CNN之池化层tf.nn.max_pool | tf.nn.avg_pool | tf.reduce_mean | padding的规则解释
摘要:池化层的主要目的是降维,通过滤波器映射区域内取最大值、平均值等操作。
均值池化:tf.nn.avg_pool(input,ksize,strides,padding)
最大池化:tf.nn.max_pool(input,ksize,strides,padding)
input:通常情况下是卷积层输出的featuremap,shape=[batch,height,width,channels]
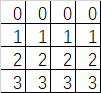
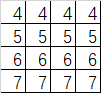
假定这个矩阵就是卷积层输出的featuremap(2通道输出) 他的shape=[1,4,4,2]
ksize:池化窗口大小 shape=[batch,height,width,channels] 比如[1,2,2,1]
strides: 窗口在每一个维度上的移动步长 shape=[batch,stride,stride,channel] 比如[1,2,2,1]
padding:“VALID”不填充 “SAME”填充0
返回:tensor shape=[batch,height,width,channels]
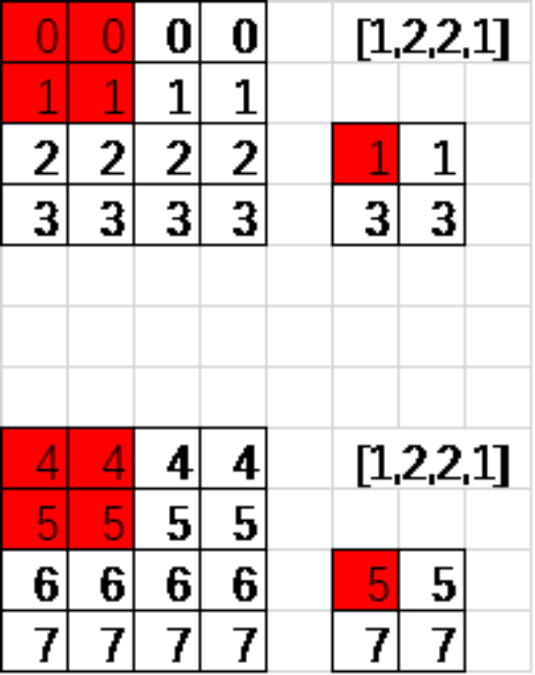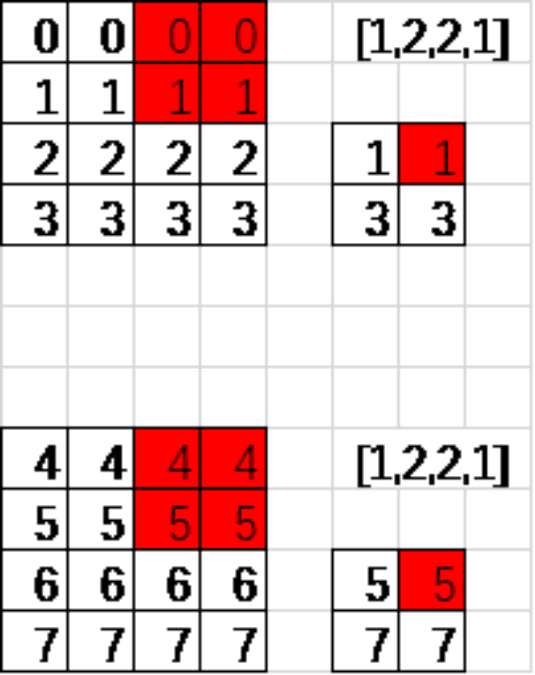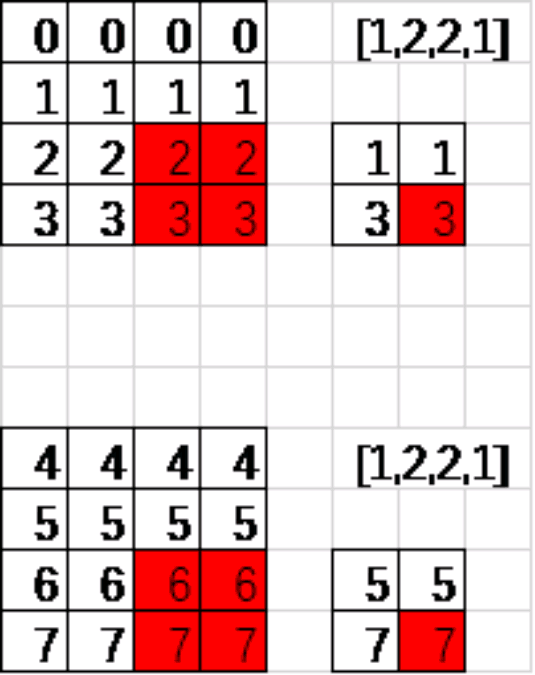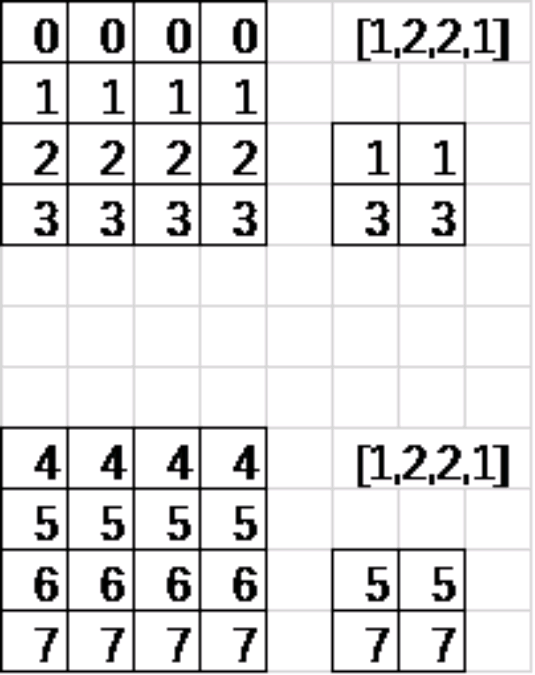
上图是采用的最大池化,取红色框内最大的一个数。
import tensorflow as tf
feature_map = tf.constant([
[[0.0,4.0],[0.0,4.0],[0.0,4.0],[0.0,4.0]],
[[1.0,5.0],[1.0,5.0],[1.0,5.0],[1.0,5.0]],
[[2.0,6.0],[2.0,6.0],[2.0,6.0],[2.0,6.0]] ,
[[3.0,7.0],[3.0,7.0],[3.0,7.0],[3.0,7.0]]
])
feature_map = tf.reshape(feature_map,[1,4,4,2])##两通道featuremap输入 ##定义池化层
pooling = tf.nn.max_pool(feature_map,[1,2,2,1],[1,2,2,1],padding='VALID')##池化窗口2*2,高宽方向步长都为2,不填充
pooling1 = tf.nn.max_pool(feature_map,[1,2,2,1],[1,1,1,1],padding='VALID')##池化窗口2*2,高宽方向步长都为1,不填充
pooling2 = tf.nn.avg_pool(feature_map,[1,4,4,1],[1,1,1,1],padding='SAME')##池化窗口4*4,高宽方向步长都为1,填充
pooling3 = tf.nn.avg_pool(feature_map,[1,4,4,1],[1,4,4,1],padding='SAME')##池化窗口4*4,高宽方向步长都为4,填充
##转置变形(详细解释参考另一篇博文)
tran_reshape = tf.reshape(tf.transpose(feature_map),[-1,16])
pooling4 = tf.reduce_mean(tran_reshape,1) ###对行值求平均
with tf.Session() as sess:
print('featuremap:\n',sess.run(feature_map))
print('*'*30)
print('pooling:\n',sess.run(pooling))
print('*'*30)
print('pooling1:\n',sess.run(pooling1))
print('*'*30)
print('pooling2:\n',sess.run(pooling2))
print('*'*30)
print('pooling3:\n',sess.run(pooling3))
print('*'*30)
print('pooling4:\n',sess.run(pooling4))
'''
输出结果:
featuremap:
[[[[ 0. 4.]
[ 0. 4.]
[ 0. 4.]
[ 0. 4.]] [[ 1. 5.]
[ 1. 5.]
[ 1. 5.]
[ 1. 5.]] [[ 2. 6.]
[ 2. 6.]
[ 2. 6.]
[ 2. 6.]] [[ 3. 7.]
[ 3. 7.]
[ 3. 7.]
[ 3. 7.]]]]
******************************
pooling:
[[[[ 1. 5.]
[ 1. 5.]] [[ 3. 7.]
[ 3. 7.]]]]
******************************
pooling1:
[[[[ 1. 5.]
[ 1. 5.]
[ 1. 5.]] [[ 2. 6.]
[ 2. 6.]
[ 2. 6.]] [[ 3. 7.]
[ 3. 7.]
[ 3. 7.]]]]
******************************
pooling2:
[[[[ 1. 5. ]
[ 1. 5. ]
[ 1. 5. ]
[ 1. 5. ]] [[ 1.5 5.5]
[ 1.5 5.5]
[ 1.5 5.5]
[ 1.5 5.5]] [[ 2. 6. ]
[ 2. 6. ]
[ 2. 6. ]
[ 2. 6. ]] [[ 2.5 6.5]
[ 2.5 6.5]
[ 2.5 6.5]
[ 2.5 6.5]]]]
******************************
pooling3:
[[[[ 1.5 5.5]]]]
******************************
pooling4:
[ 1.5 5.5] '''
池化层常用函数及参数
现在我们对代码中的内容加以解释:
padding的规则
- padding=‘VALID’时,输出的宽度和高度的计算公式(下图gif为例)

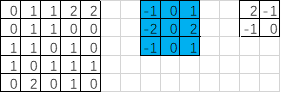
输出宽度:output_width = (in_width-filter_width+1)/strides_width =(5-3+1)/2=1.5【向上取整=2】
输出高度:output_height = (in_height-filter_height+1)/strides_height =(5-3+1)/2=1.5【向上取整=2】
输出的形状[1,2,2,1]

import tensorflow as tf
image = [0,1.0,1,2,2,0,1,1,0,0,1,1,0,1,0,1,0,1,1,1,0,2,0,1,0]
input = tf.Variable(tf.constant(image,shape=[1,5,5,1])) ##1通道输入
fil1 = [-1.0,0,1,-2,0,2,-1,0,1]
filter = tf.Variable(tf.constant(fil1,shape=[3,3,1,1])) ##1个卷积核对应1个featuremap输出 op = tf.nn.conv2d(input,filter,strides=[1,2,2,1],padding='VALID') ##步长2,VALID不补0操作 init = tf.global_variables_initializer() with tf.Session() as sess:
sess.run(init)
# print('input:\n', sess.run(input))
# print('filter:\n', sess.run(filter))
print('op:\n',sess.run(op)) ##输出结果
'''
[[[[ 2.]
[-1.]] [[-1.]
[ 0.]]]]
'''
tensorflow中实现(步长2)
如果strides=[1,3,3,1]的情况又是如何呢?
输出宽度:output_width = (in_width-filter_width+1)/strides_width =(5-3+1)/3=1
输出高度:output_height = (in_height-filter_height+1)/strides_height =(5-3+1)/3=1
输出的形状[1,1,1,1],因此输出的结果只有一个
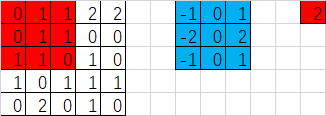
import tensorflow as tf
image = [0,1.0,1,2,2,0,1,1,0,0,1,1,0,1,0,1,0,1,1,1,0,2,0,1,0]
input = tf.Variable(tf.constant(image,shape=[1,5,5,1])) ##1通道输入
fil1 = [-1.0,0,1,-2,0,2,-1,0,1]
filter = tf.Variable(tf.constant(fil1,shape=[3,3,1,1])) ##1个卷积核对应1个featuremap输出 op = tf.nn.conv2d(input,filter,strides=[1,3,3,1],padding='VALID') ##步长2,VALID不补0操作 init = tf.global_variables_initializer() with tf.Session() as sess:
sess.run(init)
# print('input:\n', sess.run(input))
# print('filter:\n', sess.run(filter))
print('op:\n',sess.run(op)) ##输出结果
'''
op:
[[[[ 2.]]]]
'''
tensorflow中实现(步长3)
padding=‘SAME’时,输出的宽度和高度的计算公式(下图gif为例)

输出宽度:output_width = in_width/strides_width=5/2=2.5【向上取整3】
输出高度:output_height = in_height/strides_height=5/2=2.5【向上取整3】
则输出的形状:[1,3,3,1]
那么padding补0的规则又是如何的呢?【先确定输出形状,再计算补多少0】
pad_width = max((out_width-1)*strides_width+filter_width-in_width,0)=max((3-1)*2+3-5,0)=2
pad_height = max((out_height-1)*strides_height+filter_height-in_height,0)=max((3-1)*2+3-5,0)=2
pad_top = pad_height/2=1
pad_bottom = pad_height-pad_top=1
pad_left = pad_width/2=1
pad_right = pad_width-pad_left=1
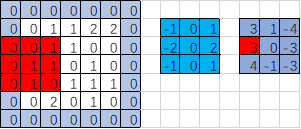
import tensorflow as tf
image = [0,1.0,1,2,2,0,1,1,0,0,1,1,0,1,0,1,0,1,1,1,0,2,0,1,0]
input = tf.Variable(tf.constant(image,shape=[1,5,5,1])) ##1通道输入
fil1 = [-1.0,0,1,-2,0,2,-1,0,1]
filter = tf.Variable(tf.constant(fil1,shape=[3,3,1,1])) ##1个卷积核对应1个featuremap输出 op = tf.nn.conv2d(input,filter,strides=[1,2,2,1],padding='SAME') ##步长2,VALID不补0操作 init = tf.global_variables_initializer() with tf.Session() as sess:
sess.run(init)
# print('input:\n', sess.run(input))
# print('filter:\n', sess.run(filter))
print('op:\n',sess.run(op)) ##输出结果
'''
op:
[[[[ 3.]
[ 1.]
[-4.]] [[ 3.]
[ 0.]
[-3.]] [[ 4.]
[-1.]
[-3.]]]]
'''
SAME步长2
如果步长为3呢?补0的规则又如何?
输出宽度:output_width = in_width/strides_width=5/3=2
输出高度:output_height = in_height/strides_height=5/3=2
则输出的形状:[1,2,2,1]
那么padding补0的规则又是如何的呢?【先确定输出形状,再计算补多少0】
pad_width = max((out_width-1)*strides_width+filter_width-in_width,0)=max((2-1)*3+3-5,0)=1
pad_height = max((out_height-1)*strides_height+filter_height-in_height,0)=max((2-1)*3+3-5,0)=1
pad_top = pad_height/2=0【向下取整】
pad_bottom = pad_height-pad_top=1
pad_left = pad_width/2=0【向下取整】
pad_right = pad_width-pad_left=1
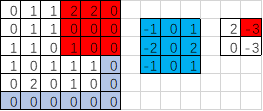
import tensorflow as tf
print(3/2)
image = [0,1.0,1,2,2,0,1,1,0,0,1,1,0,1,0,1,0,1,1,1,0,2,0,1,0]
input = tf.Variable(tf.constant(image,shape=[1,5,5,1])) ##1通道输入
fil1 = [-1.0,0,1,-2,0,2,-1,0,1]
filter = tf.Variable(tf.constant(fil1,shape=[3,3,1,1])) ##1个卷积核对应1个featuremap输出 op = tf.nn.conv2d(input,filter,strides=[1,3,3,1],padding='SAME') ##步长2,VALID不补0操作 init = tf.global_variables_initializer() with tf.Session() as sess:
sess.run(init)
# print('input:\n', sess.run(input))
# print('filter:\n', sess.run(filter))
print('op:\n',sess.run(op)) ##输出结果
'''
op:
[[[[ 2.]
[-3.]] [[ 0.]
[-3.]]]]
'''
SAME步长3
这里借用的卷积中的padding规则,在池化层中的padding规则与卷积中的padding规则一致
CNN之池化层tf.nn.max_pool | tf.nn.avg_pool | tf.reduce_mean | padding的规则解释的更多相关文章
- 深入解析CNN pooling 池化层原理及其作用
原文地址:https://blog.csdn.net/CVSvsvsvsvs/article/details/90477062 池化层作用机理我们以最简单的最常用的max pooling最大池化层为例 ...
- tensorflow的卷积和池化层(二):记实践之cifar10
在tensorflow中的卷积和池化层(一)和各种卷积类型Convolution这两篇博客中,主要讲解了卷积神经网络的核心层,同时也结合当下流行的Caffe和tf框架做了介绍,本篇博客将接着tenso ...
- TensorFlow 池化层
在 TensorFlow 中使用池化层 在下面的练习中,你需要设定池化层的大小,strides,以及相应的 padding.你可以参考 tf.nn.max_pool().Padding 与卷积 pad ...
- 【深度学习篇】--神经网络中的池化层和CNN架构模型
一.前述 本文讲述池化层和经典神经网络中的架构模型. 二.池化Pooling 1.目标 降采样subsample,shrink(浓缩),减少计算负荷,减少内存使用,参数数量减少(也可防止过拟合)减少输 ...
- tensorflow CNN 卷积神经网络中的卷积层和池化层的代码和效果图
tensorflow CNN 卷积神经网络中的卷积层和池化层的代码和效果图 因为很多 demo 都比较复杂,专门抽出这两个函数,写的 demo. 更多教程:http://www.tensorflown ...
- 第十三节,使用带有全局平均池化层的CNN对CIFAR10数据集分类
这里使用的数据集仍然是CIFAR-10,由于之前写过一篇使用AlexNet对CIFAR数据集进行分类的文章,已经详细介绍了这个数据集,当时我们是直接把这些图片的数据文件下载下来,然后使用pickle进 ...
- CNN学习笔记:池化层
CNN学习笔记:池化层 池化 池化(Pooling)是卷积神经网络中另一个重要的概念,它实际上是一种形式的降采样.有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见 ...
- ubuntu之路——day17.3 简单的CNN和CNN的常用结构池化层
来看上图的简单CNN: 从39x39x3的原始图像 不填充且步长为1的情况下经过3x3的10个filter卷积后 得到了 37x37x10的数据 不填充且步长为2的情况下经过5x5的20个filter ...
- CNN中卷积层 池化层反向传播
参考:https://blog.csdn.net/kyang624823/article/details/78633897 卷积层 池化层反向传播: 1,CNN的前向传播 a)对于卷积层,卷积核与输入 ...
随机推荐
- Spark2.0基于广播变量broadcast实现实时数据按天统计
package com.gm.hive.SparkHive; import java.text.SimpleDateFormat; import java.util.Arrays; import ja ...
- linux 配置 Sersync
[root@SERSYNC sersync]# cp conf/confxml.xml conf/confxml.xml.bak.$(date +%F) [root@SERSYNC sersync]# ...
- ls 显示目录下的内容和文件相关属性信息
1.命令功能 ls命令是“list directory contents”,显示当前目录下的内容和文件属性. 2.语法格式 ls [option] file ls 选项 文件名 3.选项说明 ...
- 解决Debug JDK source 无法查看局部变量的问题方案
一.问题阐述首先我们要明白JDK source为什么在debug的时候无法观察局部变量,因为在jdk中,sun对rt.jar中的类编译时,去除了调试信息,这样在eclipse中就不能看到局部变量的值. ...
- D0g3_Trash_Pwn_Writeup
Trash Pwn 下载文件 1 首先使用checksec查看有什么保护 可以发现,有canary保护(Stack),堆栈不可执行(NX),地址随机化没有开启(PIE) 2 使用IDA打开看看 mai ...
- Task8.循环和递归神经网络
RNN提出的背景: RNN通过每层之间节点的连接结构来记忆之前的信息,并利用这些信息来影响后面节点的输出.RNN可充分挖掘序列数据中的时序信息以及语义信息,这种在处理时序数据时比全连接神经网络和CNN ...
- 在Mac电脑上使用NTFS移动硬盘遇到问题
1.sudo nano/etc/fstab 回车 输电脑密码 2.进入文本插入页面 编入: LABEL=硬盘名字 NONE ntfs rw,auto,nobrowse 3.ctrl + X 退出 选 ...
- Primary Key Increase by Trigger
Oracle Create Table: CREATE TABLE TAB( ID NUMBER(10) NOT NULL PRIMARY KEY, NAME VARCHAR(19) NOT NULL ...
- Prime算法 与 Kruskal算法求最小生成树模板
算法原理参考链接 ==> UESTC算法讲堂——最小生成树 关于两种算法的复杂度分析 ==> http://blog.csdn.net/haskei/article/details/531 ...
- codeforces 848B - Rooter's Song(构造+几何)
原题链接:http://codeforces.com/problemset/problem/848/B 题意:好多个人分别从x,y轴不同位置不同时间往垂直坐标轴方向移动,一旦相遇他们转向,问所有人的到 ...