新网站外链(尽可能处于搜索引擎爬虫爬取范围)
3. 搜索引擎和DNS解析服务商(如DNSPod等)合作,新网站域名将被迅速抓取。
但是搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容,如标注为nofollow的链接,或者是Robots协议。
Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
第二步:数据存储
搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。
搜索引擎蜘蛛在抓取页面时,也做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
第三步:预处理
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。
- 提取文字
- 中文分词
- 消除噪音(比如版权声明文字、导航条、广告等……)
- 索引处理
- 链接关系计算
- 特殊文件处理
- ....
除了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。
但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序。
第四步:提供检索服务,网站排名
搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户。
同时会根据页面的PageRank值(链接的访问量排名)来进行网站排名,这样Rank值高的网站在搜索结果中会排名较前,当然也可以直接使用 Money 购买搜索引擎网站排名,简单粗暴。
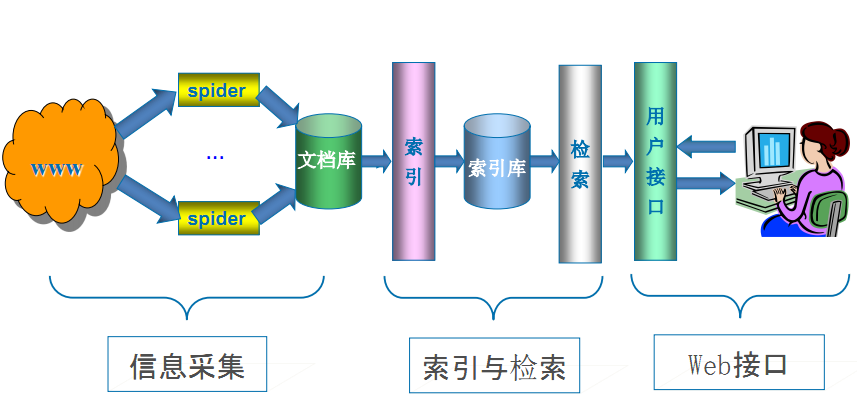
但是,这些通用性搜索引擎也存在着一定的局限性:
通用搜索引擎所返回的结果都是网页,而大多情况下,网页里90%的内容对用户来说都是无用的。
不同领域、不同背景的用户往往具有不同的检索目的和需求,搜索引擎无法提供针对具体某个用户的搜索结果。
万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎对这些文件无能为力,不能很好地发现和获取。
通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询,无法准确理解用户的具体需求。
针对这些情况,聚焦爬虫技术得以广泛使用。
聚焦爬虫
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
2.02_Python网络爬虫分类及其原理的更多相关文章
- 使用Java实现网络爬虫
网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本. 另外一些不常使用的名字还有蚂蚁.自动索引.模 ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
- 网络爬虫框架Scrapy简介
作者: 黄进(QQ:7149101) 一. 网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本:它是一个自动提取网页的程序,它为搜索引擎从万维 ...
- 关于使用Java实现的简单网络爬虫Demo
什么是网络爬虫? 网络爬虫又叫蜘蛛,网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直 ...
- Atitit.数据检索与网络爬虫与数据采集的原理概论
Atitit.数据检索与网络爬虫与数据采集的原理概论 1. 信息检索1 1.1. <信息检索导论>((美)曼宁...)[简介_书评_在线阅读] - dangdang.html1 1.2. ...
- Java 网络爬虫获取网页源代码原理及实现
Java 网络爬虫获取网页源代码原理及实现 1.网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL ...
- Atitit 网络爬虫与数据采集器的原理与实践attilax著 v2
Atitit 网络爬虫与数据采集器的原理与实践attilax著 v2 1. 数据采集1 1.1. http lib1 1.2. HTML Parsers,1 1.3. 第8章 web爬取199 1 2 ...
- [C#搜片神器] 之P2P中DHT网络爬虫原理
继续接着上一篇写:使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器] 昨天由于开源的时候没有注意运行环境,直接没有考虑下载BT种子文件时生成子文件夹,可能导致有的朋友运行 ...
- 一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助. 1.Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且 ...
随机推荐
- Docker使用Portainer搭建可视化界面
Portainer介绍 Portainer是Docker的图形化管理工具,提供状态显示面板.应用模板快速部署.容器镜像网络数据卷的基本操作(包括上传下载镜像,创建容器等操作).事件日志显示.容器控制台 ...
- FPGA回忆记事(一):基于Nios II的LED实验
实验一:基于Nios II的LED实验 一. 创建Quartus II工程 1.打开Quartus II环境.开始->程序->Altera->Quartus II 9.1. 2 ...
- modbus4j中使用modbus tcp/ip和modbus rtu over tcp/ip模式
通过借鉴高人博客,总结如下: 1. TcpMaster类,用于生成ModbusMaster主类 package sun.sunboat; public class TcpMaster { privat ...
- MyBatis使用技巧、总结、注意事项
目录 1.mybatis的官方文档地址 2.其他技巧: 2.1 如何在代码中拼接 like %% 2.2 数据库比较时日期的错误操作 2.2.1 异常情况: 2.2.2 为什么会在后面指定jdbcTy ...
- java实现List<People>的排序
1.首先新建测试的实体类(People类): import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsCon ...
- POJ1149 PIGS 【最大流 + 构图】
题目链接:http://poj.org/problem?id=1149 PIGS Time Limit: 1000MS Memory Limit: 10000K Total Submissions ...
- (模板)poj3461(kmp模板题)
题目链接:https://vjudge.net/problem/POJ-3461 题意:给出主串和模式串,求出模式串在主串中出现的次数. 思路:kmp板子题. AC代码: #include<cs ...
- SpringBoot起步
1.SpringBoot依赖包导入 方式一:将spring-boot的依赖为父pom出现 <parent> <groupId>org.springframework.boot& ...
- css 颜色自动变化 炫彩
.layui-icon-login-qq:hover{ color:rgb(0, 156, 255); transition: 0.5s; animation:change 10s linear 0s ...
- Python何时执行装饰器
装饰器的一个关键特性是,它们在被装饰的函数定义之后立即运行.这 通常是在导入时(即 Python 加载模块时),如示例 7-2 中的 registration.py 模块所示. 示例 7-2 regi ...