Solr7使用Oracle数据源导入+中文分词
安装目录假设为#solr_home,本文的#solr_home为apps/svr/solr
一、Oracle数据导入
1. 在#solr_home/server/solr下新建文件夹,假设为mjd;
2. 将#solr_home/server/solr/configsets/_default下的conf文件夹拷贝到#solr_home/server/solr/mjd;
3.打开mjd/conf下的solrconfig.xml添加节点;
<lib dir="${solr.install.dir:../../../..}/contrib/dataimporthandler/" regex=".*\.jar">
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar">
4. 同样上面那个文件,增加节点;
<requestHandler name="/dataimport" class="org.apche.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</list>
</requestHandler>
5. 下载ojdbc6.jar到#solr_home/contrib/dataimporthandler/中,我是在http://vdisk.weibo.com/s/z8ZZMoqsgpNFH中下载的;
6. 在#solr_home/server/solr/mjd/conf下新建文件data-config.xml,打开,将下列配置复制;
<dataConfig>
<dataSource driver="oracle.jdbc.driver.OracleDriver" url="jdbc:oracle:thin:@192.168.2.218:1521:product " user="数据库用户名" password="数据库密码" />
<document name=”product” pk=”主键”>
<entity name="bless" query="select * from bless"<--这里配查询语句-->
deltaImportQuery="SELECT * FROM userinfo where spuid='${dih.delta.spuid}'"
deltaQuery="select bless_id from bless where bless_time > '${dataimporter.last_index_time}'"><--这里配增量查询语句,${dataimporter.last_index_time}表示上次更新时间-->
</entity>
</document>
</dataConfig>
7. 进入web管理页面 localhost:8983/solr/#,点击Core Admin菜单,点击AddCore,将name和instanceDir设置为刚才我们第一步新建的文件夹名称;
8. 在菜Thread Dump下方有一个下拉框,选择刚新建的Core,点击Schema 里的Add field菜单,name输入刚才配置的查询语句中的某个字段(假设该字段为字符串类型),点击field type,选择text_gerneral,点击下面的添加按钮;
9. 回到左侧菜单,选择Dataimport,点击Execute菜单;
10. 回到左侧菜单,选择Query,点击Execute Query,如果右侧查询出数据,恭喜你,你已经配置好了;
可根据第八步继续添加自己想要的字段,重复9 10步骤;
二、中文分词
Solr7之前好像大部分使用的是IK中文分词器,但是我试了好几个方法,都没有成功,而且跟网上经验描述的目录结构也很多不一样,比如大部分说要修改Schema.xml文件,可是后来发现Solr7其实已经不使用Schema了,而是使用的Managed-Schema文件,
而且这里有个问题就是,当重启Solr服务器后,项目中的这个文件会被覆盖掉,目前还没有找到是从哪里拷贝过来的模板。进入正题:
1. 进入#solr_home/contrib/analysis-extras/lucene-libs,找到lucene-analyzers-smartcn-7.0.1.jar,复制到#solr_home/server/solr-webapp/webapp/WEB-INF/lib下;
2. 打开#solr_home/server/solr/configsets/_default/conf下的managed-schema,在文件后面加上如下节点
<!-- ChineseAnalyzer -->
<fieldType name="text_cn_splitting" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
3.重启solr服务;
4.在第一部分第8步的时候,Add Field的时候,看是否有text_cn_splitting类型可选,如果有的话,那在add field的时候将需要进行中文分词的字段选择该类型即可;
定时任务:
使用系统的定时任务执行 curl
http://your_ip/dataimport?command=full-import&clean=true&commit=true 全量导入
http://your_ip/dataimport?command=delta-import&clean=false&commit=true 差异导入
这里clean参数如果是true,会把之前的数据清空掉,然后导入差异的数据,在差异性导入时注意这个参数,不然会把solr里的数据清空,然后导入差异性的数据(这个差异是清空前的差异),导致数据缺失;
建议访问低频时重建全量索引,如每天凌晨4点做一次全量导入,每10分钟做一次差异导入
FQA:
1.增量导入是以主键作为增量差异,默认这个主键是id,需要在managed-schema里修改uniqueKey节点成需要的主键,且在该文件里定义的主键必须是string类型的,如下图


2. 如果需要设置单字段索引,而不每个字段都去检索,比如有数据字段author,title,keywords,body,搜索的时候想搜索这四个字段,可以使用copyField字段,具体方法,在managed-schema中添加如下节点


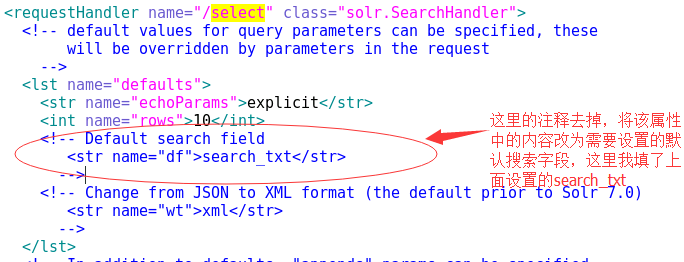
3. Solr7中已经不再支持defaultSearchField默认搜索字段了。需要设置默认搜索字段需要在solrconfig.xml中配置,
参考资料:
https://www.cnblogs.com/LUA123/p/7783102.html
http://archive.apache.org/dist/lucene/solr/ref-guide/apache-solr-ref-guide-7.0.pdf
https://wiki.apache.org/solr/DataImportHandler
本文原创,转载请注明出处。
Solr7使用Oracle数据源导入+中文分词的更多相关文章
- solr7.2安装实例,中文分词器
一.安装实例 1.创建实例目录 [root@node004]# mkdir -p /usr/local/solr/home/jonychen 2.复制实例相关配置文件 [root@node004]# ...
- Solr7.1---数据库导入并建立中文分词器
这里只是告诉你如何导入,生产环境不要这样部署你的solr服务. 首先修改solrConfig.xml文件 备份_default文件夹 修改solrconfig.xml 加入如下内容 官方示例:< ...
- solr7.4创建core,导入MySQL数据,中文分词
#solr版本:7.4.0 一.新建Core 进入安装目录下得server/solr/,创建一个文件夹,如:new_core 拷贝server/solr/configsets/_default/con ...
- solr7中文分词包
刚刚将solr4升级到了solr7.7,发现之前用的mmseg4j中文分词包用的时候会报错,插入新数据是创建索引会有异常 possible analysis error: startOffset mu ...
- Oracle导入中文乱码解决办法
Oracle导入中文乱码解决办法 一.确保各个客户端字符集的编码同服务器字符集编码一致 1- 确定sqlplus字符集编码,如果是windows设置环境变量. 2- 确保Sec ...
- Solr7.2.1环境搭建和配置ik中文分词器
solr7.2.1环境搭建和配置ik中文分词器 安装环境:Jdk 1.8. windows 10 安装包准备: solr 各种版本集合下载:http://archive.apache.org/dist ...
- Solr7.3.0入门教程,部署Solr到Tomcat,配置Solr中文分词器
solr 基本介绍 Apache Solr (读音: SOLer) 是一个开源的搜索服务器.Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现.Apache ...
- php+中文分词scws+sphinx+mysql打造千万级数据全文搜索
转载自:http://blog.csdn.net/nuli888/article/details/51892776 Sphinx是由俄罗斯人Andrew Aksyonoff开发的一个全文检索引擎.意图 ...
- Sphinx+MySQL5.1x+SphinxSE+mmseg中文分词
什么是Sphinx Sphinx 是一个全文检索引擎,一般而言,Sphinx是一个独立的搜索引擎,意图为其它应用提供快速.低空间占用.高结果相关度的全文搜索功能.Sphinx能够很easy的与SQL数 ...
随机推荐
- Hawk-and-Chicken
Hawk-and-Chicken Time Limit: 6000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) To ...
- Problem I
Problem Description Queues and Priority Queues are data structures which are known to most computer ...
- Java中方法的重载和重置(覆盖)的区别
简单来说,重载就是在同一类中允许同时存在一个以上的同名方法,只要这些方法的参数个数或类型不同即可,而重置(覆盖)是子类重新定义父类中己经定义的方法,即子类重写父类方法. 方法的重载 方法的重载就是在同 ...
- jQuery点击下拉菜单的展示与隐藏
首先点击显示某个div,然后要求再次点击时消失,或者点击document的其他地方会隐藏掉这个层,涉及到冒泡的问题,阻止document冒泡到dom上.代码如下: var $el = $(" ...
- transform 各种影响
1.提升元素的z-index层级,下面这个例子会让前面的图片显示在上面,一般来说应该是后面的覆盖前面图片的 <img src="mm1" style="-ms-tr ...
- vue实现仿淘宝结账页面
这个demo,是小颖基于之前的 vue2.0在table中实现全选和反选 文章进行更新后的demo,主要功能呢,是仿照淘宝页面的结算购物车商品时自动算出合计价格的页面,具体页面效果请看下面的动图: ...
- EasyWcf------无需配置,无需引用,动态绑定,轻松使用
设计原则:万物皆对象 前言:在上一篇的0配置使用Wcf中,虽然使用已经很方便了,但是对于最求极致简洁得人来说(比如我),客户端需要通过手动引用服务才能够调用服务接口,那么有没有办法能够绕过手动引用这一 ...
- 四:java调接口实现发送手机短信验证码功能
1.点击获取验证码之前的样式: 2.输入正确的手机号后点击获取验证码之后的样式: 3.如果手机号已经被注册的样式: 4.如果一个手机号一天发送超过3次就提示不能发送: 二:前台的注册页面的代码:reg ...
- C#编写的艺术字类方法
代码如下: using System;using System.Collections.Generic;using System.ComponentModel;using System.Drawing ...
- ZedBoard开发板学习记录(一)之开发环境的搭建(Ubuntu16.04)以及运行HelloWorld程序的测试
ZedBoard开发板由PL和PS两大部分组成, 对PS操作,一般有两个办法: (1).在Windows系统上面,使用SDK新建C Project SDK自带编译环境,编译后自动产生elf文件.使用U ...