NLP学习(1)---Glove模型---词向量模型
一、简介:
1、概念:glove是一种无监督的Word representation方法。
Count-based模型,如GloVe,本质上是对共现矩阵进行降维。首先,构建一个词汇的共现矩阵,每一行是一个word,每一列是context。共现矩阵就是计算每个word在每个context出现的频率。由于context是多种词汇的组合,其维度非常大,我们希望像network embedding一样,在context的维度上降维,学习word的低维表示。这一过程可以视为共现矩阵的重构问题,即reconstruction loss。(这里再插一句,降维或者重构的本质是什么?我们选择留下某个维度和丢掉某个维度的标准是什么?Find the lower-dimensional representations which can explain most of the variance in the high-dimensional data,这其实也是PCA的原理)。
2、优点:充分有效的利用了语料库的统计信息,仅仅利用共现矩阵里面的非零元素进行训练,而skip-gram没有很有效的利用语料库中的一些统计信息。
3、发展过程:
词向量详细推导:https://blog.csdn.net/liuy9803/article/details/86592392
(1)one-hot:
词向量的维数为整个词汇表的长度,对于每个词,将其对应词汇表中的位置置为1,其余维度都置为0。
缺点是:
- 维度非常高,编码过于稀疏,易出现维数灾难问题;
- 不能体现词与词之间的相似性,每个词都是孤立的,泛化能力差。

(2)向量空间模型VSM:
定义:在给定文档集合C和词典D的条件下,将某篇文档通过词袋模型表示成一个个的词,而后根据 TF-IDF 为每个词计算出一个实数值;
由于词典D的大小为M,因此将这篇文档转化成一个M维向量,如果词典中某个词未出现在文档中,则这个词的在向量中对应的元素为0,若某个词出现在文档中,则这个词在向量中对应的元素值为这个词的tf-idf值。这样,就把文档表示成向量了,而这就是 向量空间模型(vector space model)。
而有了文档向量,也就可以用余弦公式计算文档之间的相似度了。
缺点:
- 相对于onehot加入了tf-idf等信息,但向量空间模型并没有catch住词(term)与词(term)之间的关系,它假设各个term之间是相互独立的。一些上下文信息丢失。
- 在实际应用中,我们并不是直接使用 TF*IDF 这个理论模型,因为它计算出来的权重偏向于短文本,因此需要某种平滑。
举个例子来说,term1在docA中出现了3次,term2在docA中出现了9次,根据上面计算TF的方式,意味着:term2的tf权重(或者说重要性)比term1要大3倍,那真的是重要3倍么?因此,在Lucene的实际评分模型中,计算的是sqrt(tf),即通过 tf 开根号,起到一定的平滑作用。类似地,计算 idf 时,是取log对数,也是为了平滑。
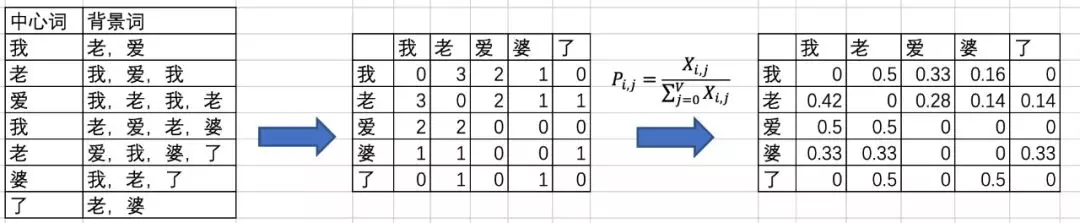
词向量空间模型的主要思路是出现在类似的上下文环境中的单词在语义上很可能相似。例如,假如我们发现,“咖啡”和“喝”经常同时出现,另一方面,“茶”和“喝”也经常同时出现,那么我们可以推测“咖啡”和“茶”在语义上应该是相似的。则词向量维度为总上下文的词数量。【但如果词料数量很多,则会产生维度过高的问题】
(3)词嵌入:
神经网络将词汇表中的词作为输入,输出一个低维的向量表示,然后使用BP优化参数。
生成词向量的神经网络模型分为两种:
- 一种的目的是训练可以表示语义关系的词向量,能被用于后续任务中,如word2vec;
- 另一种是将词向量作为副产品产生,根据特定任务需要训练得到词向量,如fastText。
①学习的概率分布
Word2Vec:【其输出是单词同时出现的概率分布】
GLove:【相比单词同时出现的概率,单词同时出现的概率的比率能够更好地区分单词。】
比如,假设我们要表示“冰”和“蒸汽”这两个单词。对于和“冰”相关,和“蒸汽”无关的单词,比如“固体”,我们可以期望P冰-固体/P蒸汽-固体较大。类似地,对于和“冰”无关,和“蒸汽”相关的单词,比如“气体”,我们可以期望P冰-气体/P蒸汽-气体较小。相反,对于像“水”之类同时和“冰”、“蒸汽”相关的单词,以及“时尚”之类同时和“冰”、“蒸汽”无关的单词,我们可以期望P冰-水/P蒸汽-水、P冰-时尚/P蒸汽-时尚应当接近于1。
②目标函数:最小二乘
Word2Vec:【Word2Vec中隐藏层没有使用激活函数,这就意味着,隐藏层学习的其实是线性关系。】
GLove:【隐藏层使用比神经网络更简单的模型】
词向量是无监督学习少数几个成功的应用之一,优势在于不需要人工标注语料,直接使用未标注的文本训练集作为输入,输出的词向量可以用于下游业务的处理。
③优点:
- 词向量是无监督学习少数几个成功的应用之一,优势在于不需要人工标注语料,直接使用未标注的文本训练集作为输入,输出的词向量可以用于下游业务的处理。
- 词向量用于迁移学习:
(1)使用大的语料库训练词向量(或网上下载预训练好的词向量);
(2)将词向量模型迁移到只有少量标注的训练集任务中;
(3)用新的数据微调词向量(如果新的数据集不大,则这一步不是必须的)。
- 词维度降低
虽然词向量是神经网络的输入,但并非第一层输入。第一层是词的one-hot编码,乘以一个权重矩阵后得到才是词向量化表示,而权重在模型训练阶段是可以更新的。
二、模型



推导过程:






三、Glove和skip-gram、CBOW模型对比
Cbow/Skip-Gram 是一个local context window的方法,比如使用NS来训练,缺乏了整体的词和词的关系,负样本采用sample的方式会缺失词的关系信息。
另外,直接训练Skip-Gram类型的算法,很容易使得高曝光词汇得到过多的权重
Global Vector融合了矩阵分解Latent Semantic Analysis (LSA)的全局统计信息和local context window优势。融入全局的先验统计信息,可以加快模型的训练速度,又可以控制词的相对权重。
我的理解是skip-gram、CBOW每次都是用一个窗口中的信息更新出词向量,但是Glove则是用了全局的信息(共线矩阵),也就是多个窗口进行更新
https://blog.csdn.net/u012879957/article/details/82735057
两者最直观的区别在于,word2vec是“predictive”的模型,而GloVe是“count-based”的模型。具体是什么意思呢?
不采用 negative sampling 的word2vec 速度非常快,但是准确率仅有57.4%。
- 只告诉模型什么是有关的,却不告诉它什么是无关的,模型很难对无关的词进行惩罚从而提高自己的准确率
- 在python的gensim这个包里,gensim.models.word2vec.Word2Vec默认是不开启negative sampling的,需要开启的话请设置negative参数,如何设置文档中有明确说明gensim: models.word2vec
- 当使用了negative sampling之后,为了将准确率提高到68.3%,word2vec就需要花较长的时间了(8h38m)
相比于word2vec,因为golve更容易并行化,所以速度更快,达到67.1%的准确率,只需要花4h12m。
由于GloVe算法本身使用了全局信息,自然内存费的也就多一些,相比之下,word2vec在这方面节省了很多资源
performance上差别不大。
两个模型在并行化上有一些不同,即GloVe更容易并行化,所以对于较大的训练数据,GloVe更快。
四、源码理解:
https://blog.csdn.net/weixin_36711901/article/details/78508798
https://github.com/stanfordnlp/GloVe/tree/master/src
https://zhuanlan.zhihu.com/p/28613493
参考:https://blog.csdn.net/u014665013/article/details/79642083
http://zh.gluon.ai/chapter_natural-language-processing/glove.html
http://www.pengfoo.com/post/machine-learning/2017-04-11
https://www.jianshu.com/p/d0d5a828bcaa
NLP学习(1)---Glove模型---词向量模型的更多相关文章
- NLP教程(2) | GloVe及词向量的训练与评估
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- 词袋模型(BOW,bag of words)和词向量模型(Word Embedding)概念介绍
例句: Jane wants to go to Shenzhen. Bob wants to go to Shanghai. 一.词袋模型 将所有词语装进一个袋子里,不考虑其词法和语序的问题,即每个 ...
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- 词袋模型bow和词向量模型word2vec
在自然语言处理和文本分析的问题中,词袋(Bag of Words, BOW)和词向量(Word Embedding)是两种最常用的模型.更准确地说,词向量只能表征单个词,如果要表示文本,需要做一些额外 ...
- 关于Google词向量模型(googlenews-vectors-negative300.bin)的导入问题
起因 项目中有如下代码: word2vec = KeyedVectors.load_word2vec_format('./GoogleNews-vectors-negative300.bin', bi ...
- 学习笔记TF018:词向量、维基百科语料库训练词向量模型
词向量嵌入需要高效率处理大规模文本语料库.word2vec.简单方式,词送入独热编码(one-hot encoding)学习系统,长度为词汇表长度的向量,词语对应位置元素为1,其余元素为0.向量维数很 ...
- NLP学习(2)----文本分类模型
实战:https://github.com/jiangxinyang227/NLP-Project 一.简介: 1.传统的文本分类方法:[人工特征工程+浅层分类模型] (1)文本预处理: ①(中文) ...
- 自然语言处理词向量模型-word2vec
自然语言处理与深度学习: 语言模型: N-gram模型: N-Gram模型:在自然语言里有一个模型叫做n-gram,表示文字或语言中的n个连续的单词组成序列.在进行自然语言分析时,使用n-gram或者 ...
随机推荐
- VMware VSAN 设计规则
1.集群节点数量:3-64台主机(生产环境最少4节点起,5.5版本支持32节点,6.0版本支持64节点),配置万兆网卡,主机规格应满足VSAN兼容性要求. 2.每台主机需配置磁盘组,每台主机的磁盘组数 ...
- python 创建虚拟环境(virtualenv)
原文地址:https://www.jianshu.com/p/2645d8f2e690 另附连接:Linux环境下虚拟环境virtualenv安装和使用 virtualenv 安装 1.Install ...
- Spring 使用日志
1. spring boot项目默认使用什么技术处理日志? 实例代码 log.debug("===============================用户信息:", user) ...
- Vue 拖拽组件 vuedraggable 、 vue-dragging 、awe-dnd
参考链接:http://www.ptbird.cn/vue-draggable-dragging.html vue-draggable 学习和使用:https://www.jianshu.com/p/ ...
- FromServices回来
FromServices回来 起因 这两天,我忽然有点怀念 Asp.NET MVC 5 之前的时代,原因是我看到项目里面有这么一段代码(其实不止一段,几乎每个 Controller 都是) [Rout ...
- 在vue中使用axios发送post请求,参数方式
由于后台接收的参数格式为FormData格式, 在axios中参数格式默认为, 在传参数前,将原先官方提供的格式 改为如下: axios({ url: '../../../room/listRoomP ...
- 表单绑定 v-model
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- 封装Json+日志
/** * 输出json * @param $msg * @param int $errno */ public function printOutError($msg = '操作失败', $errn ...
- Available time
Google Calendar, Outlook, iCal has been banned from your company! So an intrepid engineer has decide ...
- VC++:创建,调用MFC动态链接库(扩展DLL)
概述 DLL(Dynamic Linkable Library)动态链接库,Dll可以看作一种仓库,仓库中包含了可以直接使用的变量,函数或类. 仓库的发展史经历了"无库" ---& ...