flume(2)
接续上一篇:https://www.cnblogs.com/metianzing/p/9511852.html
这里也是主要记录配置文件。
以上一篇案例五为基础,考虑到日志服务器和采集日志的服务器往往不是一台,本篇采用多agent的形式。
agent1: source:TAILDIR
sink:avro
agent2: source:avro
sink:kafka
1>agent1配置文件
cd /usr/local/flume/conf
vim agent1_abtd.conf
编写 agent1_abtd.conf,内容如下:
# Name the components on this agent
agent1.sources = s1
agent1.sinks = k1
agent1.channels = ch1 # Describe/configure the source
agent1.sources.s1.type = TAILDIR
agent1.sources.s1.positionFile = /opt/classiclaw/nginx/logs/abtd_magent/taildir_position.json
agent1.sources.s1.filegroups = f1
agent1.sources.s1.filegroups.f1 = /opt/classiclaw/nginx/logs/access.log.*
agent1.sources.s1.headers.f1.headerKey1 = value1
agent1.sources.s1.fileHeader = true # Describe the sink
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = ubuntu
agent1.sinks.k1.port = 44444 # Set channel
agent1.channels.ch1.type = file
agent1.channels.ch1.checkpointDir = /opt/classiclaw/nginx/logs/flume_data/checkpoint
agent1.channels.ch1.dataDirs = /opt/classiclaw/nginx/logs/flume_data/data # bind
agent1.sources.s1.channels = ch1
agent1.sinks.k1.channel = ch1
2> agent2配置文件
cd /usr/local/flume/conf
vim agent2_abtd.conf
编写agent2_abtd.conf ,内容如下:
# Name the components on this agent
agent2.sources = s2
agent2.sinks = k2
agent2.channels = ch2 # Describe/configure the source
agent2.sources.s2.type = avro
agent2.sources.s2.bind = 0.0.0.0
agent2.sources.s2.port = 44444 # Describe the sink
agent2.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
agent2.sinks.k2.brokerList = ubuntu:9092
agent2.sinks.k2.topic = abtd_magent
agent2.sinks.k2.kafka.flumeBatchSize = 20
agent2.sinks.k2.kafka.producer.acks = 1
agent2.sinks.k2.kafka.producer.linger.ms = 1
agent2.sinks.k2.kafka.producer.compression.type = snappy # set channel
agent2.channels.ch2.type = memory
agent2.channels.ch2.capacity = 1000000
agent2.channels.ch2.transactionCapacity = 1000000 # Bind the source and sink to the channel
agent2.sources.s2.channels = ch2
agent2.sinks.k2.channel = ch2
3>创建 topic:abtd_magent
前提是已经启动zookeeper和Kafka。
cd /usr/local/kafka
./bin/kafka-topics.sh --zookeeper ubuntu:2181 --create --topic abtd_magent --replication-factor 1 --partitions 3
4>启动agent2
cd /usr/local/flume
./bin/flume-ng agent --name agent2 --conf conf/ --conf-file conf/agent2_abtd.conf -Dflume.root.logger=INFO,console

5>启动agent1
cd /usr/local/flume
./bin/flume-ng agent --name agent1 --conf conf/ --conf-file conf/agent1_abtd.conf -Dflume.root.logger=INFO,console
6>agent1 :添加文件到flume source目录
cd /opt/classiclaw/nginx/logs
echo -e "this is a test file! \nhttp://www.aboutyun.com20170820">access.log.1
7>查看kafka consumer
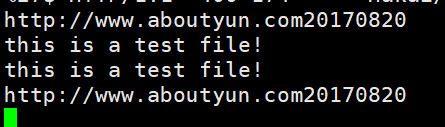
agent1:
flume(2)的更多相关文章
- Flume1 初识Flume和虚拟机搭建Flume环境
前言: 工作中需要同步日志到hdfs,以前是找运维用rsync做同步,现在一般是用flume同步数据到hdfs.以前为了工作简单看个flume的一些东西,今天下午有时间自己利用虚拟机搭建了 ...
- Flume(4)实用环境搭建:source(spooldir)+channel(file)+sink(hdfs)方式
一.概述: 在实际的生产环境中,一般都会遇到将web服务器比如tomcat.Apache等中产生的日志倒入到HDFS中供分析使用的需求.这里的配置方式就是实现上述需求. 二.配置文件: #agent1 ...
- Flume(3)source组件之NetcatSource使用介绍
一.概述: 本节首先提供一个基于netcat的source+channel(memory)+sink(logger)的数据传输过程.然后剖析一下NetcatSource中的代码执行逻辑. 二.flum ...
- Flume(2)组件概述与列表
上一节搭建了flume的简单运行环境,并提供了一个基于netcat的演示.这一节继续对flume的整个流程进行进一步的说明. 一.flume的基本架构图: 下面这个图基本说明了flume的作用,以及f ...
- Flume(1)使用入门
一.概述: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统. 当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X ...
- 大数据平台架构(flume+kafka+hbase+ELK+storm+redis+mysql)
上次实现了flume+kafka+hbase+ELK:http://www.cnblogs.com/super-d2/p/5486739.html 这次我们可以加上storm: storm-0.9.5 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- flume使用示例
flume的特点: flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受 ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
- Flume NG Getting Started(Flume NG 新手入门指南)
Flume NG Getting Started(Flume NG 新手入门指南)翻译 新手入门 Flume NG是什么? 有什么改变? 获得Flume NG 从源码构建 配置 flume-ng全局选 ...
随机推荐
- elasticsearch 7.2 集群节点配置
conf/elasticsearch.yml对其修改,在下面添加修改: 主节点的配置 http.cors.enabled: true http.cors.allow-origin: "*&q ...
- 抓包工具tcpdump用法说明--2
第一招: 通俗的说,tcpdump是一个抓包工具,用于抓取互联网上传输的数据包.形象的说,tcpdump就好比是国家海关,驻扎在出入境的咽喉要道,凡是要入境和出境的集装箱,海关人员总要打开箱子,看看里 ...
- stack() unstack()函数
总结: 1.stack: 将数据的列索引转换为行索引 2.unstack:将数据的行索引转换为列索引 3.stack和unstack默认操作为最内层,可以用level参数指定操作层. 4.stack ...
- drop_duplicates()函数
1dataframe删除某一列的重复元素,默认只留下第一次出现的 inplace参数设置为true时直接在原数据上修改,为False时,生成副本. 注意所有函数中inplace一旦设置为True,此时 ...
- javaScript 递归 闭包 私有变量
递归 递归的概念 在程序中函数直接或者间接调用自己. 跳出结构,有了跳出才有结果. 递归的思想 递归的调用,最终还是要转换为自己这个函数. 应用 function sum(n){ if(n == ...
- VS2013中使用本地IIS+域名调试ASP.NET项目
VS2013中使用本地IIS+域名调试ASP.NET项目 在有些情况下需要使用本地的IIS作为调试服务器,如支持多域名的网站,这里记录下如何使用. 1.修改本机hosts文件. 路径:C:\Windo ...
- Flask 启动配置
数据迁移.
- vue打包详情
说明 本文代码中的配置基于vue-cli2 需求 在实际开发中我们可能有测试环境一套请求API 和 正式环境一套API,尤其是两个环境的域名不同时,就需要我们分环境打不同配置的包 了解 webpack ...
- SVN检出新项目
1.新建文件夹SourseCode -->打开SourseCode文件夹,右键空白处 ---> 选择SVN Checkout --选择URL of repository,选择Checkou ...
- 通过总线机制实现自动刷新客户端配置(Consul,Spring Cloud Config,Spring Cloud Bus)
通过总线机制实现自动刷新客户端配置 方案示意图 利用Git服务的webhook通知功能,在每次更新配置之后,Git服务器会用POST方式调用配置中心的/actuator/bus-refresh接口,配 ...