JAVA提高十九:WeakHashMap&EnumMap&LinkedHashMap&LinkedHashSet深入分析
因为最近工作太忙了,连续的晚上支撑和上班,因此没有精力来写下这篇博客,今天上午正好有一点空,因此来复习一下不太常用的集合体系大家族中的几个类:WeakHashMap&EnumMap&LinkedHashMap&LinkedHashSet,以便用到的时候不至于是什么都不知道。好了,言归正传,下面我们开始依次学习下:
一、WeakHashMap
1.WeakHashMap的结构
java.lang.Object
↳ java.util.AbstractMap<K, V>
↳ java.util.WeakHashMap<K, V> public class WeakHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V> {}
关系图:
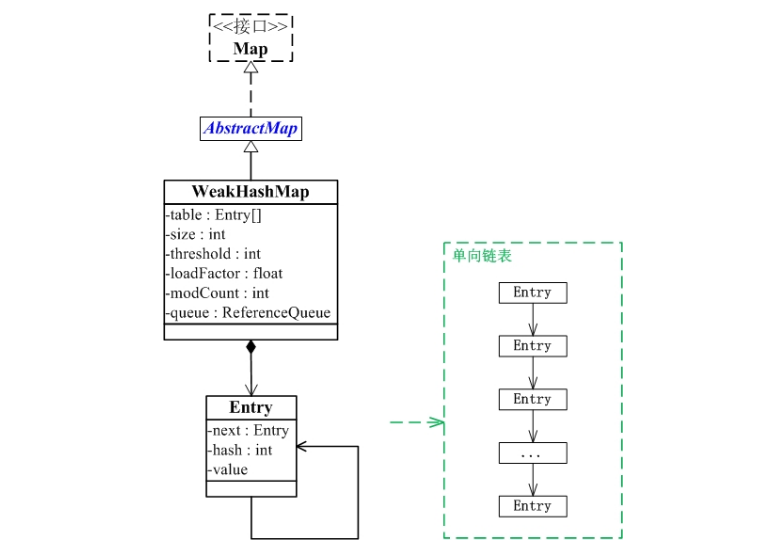
从图中可以看出:
(01) WeakHashMap继承于AbstractMap,并且实现了Map接口。
(02) WeakHashMap是哈希表,但是它的键是"弱键"。WeakHashMap中保护几个重要的成员变量:table, size, threshold, loadFactor, modCount, queue。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
size是Hashtable的大小,它是Hashtable保存的键值对的数量。
threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的
queue保存的是“已被GC清除”的“弱引用的键”。
上面我们提到了,"弱键",那么有必要解释一下:
1)强引用,任何时候都不会被垃圾回收器回收,如果内存不足,宁愿抛出OutOfMemoryError。
2)软引用,只有在内存将满的时候才会被垃圾回收器回收,如果还有可用内存,垃圾回收器不会回收。
3)弱引用,只要垃圾回收器运行,就肯定会被回收,不管还有没有可用内存。
4)虚引用,虚引用等于没有引用,任何时候都有可能被垃圾回收。
详细的了解,等JVM分析的时候进行讲解,在这里只需要有一个概念就好,因为本章的重点不是讲JVM。如果提前想了解可以参考:
WeakHashMap实现了Map接口,是HashMap的一种实现,它比HashMap多了一个引用队列:
private final ReferenceQueue<Object> queue = new ReferenceQueue<>();
对比WeakHashMap和HashMap的源码,会发现WeakHashMap中方法的实现方式基本和HashMap的一样,注意“基本”两个字,除了没有实现Cloneable和Serializable这两个标记接口,最大的区别在于在于expungeStaleEntries()这个方法,这个是整个WeakHashMap的精髓,我们稍后进行阐述。
它使用弱引用作为内部数据的存储方案。WeakHashMap是弱引用的一种典型应用,它可以为简单的缓存表解决方案。
2.WeakHashMap使用
我们举一个简单的例子来说明一下WeakHashMap的使用:
package com.pony1223; import java.util.Map;
import java.util.WeakHashMap; public class WeakHashMapDemo
{
public static void main(String[] args)
{
Map<String,Integer> map = new WeakHashMap<String,Integer>();
map.put("s1", 1);
map.put("s2", 2);
map.put("s3", 3);
map.put("s4", 4);
map.put("s5", 5);
map.put(null, 9);
map.put("s6", 6);
map.put("s7", 7);
map.put("s8", 8);
map.put(null, 11);
for(Map.Entry<String,Integer> entry:map.entrySet())
{
System.out.println(entry.getKey()+":"+entry.getValue());
}
System.out.println(map);
} }
运行结果:
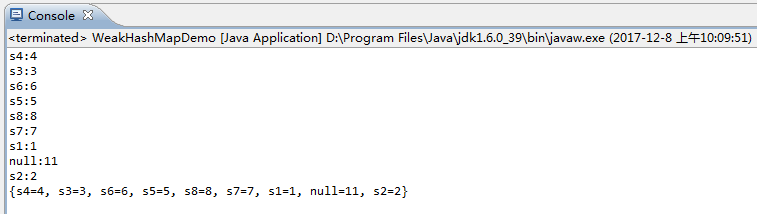
WeakHashMap和HashMap一样key和value的值都可以为null,并且也是无序的。但是HashMap的null是存在table[0]中的,这是固定的,并且null的hash为0,而在WeakHashMap中的null却没有存入table[0]中。
public V put(K key, V value) {
K k = (K) maskNull(key);
int h = HashMap.hash(k.hashCode());
Entry[] tab = getTable();
int i = indexFor(h, tab.length);
for (Entry<K,V> e = tab[i]; e != null; e = e.next) {
if (h == e.hash && eq(k, e.get())) {
V oldValue = e.value;
if (value != oldValue)
e.value = value;
return oldValue;
}
}
第一步的操作方法为:maskNull
private static final Object NULL_KEY = new Object();
private static Object maskNull(Object key) {
return (key == null) ? NULL_KEY : key;
}
static Object unmaskNull(Object key) {
return (key == NULL_KEY) ? null : key;
}
当对map进行put和get操作的时候,将null值标记为NULL_KEY,然后对NULL_KEY即对new Object()进行与其他对象一视同仁的hash,这样就使得null和其他非null的值毫无区别。(做了一次包装)
3.关键源码分析
首先看一下Entry<K,V>这个静态内部类:
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V> {
V value;
int hash;
Entry<K,V> next;
/**
* Creates new entry.
*/
Entry(Object key, V value,
ReferenceQueue<Object> queue,
int hash, Entry<K,V> next) {
super(key, queue);
this.value = value;
this.hash = hash;
this.next = next;
}
//其余代码略
}
可以看到Entry继承扩展了WeakReference类(有关Java的引用类型暂不深入分析)。并在其构造函数中,构造了key的弱引用。
此外,在WeakHashMap的各项操作中,比如get()、put()、size()都间接或者直接调用了expungeStaleEntries()方法,以清理持有弱引用的key的表象。
以put为例:
public V put(K key, V value) {
K k = (K) maskNull(key);
int h = HashMap.hash(k.hashCode());
Entry[] tab = getTable();
int i = indexFor(h, tab.length);
for (Entry<K,V> e = tab[i]; e != null; e = e.next) {
if (h == e.hash && eq(k, e.get())) {
V oldValue = e.value;
if (value != oldValue)
e.value = value;
return oldValue;
}
}
modCount++;
Entry<K,V> e = tab[i];
tab[i] = new Entry<K,V>(k, value, queue, h, e);
if (++size >= threshold)
resize(tab.length * 2);
return null;
}
其中resize方法中:
void resize(int newCapacity) {
Entry[] oldTable = getTable();
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(oldTable, newTable);
table = newTable;
/*
* If ignoring null elements and processing ref queue caused massive
* shrinkage, then restore old table. This should be rare, but avoids
* unbounded expansion of garbage-filled tables.
*/
if (size >= threshold / 2) {
threshold = (int)(newCapacity * loadFactor);
} else {
expungeStaleEntries();
transfer(newTable, oldTable);
table = oldTable;
}
}
可以看到其间接的调用了expungeStaleEntries(); 方法的实现如下:
private void expungeStaleEntries() {
for (Object x; (x = queue.poll()) != null; ) {
synchronized (queue) {
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) x;
int i = indexFor(e.hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> p = prev;
while (p != null) {
Entry<K,V> next = p.next;
if (p == e) {
if (prev == e)
table[i] = next;
else
prev.next = next;
// Must not null out e.next;
// stale entries may be in use by a HashIterator
e.value = null; // Help GC
size--;
break;
}
prev = p;
p = next;
}
}
}
}
可以看到每调用一次expungeStaleEntries()方法,就会在引用队列中寻找是否有被清楚的key对象,如果有则在table中找到其值,并将value设置为null,next指针也设置为null,让GC去回收这些资源。
4.场景应用
如果在一个普通的HashMap中存储一些比较大的值如下:
Map<Integer,Object> map = new HashMap<>();
for(int i=0;i<10000;i++)
{
Integer ii = new Integer(i);
map.put(ii, new byte[i]);
}
运行参数:-Xmx5M
运行结果:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at collections.WeakHashMapTest.main(WeakHashMapTest.java:39)
同样我们将HashMap换成WeakHashMap其余都不变:
Map<Integer,Object> map = new WeakHashMap<>();
for(int i=0;i<10000;i++)
{
Integer ii = new Integer(i);
map.put(ii, new byte[i]);
}
运行结果:(无任何报错)
通过上面的对比可以看到WeakHashMap的功效,如果在系统中需要一张很大的Map表,Map中的表项作为缓存只用,这也意味着即使没能从该Map中取得相应的数据,系统也可以通过候选方案获取这些数据。虽然这样会消耗更多的时间,但是不影响系统的正常运行。
在这种场景下,使用WeakHashMap是最合适的。因为WeakHashMap会在系统内存范围内,保存所有表项,而一旦内存不够,在GC时,没有被引用的表项又会很快被清除掉,从而避免系统内存溢出。
我们这里稍微改变一下上面的代码(加了一个List):
Map<Integer,Object> map = new WeakHashMap<>();
List<Integer> list = new ArrayList<>();
for(int i=0;i<10000;i++)
{
Integer ii = new Integer(i);
list.add(ii);
map.put(ii, new byte[i]);
}
运行结果:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at collections.WeakHashMapTest.main(WeakHashMapTest.java:43)
如果存放在WeakHashMap中的key都存在强引用,那么WeakHashMap就会退化成HashMap。如果在系统中希望通过WeakHashMap自动清楚数据,请尽量不要在系统的其他地方强引用WeakHashMap的key,否则,这些key就不会被回收,WeakHashMap也就无法正常释放它们所占用的表项。
因此,要想WeakHashMap能够释放掉key被GC的value的对象,尽可能的多调用下put/size/get等操作,因为这些方法会调用expungeStaleEntries方法,expungeStaleEntries方法是关键,而如果不操作WeakHashMap,以企图WeakHashMap“自动”释放内存是不可取的,这里的“自动”是指譬如map.put(obj,new byte[10M]);之后obj=null了,之后再也没掉用过map的任何方法,那么new出来的10M空间是不会释放的。
二、EnumMap
1.定义
package java.util; import java.util.Map.Entry;
import sun.misc.SharedSecrets;
public class EnumMap<K extends Enum<K>, V> extends AbstractMap<K, V>
implements java.io.Serializable, Cloneable{
private final Class<K> keyType;
private transient K[] keyUniverse;
private transient Object[] vals;
private transient int size = 0;
}
keyType变量是EnumMap的key泛型的类对象,EnumMap根据这个类型,可以获得keyUniverse的内容,vals存放的是与keyUniverse映射的值,如果没有映射则为null,如果映射为null则会特殊处理成NULL,NULL的定义如下:
private static final Object NULL = new Object() {
public int hashCode() {
return 0;
}
public String toString() {
return "java.util.EnumMap.NULL";
}
};
对于值NULL的处理类似WeakHashMap的特殊处理,会有两个方法:
private Object maskNull(Object value) {
return (value == null ? NULL : value);
}
private V unmaskNull(Object value) {
return (V) (value == NULL ? null : value);
}
这样可以区分vals中是null(即没有映射)还是NULL(即映射为null);
EnumMap的size是根据vals中的非null(包括NULL)的值的个数确定的,比如put方法:
public V put(K key, V value) {
typeCheck(key);
int index = key.ordinal();
Object oldValue = vals[index];
vals[index] = maskNull(value);
if (oldValue == null)
size++;
return unmaskNull(oldValue);
}
typeCheck判断key的类对象或者父类对象是否与keyType相等,如果不相等则抛出ClassCastException异常。
注意EnumMap并没有类似HashMap的resize的过程,也没有加载因子的概念,因为在一个EnumMap创建的时候,keyUniverse和vals的大小就固定。
2.EnumMap使用
先看一个例子:
package com.pony1223; import java.util.EnumMap;
import java.util.Map; public class EnumMapDemo
{
public enum Color
{
RED,BLUE,BLACK,YELLOW,GREEN;
} public static void main(String[] args)
{
EnumMap<Color,String> map = new EnumMap<Color,String>(Color.class); map.put(Color.YELLOW, "黄色");
map.put(Color.RED, "红色");
map.put(Color.BLUE, null);
// map.put(null, "无"); //会报NullPonitException的错误
map.put(Color.BLACK, "黑色");
map.put(Color.GREEN, "绿色"); for(Map.Entry<Color,String> entry:map.entrySet())
{
System.out.println(entry.getKey()+":"+entry.getValue());
}
System.out.println(map);
} }
运行结果:
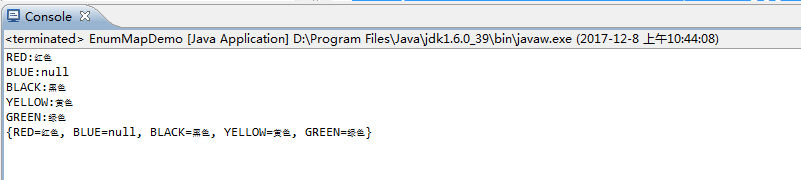
EnumMap的key不允许为null,value可以为null,按照key在enum中的顺序进行保存,非线程安全。可以用工具类Collections进行包装成线程安全的:
Map<EnumKey, V> m = Collections.synchronizedMap(new EnumMap<EnumKey, V>(...));
EnumMap的基本操作都比较快,都在常量时间内完成,基本上(但不保证)比HashMap快。
EnumMap有三个构造函数:
- public EnumMap(Class<K> keyType);
- public EnumMap(EnumMap<K, ? extends V> m);
- public EnumMap(Map<K, ? extends V> m) ;
前两个构造函数一目了然,对第三个构造函数进行分析:
Map<Integer,Integer> map1 = new HashMap<Integer,Integer>();
map1.put(1, 1);
map1.put(3, 3);
map1.put(2, 2);
Map<Integer,Integer> map2 = new EnumMap<>(map1);//编译器提示错误:Cannot infer type arguments for EnumMap<>
这个是因为Integer并不是extends Enum; 这里变换一下:
Map<Enum,Integer> map1 = new HashMap<Enum,Integer>();
map1.put(Color.YELLOW, 1);
map1.put(Color.RED, 3);
map1.put(Color.BLUE, 2);
Map<Enum,Integer> map2 = new EnumMap<Enum,Integer>(map1); for(Map.Entry entry:map2.entrySet())
{
System.out.println(entry.getKey()+":"+entry.getValue());
}
System.out.println(map2);
System.out.println(map2.size());
能够正常运行,输出结果:
RED:3
BLUE:2
YELLOW:1
{RED=3, BLUE=2, YELLOW=1}
3
3.场景应用
《Effective Java》中作者建议用EnumMap代替叙述索引,最好不要用序数来索引数组,而要使用EnumMap。这里采用《Effective Java》书中的例子来举例。
public static class Herb
{
public enum Type
{
ANNUAL, PERENNIAL, BIENNTAL
} private final String name;
private final Type type; public Herb(String name, Type type)
{
this.name = name;
this.type = type;
} public Type getType()
{
return type;
} @Override
public String toString()
{
return name;
}
}
现在用一座种满香草的花园,想要按照类型(一年生、多年生、两年生,即上面Type的类型)进行组织之后将这些植物列出来。如果使用数组实现的话,需要构建三个集合,每种类型一个,并且遍历整座花园,将每种香草放到相应的集合中。
Herb[] garden = new Herb[]{new Herb("f1",Herb.Type.ANNUAL),new Herb("f2",Herb.Type.PERENNIAL),new Herb("f3",Herb.Type.BIENNTAL),
new Herb("f4",Herb.Type.PERENNIAL),new Herb("f5",Herb.Type.ANNUAL),new Herb("f6",Herb.Type.BIENNTAL),
new Herb("f7",Herb.Type.ANNUAL),new Herb("f8",Herb.Type.BIENNTAL),new Herb("f9",Herb.Type.PERENNIAL)};
Set<Herb>[] herbsByType = (Set<Herb>[]) new Set[Herb.Type.values().length];
for(int i=0;i<herbsByType.length;i++)
{
herbsByType[i] = new HashSet<Herb>();
}
for(Herb h:garden)
{
herbsByType[h.type.ordinal()].add(h);
}
for(int i=0;i<herbsByType.length;i++)
{
System.out.printf("%s:%s%n", Herb.Type.values()[i],herbsByType[i]);
}
运行结果:
ANNUAL:[f5, f7, f1]
PERENNIAL:[f4, f2, f9]
BIENNTAL:[f8, f3, f6]
这种方法确实可行,但是影藏着许多问题。因为数组不能和泛型兼容,程序需要进行未受检的转换,并且不能正确无误地进行编译。因为数组不知道它的索引代表着什么,你必须手工标注这些索引的输出。但是这种方法最严重的问题在于,当你访问一个按照枚举的叙述进行索引的数组时,使用正确的int值就是你的职责了,int不能提供枚举的类型安全。
但是你可以用EnumMap改善这个程序:
Herb[] garden = new Herb[]{new Herb("f1",Herb.Type.ANNUAL),new Herb("f2",Herb.Type.PERENNIAL),new Herb("f3",Herb.Type.BIENNTAL),
new Herb("f4",Herb.Type.PERENNIAL),new Herb("f5",Herb.Type.ANNUAL),new Herb("f6",Herb.Type.BIENNTAL),
new Herb("f7",Herb.Type.ANNUAL),new Herb("f8",Herb.Type.BIENNTAL),new Herb("f9",Herb.Type.PERENNIAL)};
Map<Herb.Type, Set<Herb>> herbsByType = new EnumMap<>(Herb.Type.class);
for(Herb.Type t : Herb.Type.values())
{
herbsByType.put(t, new HashSet<Herb>());
}
for(Herb h:garden)
{
herbsByType.get(h.type).add(h);
}
System.out.println(herbsByType);
运行结果:
{ANNUAL=[f7, f1, f5], PERENNIAL=[f4, f2, f9], BIENNTAL=[f8, f6, f3]}
这段程序更剪短、更清楚,也更安全,运行速度方面可以与使用序数的数组相媲美。注意EnumMap构造器采用键类型的Class对象:这是一个有限制的类型令牌,它提供了运行时的泛型信息。
小节:
EnumMap是专门为枚举类型量身定做的Map实现。虽然使用其它的Map实现(如HashMap)也能完成枚举类型实例到值得映射,但是使用EnumMap会更加高效:它只能接收同一枚举类型的实例作为键值,并且由于枚举类型实例的数量相对固定并且有限,所以EnumMap使用数组来存放与枚举类型对应的值。这使得EnumMap的效率非常高。EnumMap在内部使用枚举类型的ordinal()得到当前实例的声明次序,并使用这个次序维护枚举类型实例对应值在数组的位置。
三、LinkedHashMap
1.简单概述
LinkedHashMap是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
LinkedHashMap实现与HashMap的不同之处在于,前者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
2. LinkedHashMap的实现
对于LinkedHashMap而言,它继承与HashMap、底层使用哈希表与双向链表来保存所有元素。其基本操作与父类HashMap相似,它通过重写父类相关的方法,来实现自己的链接列表特性。下面我们来分析LinkedHashMap的源代码:
1) Entry元素:
LinkedHashMap采用的hash算法和HashMap相同,但是它重新定义了数组中保存的元素Entry,该Entry除了保存当前对象的引用外,还保存了其上一个元素before和下一个元素after的引用,从而在哈希表的基础上又构成了双向链接列表。看源代码:
/**
* 双向链表的表头元素。
*/
private transient Entry<K,V> header; /**
* LinkedHashMap的Entry元素。
* 继承HashMap的Entry元素,又保存了其上一个元素before和下一个元素after的引用。
*/
private static class Entry<K,V> extends HashMap.Entry<K,V> {
Entry<K,V> before, after;
……
}
2) 初始化:
通过源代码可以看出,在LinkedHashMap的构造方法中,实际调用了父类HashMap的相关构造方法来构造一个底层存放的table数组。如:
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
我们已经知道LinkedHashMap的Entry元素继承HashMap的Entry,提供了双向链表的功能。在上述HashMap的构造器中,最后会调用init()方法,进行相关的初始化,这个方法在HashMap的实现中并无意义,只是提供给子类实现相关的初始化调用。LinkedHashMap重写了init()方法,在调用父类的构造方法完成构造后,进一步实现了对其元素Entry的初始化操作。
void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header;
}
3) 存储:
LinkedHashMap并未重写父类HashMap的put方法,而是重写了父类HashMap的put方法调用的子方法void addEntry(int hash, K key, V value, int bucketIndex) 和void createEntry(int hash, K key, V value, int bucketIndex),提供了自己特有的双向链接列表的实现。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 调用create方法,将新元素以双向链表的的形式加入到映射中。
createEntry(hash, key, value, bucketIndex);
// 删除最近最少使用元素的策略定义
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
if (size >= threshold)
resize(2 * table.length);
}
}
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
// 调用元素的addBrefore方法,将元素加入到哈希、双向链接列表。
e.addBefore(header);
size++;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
4) 读取:
LinkedHashMap重写了父类HashMap的get方法,实际在调用父类getEntry()方法取得查找的元素后,再判断当排序模式accessOrder为true时,记录访问顺序,将最新访问的元素添加到双向链表的表头,并从原来的位置删除。由于的链表的增加、删除操作是常量级的,故并不会带来性能的损失。
public V get(Object key) {
// 调用父类HashMap的getEntry()方法,取得要查找的元素。
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
// 记录访问顺序。
e.recordAccess(this);
return e.value;
}
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
// 如果定义了LinkedHashMap的迭代顺序为访问顺序,
// 则删除以前位置上的元素,并将最新访问的元素添加到链表表头。
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
3.使用
通过上面我们知道了,LinkedHashMap是Hash表和链表的实现,并且依靠着双向链表保证了迭代顺序是插入的顺序。非线程安全。
Map<String,Integer> map = new LinkedHashMap<String,Integer>();
map.put("s1", 1);
map.put("s2", 2);
map.put("s3", 3);
map.put("s4", 4);
map.put("s5", 5);
map.put(null, 9);
map.put("s6", 6);
map.put("s7", 7);
map.put("s8", 8);
map.put(null, 11);
for(Map.Entry<String,Integer> entry:map.entrySet())
{
System.out.println(entry.getKey()+":"+entry.getValue());
}
System.out.println(map);
结果:
s1:1
s2:2
s3:3
s4:4
s5:5
null:11
s6:6
s7:7
s8:8
{s1=1, s2=2, s3=3, s4=4, s5=5, null=11, s6=6, s7=7, s8=8}
| 关 注 点 | 结 论 |
| LinkedHashMap是否允许空 | Key和Value都允许空 |
| LinkedHashMap是否允许重复数据 | Key重复会覆盖、Value允许重复 |
| LinkedHashMap是否有序 | 有序 |
| LinkedHashMap是否线程安全 | 非线程安全 |
总结:
其实 LinkedHashMap 几乎和 HashMap 一样:从技术上来说,不同的是它定义了一个 Entry<K,V> header,这个 header 不是放在 Table 里,它是额外独立出来的。LinkedHashMap 通过继承 hashMap 中的 Entry<K,V>,并添加两个属性 Entry<K,V> before,after,和 header 结合起来组成一个双向链表,来实现按插入顺序或访问顺序排序。
在写关于 LinkedHashMap 的过程中,记起来之前面试的过程中遇到的一个问题,也是问我 Map 的哪种实现可以做到按照插入顺序进行迭代?当时脑子是突然短路的,但现在想想,也只能怪自己对这个知识点还是掌握的不够扎实,所以又从头认真的把代码看了一遍。
不过,我的建议是,大家首先首先需要记住的是:LinkedHashMap 能够做到按照插入顺序或者访问顺序进行迭代,这样在我们以后的开发中遇到相似的问题,才能想到用 LinkedHashMap 来解决,否则就算对其内部结构非常了解,不去使用也是没有什么用的。我们学习的目的是为了更好的应用。
四、LinkedHashSet
1.LinkedHashSet 概述
之前的博文中,分别写了 HashMap 和 HashSet,然后我们可以看到 HashSet 的方法基本上都是基于 HashMap 来实现的,说白了,HashSet内部的数据结构就是一个 HashMap,其方法的内部几乎就是在调用 HashMap 的方法。LinkedHashSet 首先我们需要知道的是它是一个 Set 的实现,所以它其中存的肯定不是键值对,而是值。此实现与 HashSet 的不同之处在于,LinkedHashSet 维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可为插入顺序或是访问顺序。
看到上面的介绍,是不是感觉其与 HashMap 和 LinkedHashMap 的关系很像?
注意,此实现不是同步的。如果多个线程同时访问链接的哈希Set,而其中至少一个线程修改了该 Set,则它必须保持外部同步。
2.LinkedHashSet 的实现
对于 LinkedHashSet 而言,它继承与 HashSet、又基于 LinkedHashMap 来实现的。
LinkedHashSet 底层使用 LinkedHashMap 来保存所有元素,它继承与 HashSet,其所有的方法操作上又与 HashSet 相同,因此 LinkedHashSet 的实现上非常简单,只提供了四个构造方法,并通过传递一个标识参数,调用父类的构造器,底层构造一个 LinkedHashMap 来实现,在相关操作上与父类 HashSet 的操作相同,直接调用父类 HashSet 的方法即可。LinkedHashSet 的源代码如下:
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable { private static final long serialVersionUID = -2851667679971038690L; /**
* 构造一个带有指定初始容量和加载因子的新空链接哈希set。
*
* 底层会调用父类的构造方法,构造一个有指定初始容量和加载因子的LinkedHashMap实例。
* @param initialCapacity 初始容量。
* @param loadFactor 加载因子。
*/
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
} /**
* 构造一个带指定初始容量和默认加载因子0.75的新空链接哈希set。
*
* 底层会调用父类的构造方法,构造一个带指定初始容量和默认加载因子0.75的LinkedHashMap实例。
* @param initialCapacity 初始容量。
*/
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
} /**
* 构造一个带默认初始容量16和加载因子0.75的新空链接哈希set。
*
* 底层会调用父类的构造方法,构造一个带默认初始容量16和加载因子0.75的LinkedHashMap实例。
*/
public LinkedHashSet() {
super(16, .75f, true);
} /**
* 构造一个与指定collection中的元素相同的新链接哈希set。
*
* 底层会调用父类的构造方法,构造一个足以包含指定collection
* 中所有元素的初始容量和加载因子为0.75的LinkedHashMap实例。
* @param c 其中的元素将存放在此set中的collection。
*/
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
}
以上几乎就是 LinkedHashSet 的全部代码了,那么读者可能就会怀疑了,不是说 LinkedHashSet 是基于 LinkedHashMap 实现的吗?那我为什么在源码中甚至都没有看到出现过 LinkedHashMap。不要着急,我们可以看到在 LinkedHashSet 的构造方法中,其调用了父类的构造方法。我们可以进去看一下:
/**
* 以指定的initialCapacity和loadFactor构造一个新的空链接哈希集合。
* 此构造函数为包访问权限,不对外公开,实际只是是对LinkedHashSet的支持。
*
* 实际底层会以指定的参数构造一个空LinkedHashMap实例来实现。
* @param initialCapacity 初始容量。
* @param loadFactor 加载因子。
* @param dummy 标记。
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor);
}
在父类 HashSet 中,专为 LinkedHashSet 提供的构造方法如下,该方法为包访问权限,并未对外公开。
由上述源代码可见,LinkedHashSet 通过继承 HashSet,底层使用 LinkedHashMap,以很简单明了的方式来实现了其自身的所有功能。
总结
以上就是关于 LinkedHashSet 的内容,我们只是从概述上以及构造方法这几个方面介绍了,并不是我们不想去深入其读取或者写入方法,而是其本身没有实现,只是继承于父类 HashSet 的方法。
所以我们需要注意的点是:
LinkedHashSet 是 Set 的一个具体实现,其维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可为插入顺序或是访问顺序。
LinkedHashSet 继承与 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 Hashmap 实现一样,不过还是有一点点区别的(具体的区别大家可以自己去思考一下)。
如果我们需要迭代的顺序为插入顺序或者访问顺序,那么 LinkedHashSet 是需要你首先考虑的。
JAVA提高十九:WeakHashMap&EnumMap&LinkedHashMap&LinkedHashSet深入分析的更多相关文章
- “全栈2019”Java第九十九章:局部内部类与继承详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- “全栈2019”Java第二十九章:数组详解(中篇)
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- “全栈2019”Java第十九章:关系运算符、条件运算符和三元运算符
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- java提高篇(九)-----实现多重继承
多重继承指的是一个类可以同时从多于一个的父类那里继承行为和特征,然而我们知道Java为了保证数据安全,它只允许单继承.有些时候我们会认为如果系统中需要使用多重继承往往都是糟糕的设计,这个时候我们往往需 ...
- JAVA提高十四:HashSet深入分析
前面我们介绍了HashMap,Hashtable,那么还有一个hash家族,那就是HashSet;在讲解HashSet前,大家先要知道的是HashSet是单值集合的接口,即是Collection下面的 ...
- JAVA提高十:ArrayList 深入分析
前面一章节,我们介绍了集合的类图,那么本节将学习Collection 接口中最常用的子类ArrayList类,本章分为下面几部分讲解(说明本章采用的JDK1.6源码进行分析,因为个人认为虽然JDK1. ...
- JAVA提高十二:HashMap深入分析
首先想说的是关于HashMap源码的分析园子里面应该有很多,并且都是分析得很不错的文章,但是我还是想写出自己的学习总结,以便加深自己的理解,因此就有了此文,另外因为小孩过来了,因此更新速度可能放缓了, ...
- Java提高十六:TreeMap深入分析
上一篇容器元素比较Comparable&Comparator分析的时候,我们提到了TreeMap,但没有去细致分析它,只是说明其在添加元素的时候可以进行比较,从而使得集合有序,但是怎么做的呢? ...
- 【java提高】---HashSet 与TreeSet和LinkedHashSet的区别
HashSet 与TreeSet和LinkedHashSet的区别 今天项目开发,需要通过两个条件去查询数据库数据,同时只要满足一个条件就可以取出这个对象.所以通过取出的数据肯定会有重复,所以要去掉重 ...
随机推荐
- ASP.NET Core 2.0 in Docker on Windows Container
安装Docker for Windows https://store.docker.com/editions/community/docker-ce-desktop-windows 要想将一个ASP. ...
- linux安装redis-3.0.7
一.Redis介绍 1.简介 Redis是当前比较热门的NOSQL系统之一,它是一个key-value存储系统.和Memcache类似,但很大程度补偿了Memcache的不足,它支持存储的value类 ...
- LeetCode 448. Find All Numbers Disappeared in an Array (在数组中找到没有出现的数字)
Given an array of integers where 1 ≤ a[i] ≤ n (n = size of array), some elements appear twice and ot ...
- LeetCode 1. Two Sum (两数之和)
Given an array of integers, return indices of the two numbers such that they add up to a specific ta ...
- 微软Tech Summit 2017,微软携手Unity打造MR之夜
2017年10月31日至11月3日,微软将在北京举办Tech Summit 2017技术暨生态大会.今年的大会不仅有大咖级人物带来的十二大主题.百余场课程,而且还会迎来最特别的一位嘉宾--微软公司首席 ...
- Spring MVC前后端的数据传输
本篇文章主要介绍了Spring MVC中如何在前后端传输数据. 后端 ➡ 前端 在Spring MVC中这主要通过Model将数据从后端传送到前端,一般的写法为: @RequestMapping(va ...
- css3+div画大风车
今天已经礼拜三了,周天小颖家的佩佩就要结婚啦,小颖要去当伴娘了,哈哈哈哈哈哈,想想都觉得乐开了花,不过之前她给我说让我当她伴娘时,我说我要减肥,不然她那么瘦弱,我站旁边就感觉像一个圆滚滚的小皮球,小颖 ...
- hihocoder 1015题
代码 #include <iostream> #include <string> #include <typeinfo> #include <vector&g ...
- VS2012环境下C#调用C++生成的DLL
1.VS2012 C++生成DLL 这个过程仿照http://www.cnblogs.com/LCCRNblog/p/3625200.html创建DLL即可,暂时不用创建测试工程,因为下面有测试工程的 ...
- IdentityServer4 指定角色授权(Authorize(Roles="admin"))
1. 业务场景 IdentityServer4 授权配置Client中的AllowedScopes,设置的是具体的 API 站点名字,也就是使用方设置的ApiName,示例代码: //授权中心配置 n ...