Solr7.2.1环境搭建和配置ik中文分词器
solr7.2.1环境搭建和配置ik中文分词器
安装环境:Jdk 1.8、 windows 10
安装包准备:
solr 各种版本集合下载:http://archive.apache.org/dist/lucene/solr/

tomcat下载(apache-tomcat-8.5.27-windows-x64.zip):https://tomcat.apache.org/download-80.cgi
下载ik分词器:IK Analyzer 2012FF_hf1.zip,这里这个版本已经不能使用,ik-analyzer官网:https://code.google.com/p/ik-analyzer/

这个网站不翻墙是访问不了的,可以去下面这个网站下载:https://www.developerfusion.com/project/41221/ikanalyzer/
IK分词器2012年以后就没有更新过,其所依赖的lucene相关组件的版本为4.X,而solr7.2下面的lucene版本为7.2,会导致分词功能不能正常使用;
解决办法:需要下载以下两个分词jar包solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar。
下载地址:http://files.cnblogs.com/files/wander1129/ikanalyzer-solr6.5.zip
1、搭建solr环境
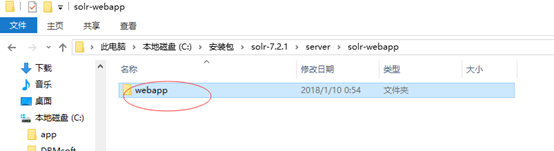
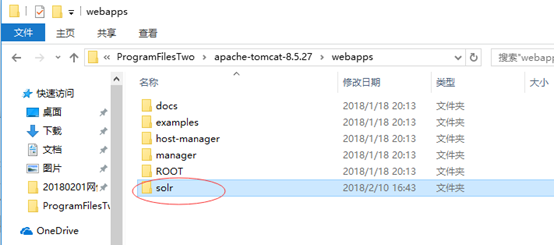
1 解压下载的solr-7.2.1压缩包,将解压后的solr-7.2.1文件夹下server\solr-webapp\webapp文件夹拷贝到tomcat安装目录下的webapps文件夹中,并重命名为solr。如下图:
2 创建一个solr_home的文件夹作为solr的安装目录,如:C:\ProgramFilesTwo\solr_home
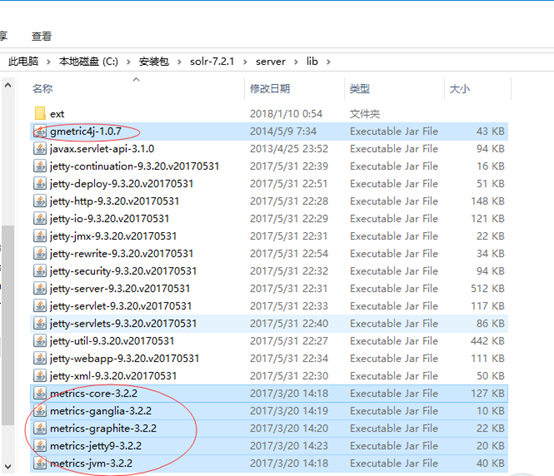
3 将解压后的solr-7.2.1文件夹下server\lib\ext内的所有jar包、server\lib内以metrics开头的所有jar包,以及gmetric4j-1.0.7.jar复制到tomcat安装目录下的webapps\solr\WEB-INF\lib下。

4 在tomcat安装目录下的webapps\solr\WEB-INF中,新建一个classes文件夹,将解压后的solr-7.2.1文件夹下server\resources内的log4j.properties文件拷贝到里面
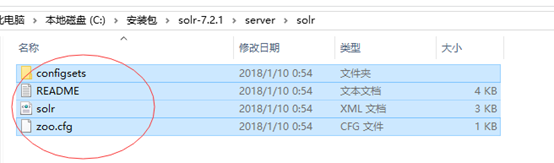
5 拷贝solr-7.2.1文件夹下server\solr内的所有文件到solr_home的文件夹中(即solr的安装目录)
6在solr_home文件夹下新建一个logs文件夹。
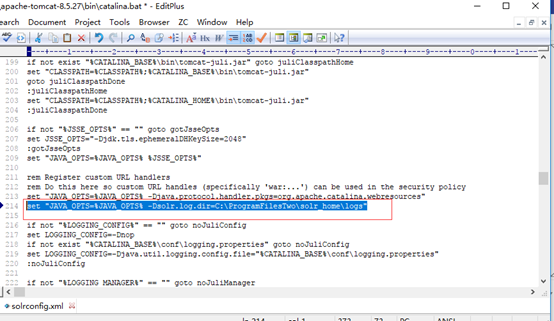
7修改tomcat安装目录下bin文件夹中的catalina.bat,添加solr.log.dir系统变量, 指定solr日志记录存放地址(即上面创建的logs文件夹路径)。例如:
set "JAVA_OPTS=%JAVA_OPTS% -Dsolr.log.dir=C:\ProgramFilesTwo\solr_home\logs"
8.在solr_home文件夹下新建一个new_core文件夹,将解压后的solr-7.2.1文件夹下server\solr\configsets\_default下的conf文件夹拷贝到里面,然后修改conf文件夹里solrconfig.xml文件,如下:
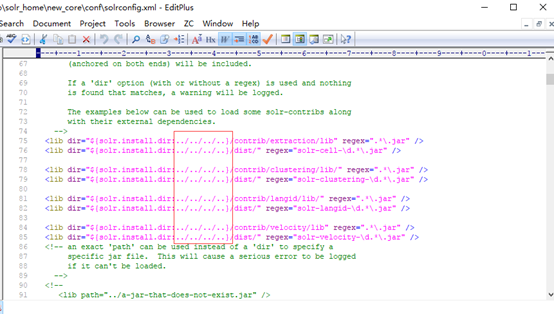
改为:
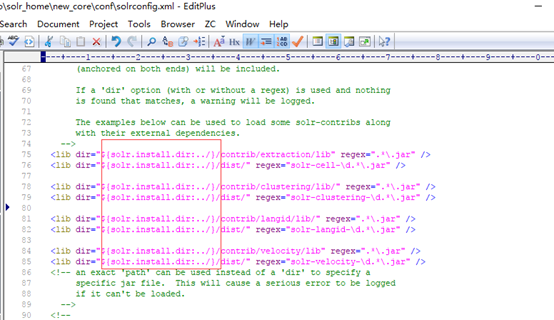
9.修改tomcat安装目录下webapps\solr\WEB-INF内的web.xml文件:
添加内容:

注释内容:
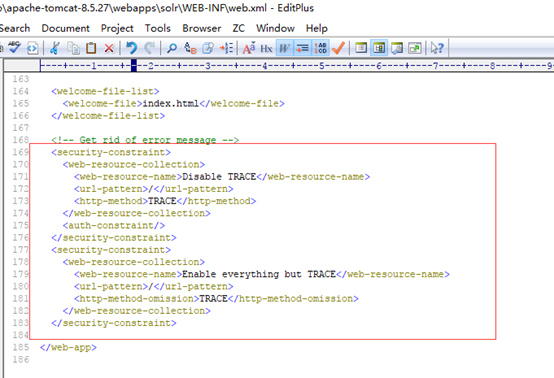
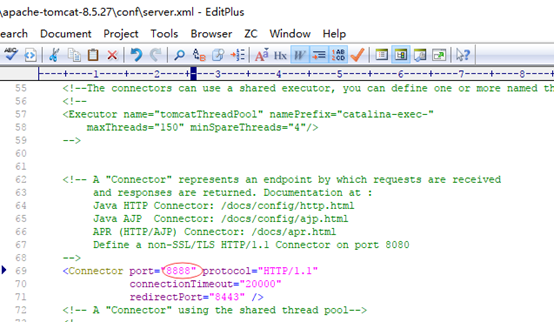
10. 修改端口,默认是8080(看需要设置),修改在tomcat安装目录下conf文件夹内的server.xml文件:
11.查看solr, http://localhost:8888/solr/index.html#/
点击Core Admin菜单,如果没有Core,会弹出如下框,提示添加。
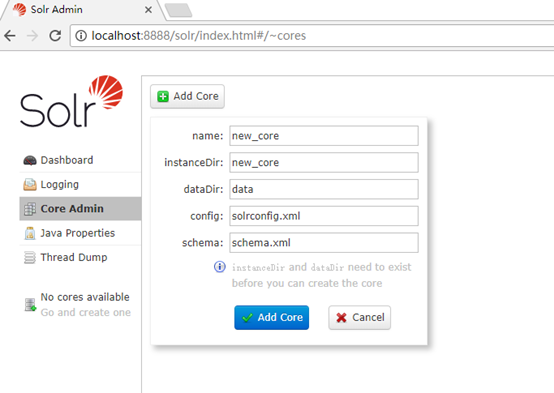
instanceDir: solr安装目录下的new_core文件夹的路径
dataDir: solr安装目录下的new_core\data文件夹的路径
config: solr安装目录下的new_core\conf\solrconfig.xml文件的路径
schema: solr安装目录下的new_core\conf\managed-schema文件的路径
添加以后就可以选择使用了
到这里solr的环境就搭建好了,下面开始整合中文分词器;
2、整合分词器
1、使用.solr7.2.1自带的中文分词器
将解压后的solr-7.2.1\contrib\analysis-extras\lucene-libs下的lucene-analyzers-smartcn-7.2.1.jar 放到Tomcat8\webapps\solr\WEB-INF\lib下。

在Tomcat8\solr_h\solrhome\solr_core\conf找到managed-schema 添加已下代码
<fieldType name="text_ik_zd" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
重新启动Tomcat8,就可以使用solr自带的分词器了
2、配置ik中文分词器(好处:IKAnalyzer支持屏蔽关键词、新词汇的配置)
解压IK Analyzer 2012FF_hf1压缩包:
ext.dic为扩展字典,改为mydict.dic 这个扩展词收录了搜狗词库
stopword.dic为停止词字典
IKAnalyzer.cfg.xml为配置文件
solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar为分词jar包。
将IK分词器 JAR 包拷贝到C:\ProgramFilesTwo\apache-tomcat-8.5.27\webapps\solr\WEB-INF\lib下
将词典配置文件拷贝到 C:\ProgramFilesTwo\apache-tomcat-8.5.27\webapps\solr\WEB-INF\classes下
更改在C:\ProgramFilesTwo\solr_home\new_core\conf找到managed-schema配置文件,添加以下:
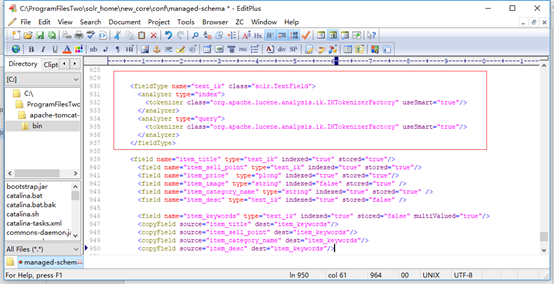
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/>
</analyzer>
</fieldType>
<field name="item_title" type="text_ik" indexed="true" stored="true"/>
<field name="item_sell_point" type="text_ik" indexed="true" stored="true"/>
<field name="item_price" type="plong" indexed="true" stored="true"/>
<field name="item_image" type="string" indexed="false" stored="true" />
<field name="item_category_name" type="string" indexed="true" stored="true" />
<field name="item_desc" type="text_ik" indexed="true" stored="false" />
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="item_title" dest="item_keywords"/>
<copyField source="item_sell_point" dest="item_keywords"/>
<copyField source="item_category_name" dest="item_keywords"/>
<copyField source="item_desc" dest="item_keywords"/>
重新启动Tomcat8.5.27,就可以使用ik的分词器了
参考博文:
http://blog.csdn.net/lingzhangjie/article/details/79114993
http://blog.csdn.net/m0_37044606/article/details/79155144
https://www.cnblogs.com/kehaocheng/p/8005532.html
Solr7.2.1环境搭建和配置ik中文分词器的更多相关文章
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
- ES-Mac OS环境搭建-ik中文分词器
下载 从github下载ik中文分词器,点击地址,需要注意的是,ik分词器和elasticsearch版本必须一致. 安装 下载到本地并解压到elasticsearch中的plugins目录内即可. ...
- Solr7.3.0入门教程,部署Solr到Tomcat,配置Solr中文分词器
solr 基本介绍 Apache Solr (读音: SOLer) 是一个开源的搜索服务器.Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现.Apache ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- ElasticSearch速学 - IK中文分词器远程字典设置
前面已经对”IK中文分词器“有了简单的了解: 但是可以发现不是对所有的词都能很好的区分,比如: 逼格这个词就没有分出来. 词库 实际上IK分词器也是根据一些词库来进行分词的,我们可以丰富这个词库. ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
- elasticsearch使用ik中文分词器
elasticsearch使用ik中文分词器 一.背景 二.安装 ik 分词器 1.从 github 上找到和本次 es 版本匹配上的 分词器 2.使用 es 自带的插件管理 elasticsearc ...
- es5.0 安装ik中文分词器 mac
es5.0集成ik中文分词器,网上资料很多,但是讲的有点乱,有的方法甚至不能正常运行此插件 特别注意的而是,es的版本一定要和ik插件的版本相对应: 1,下载ik 插件: https://github ...
随机推荐
- 实现Callable接口,并与Future结合使用
实现步骤: 创建 Callable 接口的实现类,并实现 call() 方法,该 call() 方法将作为线程执行体,并且有返回值. 创建 Callable 实现类的实例,使用 FutureTask ...
- leetcode-easy-array-31 three sum
mycode 69.20% class Solution(object): def removeDuplicates(self, nums): """ :type nu ...
- Python深度学习读书笔记-4.神经网络入门
神经网络剖析 训练神经网络主要围绕以下四个方面: 层,多个层组合成网络(或模型) 输入数据和相应的目标 损失函数,即用于学习的反馈信号 优化器,决定学习过程如何进行 如图 3-1 所示:多个层 ...
- Windows程序调用dll
可以写在WndProc的WM_CREATE里面,不能写在WinMain里面
- Redis存储对象序列化和反序列化
import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.ObjectInpu ...
- 2018.03.27 pandas duplicated 和 replace 使用
#.duplicated / .replace import numpy as np import pandas as pd s = pd.Series([1,1,1,1,1,2,3,3,3,4,4, ...
- 【Spring】---属性注入
一.Spring注入属性(有参构造和[set方法]) 注意:在Spring框架中只支持set方法.有参构造方法这两种方法. 使用有参数构造方法注入属性(用的不多,但需要知道): 实体类 package ...
- maven项目的导包问题,已经加载jar包了可是idea检测不到
1.详细请参考 https://blog.csdn.net/brainhang/article/details/76725080 把测试模式注释即可
- 在laravel框架中使用mq
本文写于2018-11-28 1.部署laravel项目 https://github.com/laravel/laravel 通过git克隆项目,或者下载zip包然后解压等方式都可以把larave ...
- 深入.NET平台和C#编程的错题
29)有如下C# 代码,则下面选项中说法正确的是(BC).public class A { } Person public class B : A { } StudentA a = new A( ...