flume(2)
接续上一篇:https://www.cnblogs.com/metianzing/p/9511852.html
这里也是主要记录配置文件。
以上一篇案例五为基础,考虑到日志服务器和采集日志的服务器往往不是一台,本篇采用多agent的形式。
agent1: source:TAILDIR
sink:avro
agent2: source:avro
sink:kafka
1>agent1配置文件
cd /usr/local/flume/conf
vim agent1_abtd.conf
编写 agent1_abtd.conf,内容如下:
# Name the components on this agent
agent1.sources = s1
agent1.sinks = k1
agent1.channels = ch1 # Describe/configure the source
agent1.sources.s1.type = TAILDIR
agent1.sources.s1.positionFile = /opt/classiclaw/nginx/logs/abtd_magent/taildir_position.json
agent1.sources.s1.filegroups = f1
agent1.sources.s1.filegroups.f1 = /opt/classiclaw/nginx/logs/access.log.*
agent1.sources.s1.headers.f1.headerKey1 = value1
agent1.sources.s1.fileHeader = true # Describe the sink
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = ubuntu
agent1.sinks.k1.port = 44444 # Set channel
agent1.channels.ch1.type = file
agent1.channels.ch1.checkpointDir = /opt/classiclaw/nginx/logs/flume_data/checkpoint
agent1.channels.ch1.dataDirs = /opt/classiclaw/nginx/logs/flume_data/data # bind
agent1.sources.s1.channels = ch1
agent1.sinks.k1.channel = ch1
2> agent2配置文件
cd /usr/local/flume/conf
vim agent2_abtd.conf
编写agent2_abtd.conf ,内容如下:
# Name the components on this agent
agent2.sources = s2
agent2.sinks = k2
agent2.channels = ch2 # Describe/configure the source
agent2.sources.s2.type = avro
agent2.sources.s2.bind = 0.0.0.0
agent2.sources.s2.port = 44444 # Describe the sink
agent2.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
agent2.sinks.k2.brokerList = ubuntu:9092
agent2.sinks.k2.topic = abtd_magent
agent2.sinks.k2.kafka.flumeBatchSize = 20
agent2.sinks.k2.kafka.producer.acks = 1
agent2.sinks.k2.kafka.producer.linger.ms = 1
agent2.sinks.k2.kafka.producer.compression.type = snappy # set channel
agent2.channels.ch2.type = memory
agent2.channels.ch2.capacity = 1000000
agent2.channels.ch2.transactionCapacity = 1000000 # Bind the source and sink to the channel
agent2.sources.s2.channels = ch2
agent2.sinks.k2.channel = ch2
3>创建 topic:abtd_magent
前提是已经启动zookeeper和Kafka。
cd /usr/local/kafka
./bin/kafka-topics.sh --zookeeper ubuntu:2181 --create --topic abtd_magent --replication-factor 1 --partitions 3
4>启动agent2
cd /usr/local/flume
./bin/flume-ng agent --name agent2 --conf conf/ --conf-file conf/agent2_abtd.conf -Dflume.root.logger=INFO,console

5>启动agent1
cd /usr/local/flume
./bin/flume-ng agent --name agent1 --conf conf/ --conf-file conf/agent1_abtd.conf -Dflume.root.logger=INFO,console
6>agent1 :添加文件到flume source目录
cd /opt/classiclaw/nginx/logs
echo -e "this is a test file! \nhttp://www.aboutyun.com20170820">access.log.1
7>查看kafka consumer
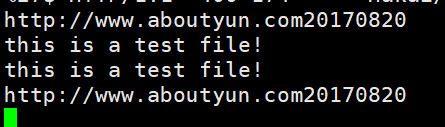
agent1:
flume(2)的更多相关文章
- Flume1 初识Flume和虚拟机搭建Flume环境
前言: 工作中需要同步日志到hdfs,以前是找运维用rsync做同步,现在一般是用flume同步数据到hdfs.以前为了工作简单看个flume的一些东西,今天下午有时间自己利用虚拟机搭建了 ...
- Flume(4)实用环境搭建:source(spooldir)+channel(file)+sink(hdfs)方式
一.概述: 在实际的生产环境中,一般都会遇到将web服务器比如tomcat.Apache等中产生的日志倒入到HDFS中供分析使用的需求.这里的配置方式就是实现上述需求. 二.配置文件: #agent1 ...
- Flume(3)source组件之NetcatSource使用介绍
一.概述: 本节首先提供一个基于netcat的source+channel(memory)+sink(logger)的数据传输过程.然后剖析一下NetcatSource中的代码执行逻辑. 二.flum ...
- Flume(2)组件概述与列表
上一节搭建了flume的简单运行环境,并提供了一个基于netcat的演示.这一节继续对flume的整个流程进行进一步的说明. 一.flume的基本架构图: 下面这个图基本说明了flume的作用,以及f ...
- Flume(1)使用入门
一.概述: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统. 当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X ...
- 大数据平台架构(flume+kafka+hbase+ELK+storm+redis+mysql)
上次实现了flume+kafka+hbase+ELK:http://www.cnblogs.com/super-d2/p/5486739.html 这次我们可以加上storm: storm-0.9.5 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- flume使用示例
flume的特点: flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受 ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
- Flume NG Getting Started(Flume NG 新手入门指南)
Flume NG Getting Started(Flume NG 新手入门指南)翻译 新手入门 Flume NG是什么? 有什么改变? 获得Flume NG 从源码构建 配置 flume-ng全局选 ...
随机推荐
- 多进程---multiprocessing/threading/
一.多进程:multiprocessing模块 多用于处理CPU密集型任务 多线程 多用于IO密集型任务 Input Ouput 举例: import multiprocessing,threadin ...
- 数论-欧拉函数-LightOJ - 1370
我是知道φ(n)=n-1,n为质数 的,然后给的样例在纸上一算,嗯,好像是找往上最近的质数就行了,而且有些合数的欧拉函数值还会比比它小一点的质数的欧拉函数值要小,所以坚定了往上找最近的质数的决心—— ...
- (转)http://blog.chinaunix.net/uid-8363656-id-2031644.html CGI 编写
第一章:基础的基础 回CGI教程目录 1.1 为什么使用CGI? 我没有把什么是CGI放在基础篇的第一段,是因为实在很难说明白到底什么是CGI.而如果你先知道CGI有什么作用,将会很好的理解CGI ...
- Sentinel整合Dubbo限流实战(分布式限流)
之前我们了解了 Sentinel 集成 SpringBoot实现限流,也探讨了Sentinel的限流基本原理,那么接下去我们来学习一下Sentinel整合Dubbo及 Nacos 实现动态数据源的限流 ...
- MySQL-第十四篇事务管理
1.什么是事务 事务是由一步或者几步数据库操作序列组成的逻辑执行单元,这系列操作要么全部执行,要么全部放弃执行. 2.事务具备的4个特性: 1>原子性(Atomicity):事务是应用中最小的执 ...
- jmeter测试结果jtl字段分析
1 Bytes Throughput Over Time 每秒传输字节吞吐量,表明Jmeter在测试时,随着时间推移发送和接受的字节数 2 Response Codes per Second ...
- HDU_2007
/** *注意:输入的两个数字的大小并不确定 */ #include <iostream> #include <stdio.h> #include <string.h&g ...
- highcharts控制X刻度值整数调整
function chartData() { var app_id = $('.app_id').attr('app_id'); var gener_id = $('.gener_id').attr( ...
- spark sql 操作
DSL风格语法 1.查看DataFrame中的内容 scala> df1.show +---+--------+---+ | id| name|age| +---+--------+---+ | ...
- spring,get请求中带date日期格式参数,后台无法转换的问题
今天遇到个很奇怪的问题.前端 的查询条件中带有日期范围日期的格式 是 yyyy-MM-dd HH:mm 结果后台报错 org.springframework.validation.BindExcept ...