论文解读(DWL)《Dynamic Weighted Learning for Unsupervised Domain Adaptation》
[ Wechat:Y466551 | 付费咨询,非诚勿扰 ]
论文信息
论文标题:Dynamic Weighted Learning for Unsupervised Domain Adaptation
论文作者:Jihong Ouyang、Zhengjie Zhang、Qingyi Meng
论文来源:2023 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
2 方法
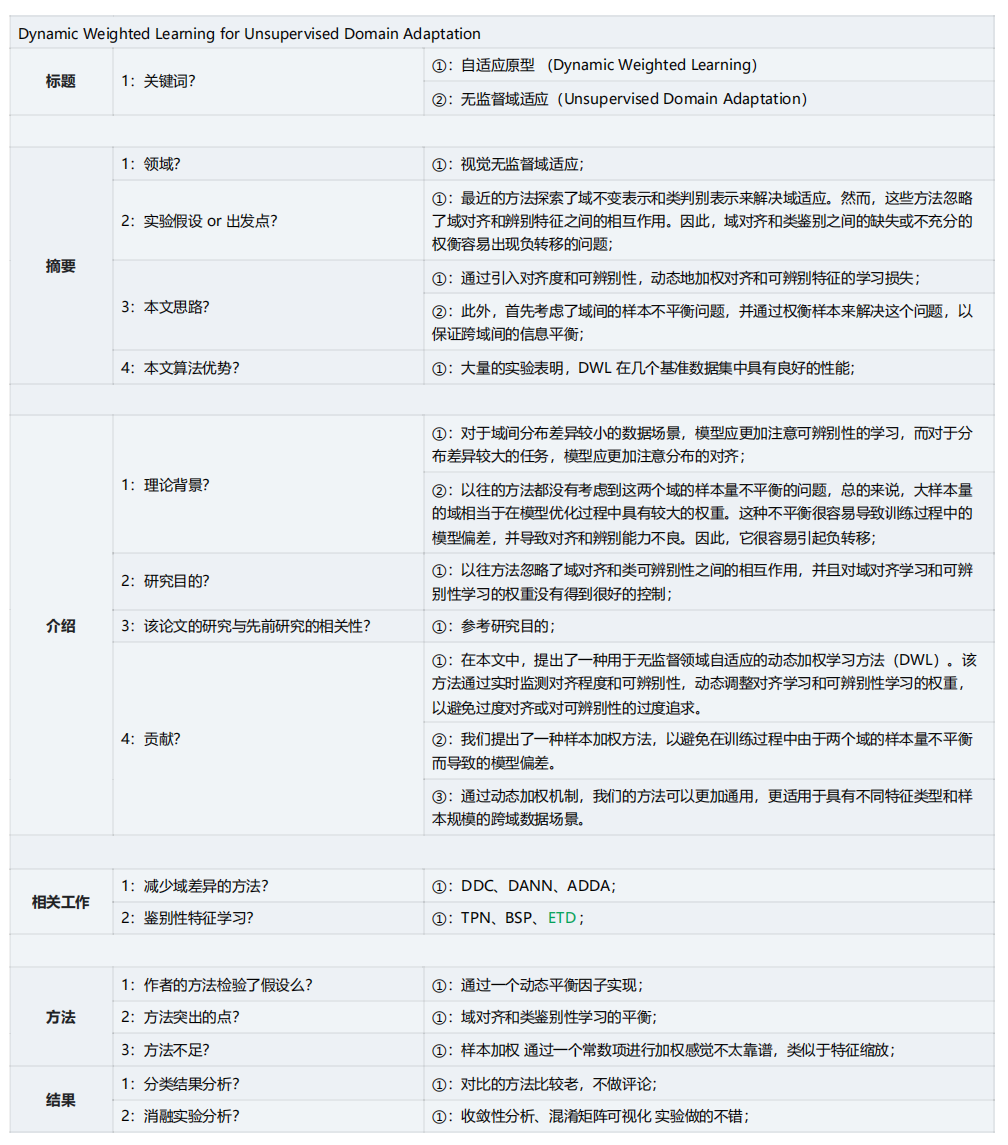
2.1 出发点
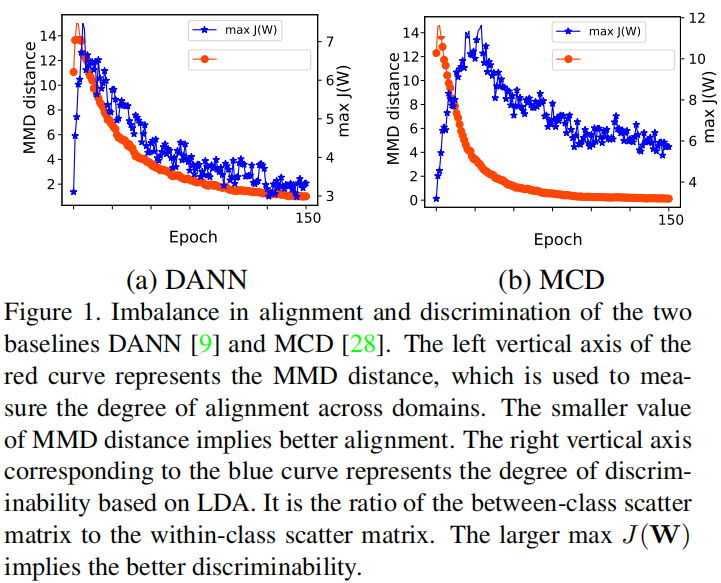
反应的问题:随着域对齐的实现,判别性在下降;
2.2 模型框架
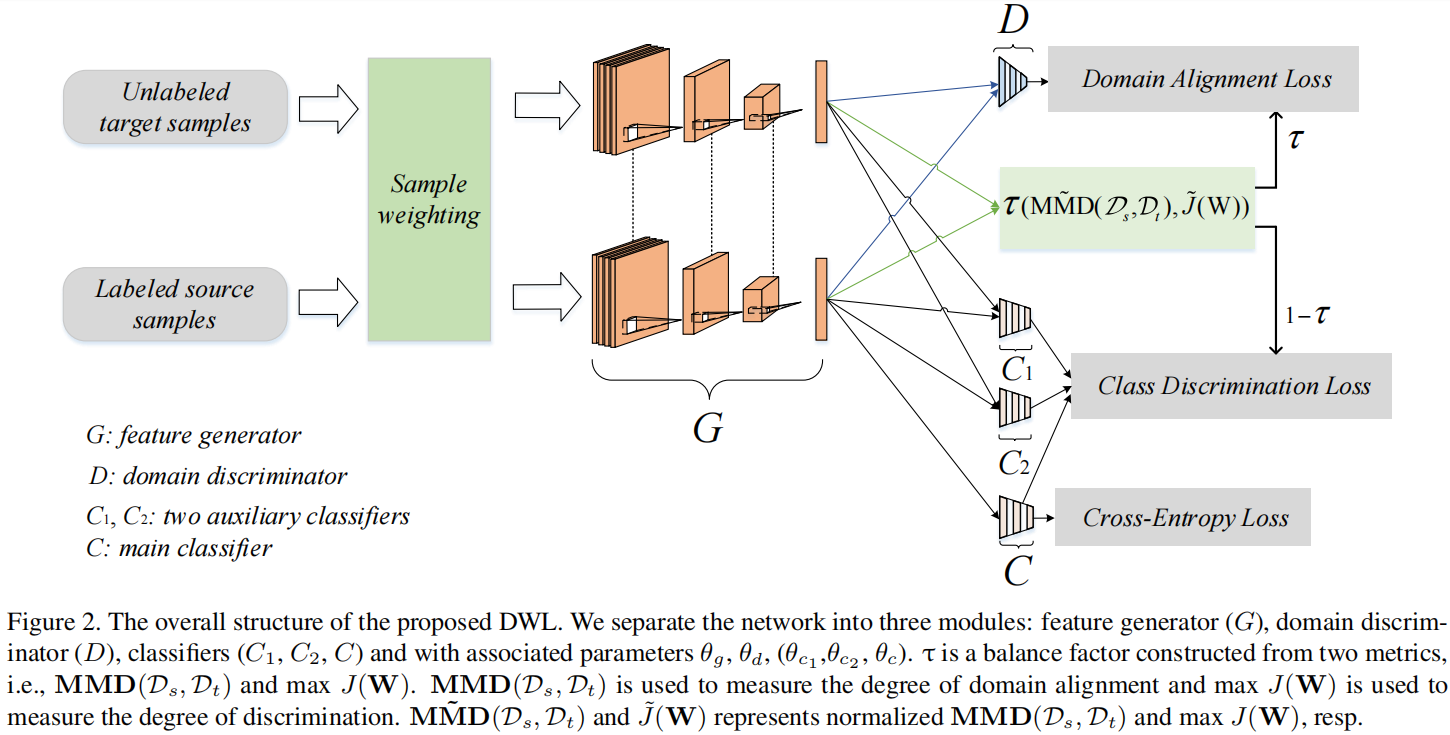
2.3 Sample Weighting
$\begin{array}{l}\hat{x}_{i}^{s}=a\left(1+\frac{n_{t}}{n_{s}}\right) x_{i}^{s} \quad, \quad i=1,2, \ldots, n_{s} \\\hat{x}_{j}^{t}=a\left(1+\frac{n_{s}}{n_{t}}\right) x_{j}^{t} \quad, \quad j=1,2, \ldots, n_{t}\end{array} $
其中,$a \in(0,1]$ 是一个控制样本加权程度的超参数。
2.4 Domain Alignment Learning and Class Discrimination Learning
域对齐(对抗性学习):
$\begin{array}{r} \underset{\theta_{g}}{\text{min}} \; \underset{\theta_{d}}{\text{max}} \; \mathcal{L}_{d a}\left(\theta_{g}, \theta_{d}\right)=\mathbb{E}_{x_{i}^{s} \sim \mathcal{D}_{s}} \log \left[D\left(G\left(\hat{x}_{i}^{s}\right)\right)\right] +\mathbb{E}_{x_{j}^{t} \sim \mathcal{D}_{t}} \log \left[1-D\left(G\left(\hat{x}_{j}^{t}\right)\right)\right]\end{array}$
鉴别性特征学习:
$\begin{aligned} \underset{\theta_{g}, \theta_{c}}{\text{min}} \; \underset{\theta_{c_{1}}, \theta_{c_{2}}}{\text{max}} \; \mathcal{L}_{c d} & \left(\theta_{g}, \theta_{c}, \theta_{c_{1}}, \theta_{c_{1}}\right) \\= & \mathbb{E}_{x_{j}^{t} \sim \mathcal{D}_{t}}\left\|C_{1}\left(G\left(\hat{x}_{j}^{t}\right)\right)-C_{2}\left(G\left(\hat{x}_{j}^{t}\right)\right)\right\|_{1} \\& +\left\|C\left(G\left(\hat{x}_{j}^{t}\right)\right)-C_{1}\left(G\left(\hat{x}_{j}^{t}\right)\right)\right\|_{1} \\& +\left\|C\left(G\left(\hat{x}_{j}^{t}\right)\right)-C_{2}\left(G\left(\hat{x}_{j}^{t}\right)\right)\right\|_{1}\end{aligned}$
Note:$C$、$C_{1}$、$C_{2}$ 是使用源域数据预训练得到的分类器。首先,固定 $G$ 和 $C$ 最大化 $C_1$ 和 $C_2$ 的差异。然后,固定 $C_{1}$ 和 $C_{2}$ 训练 $G$ 和 $C$。
2.5 Dynamic Weighted Learning
域对齐度量 [ MMD ]:
$\operatorname{MMD}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)=\left\|\mathbb{E}_{x_{i}^{s} \sim \mathcal{D}_{s}} G\left(\hat{x}_{i}^{s}\right)-\mathbb{E}_{x_{j}^{t} \sim \mathcal{D}_{t}} G\left(\hat{x}_{j}^{t}\right)\right\|^{2}$
鉴别性度量 [ LDA ]:
$\underset{\mathbf{W}}{\text{max}} \; J(\mathbf{W})=\frac{\operatorname{tr}\left(\mathbf{W}^{\top} \mathbf{S}_{\mathbf{b}} \mathbf{W}\right)}{\operatorname{tr}\left(\mathbf{W}^{\top} \mathbf{S}_{\mathbf{w}} \mathbf{W}\right)}$
其中,$\mathbf{S}_{\mathrm{b}}$ 为类间散射矩阵,$\mathbf{S}_{\mathbf{w}}$ 为类内散射矩阵。
注意:$J(\mathbf{W})$ 越大,具有更好的辨别性。
由于上述两个评价标准不在一个数量级上,本文对其进行了归一化处理:
$\begin{array}{l}\operatorname{\text{M}} \tilde{\text{M}} \text{D}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)=\frac{\operatorname{MMD}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)-\operatorname{MMD}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)_{\min }}{\operatorname{MMD}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)_{\max }-\operatorname{MMD}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)_{\min }} \end{array}$
$\tilde{J}(\mathbf{W})=\frac{J(\mathbf{W})-J(\mathbf{W})_{\min }}{J(\mathbf{W})_{\max }-J(\mathbf{W})_{\min }}$
构造一个动态平衡因子:
$\tau=\frac{\operatorname{M} \tilde{\mathbf{M}}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)}{\operatorname{M} \tilde{\mathbf{M}}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)+(1-\tilde{J}(\mathbf{W}))}$
注意:$\text{M} \tilde{\text{M}} \text{D}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)$ 越小代表这域对齐效果越好,$1-\tilde{J}(\mathbf{W})$ 越小代表这鉴别性特征越好。
- 当域对齐的程度远优于类的可辨别性时,$\text{M} \tilde{\text{M}} \text{D}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)$ 接近 $0$,$1-\tilde{J}(\mathbf{W}) $ 接近 $1$ ,$\tau$ 接近 $0$ ;
- 当域对齐程度远低于类别识别程度时,$\text{M} \tilde{\text{M}} \text{D}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)$ 接近 $1$,$1-\tilde{J}(\mathbf{W}) $ 接近 $0$ ,$\tau$ 接近 $1$ ;
基于 $\tau$ 的良好特性,采用 $\tau$ 作为域对齐损失的权重,$1−\tau $ 作为类鉴别损失的权重。因此,得到的域对齐和类鉴别的动态加权模型如下:
$\begin{array}{l} \underset{\theta_{g}, \theta_{c}}{\text{min}} \;\; \underset{\theta_{\theta_{d}, \theta_{c_{1}}, \theta_{c_{2}}}}{\text{max}} \tau \cdot \mathcal{L}_{d a}\left(\theta_{g}, \theta_{d}\right)+ (1-\tau) \cdot \mathcal{L}_{c d}\left(\theta_{g}, \theta_{c}, \theta_{c_{1}}, \theta_{c_{2}}\right)\end{array}$
- 当领域对齐学习的有效性远远低于类辨别学习时,模型增加了域对齐学习的权重;
- 当鉴别学习的学习效果远低于域对齐学习时,模型增加鉴别学习的权重;
在这种动态加权学习机制下,可以保持域对齐学习与类辨别学习之间的一致性,从而避免过度的域对齐或类可辨别性。
2.6 Overall Training Objective
总体训练目标整合了样本加权、领域对齐学习、类判别学习和动态加权学习。此外,还需要最小化标记源样本的期望源误差。最终的极大极小目标:
$\begin{array}{l}\underset{\theta_{g}, \theta_{c}}{\text{min}} \;\;\underset{\theta_{d}, \theta_{c_{1}}, \theta_{c_{2}}}{\text{max}}\sum_{i=1}^{t_{s}} \mathcal{L}_{c e}\left(C\left(G\left(x_{i}^{s} ; \theta_{g}\right) ; \theta_{c}\right), y_{i}^{s}\right) +\tau \cdot \mathcal{L}_{d a}\left(\theta_{g}, \theta_{d}\right)+(1-\tau) \cdot \mathcal{L}_{c d}\left(\theta_{g}, \theta_{c}, \theta_{c_{1}}, \theta_{c_{2}}\right)\end{array}$
3 实验
分类结果

收敛性分析
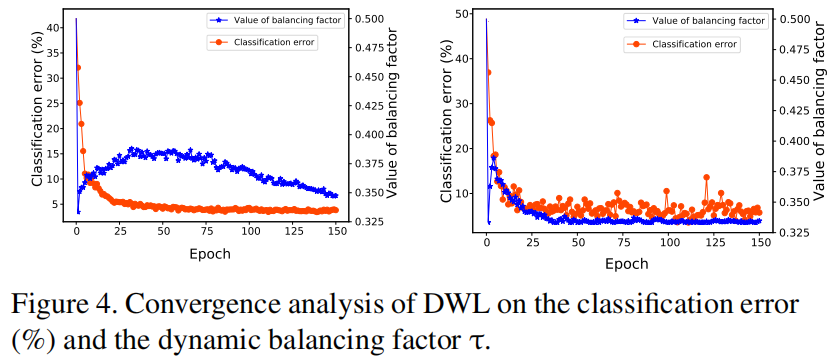
对于每个子图,红色曲线的左轴表示分类误差,蓝色曲线的右轴表示平衡因子 $\tau$ 的值。可以发现,随着迭代,它们两者都逐渐收敛到一个平坦的值。这意味着随着 $\tau$ 的减少,使得类的可鉴别性被强调,使得分类误差也减小。
在迭代过程中,当 $\tau$ 的变化相对明显时,识别精度的提高也相对明显。我们将 $\tau$ 的初始值设为 $0.5$,可以发现 $\tau$ 在第一个时期急剧下降到 $0.5$ 以下,说明该模型的对齐性相对较好,但可辨别性相对较差。
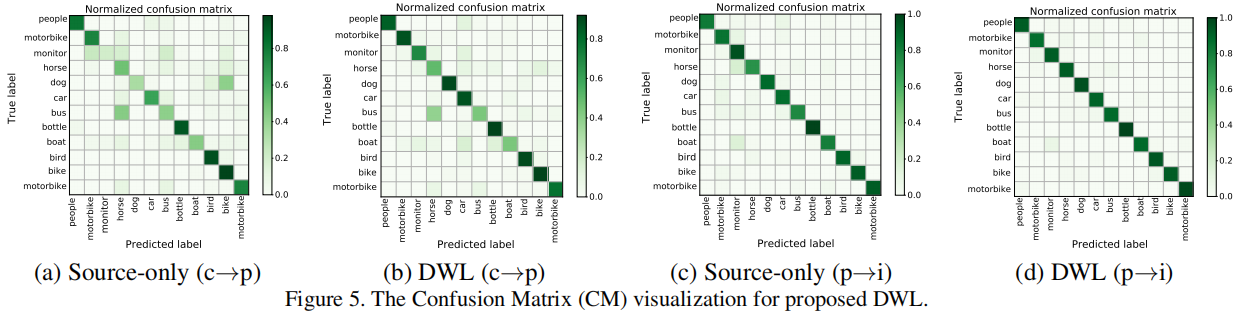
混淆矩阵可视化
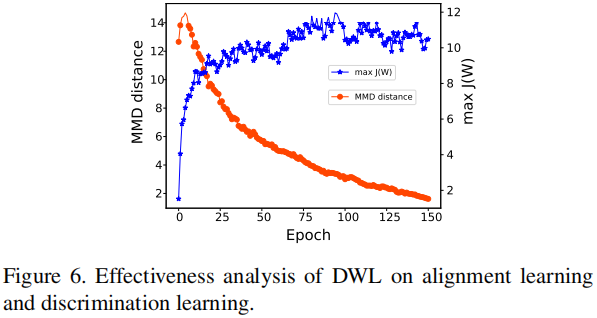
对齐度和可鉴别性度的分析
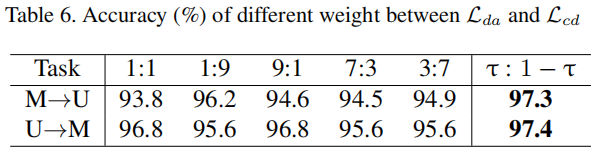
消融实验

论文解读(DWL)《Dynamic Weighted Learning for Unsupervised Domain Adaptation》的更多相关文章
- 论文解读(CDCL)《Cross-domain Contrastive Learning for Unsupervised Domain Adaptation》
论文信息 论文标题:Cross-domain Contrastive Learning for Unsupervised Domain Adaptation论文作者:Rui Wang, Zuxuan ...
- 迁移学习(DCCL)《Domain Confused Contrastive Learning for Unsupervised Domain Adaptation》
论文信息 论文标题:Domain Confused Contrastive Learning for Unsupervised Domain Adaptation论文作者:Quanyu Long, T ...
- 论文解读(CDTrans)《CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation》
论文信息 论文标题:CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation论文作者:Tongkun Xu, Weihu ...
- 论文解读(ToAlign)《ToAlign: Task-oriented Alignment for Unsupervised Domain Adaptation》
论文信息 论文标题:ToAlign: Task-oriented Alignment for Unsupervised Domain Adaptation论文作者:Guoqiang Wei, Cuil ...
- 迁移学习(CLDA)《CLDA: Contrastive Learning for Semi-Supervised Domain Adaptation》
论文信息 论文标题:CLDA: Contrastive Learning for Semi-Supervised Domain Adaptation论文作者:Ankit Singh论文来源:NeurI ...
- 论文解读(CAN)《Contrastive Adaptation Network for Unsupervised Domain Adaptation》
论文信息 论文标题:Contrastive Adaptation Network for Unsupervised Domain Adaptation论文作者:Guoliang Kang, Lu Ji ...
- 迁移学习《Asymmetric Tri-training for Unsupervised Domain Adaptation》
论文信息 论文标题:Asymmetric Tri-training for Unsupervised Domain Adaptation论文作者:Kuniaki Saito, Y. Ushiku, T ...
- 虚假新闻检测(CADM)《Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup》
论文信息 论文标题:Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversari ...
- 迁移学习(IIMT)——《Improve Unsupervised Domain Adaptation with Mixup Training》
论文信息 论文标题:Improve Unsupervised Domain Adaptation with Mixup Training论文作者:Shen Yan, Huan Song, Nanxia ...
- 迁移学习(TSRP)《Improving Pseudo Labels With Intra-Class Similarity for Unsupervised Domain Adaptation》
论文信息 论文标题:Improving Pseudo Labels With Intra-Class Similarity for Unsupervised Domain Adaptation论文作者 ...
随机推荐
- 是时候,升级你的 Windows 了「GitHub 热点速览」
不知道多少小伙伴用着 Windows 操作系统,可能会有一个烦恼是有时候操作系统过慢,因为众多拖慢 Windows 系统的组件.Atlas 作为一个修改版的 Windows 系统,能极大提高操作系统运 ...
- 解决VM虚拟机中IP或域名不能ping通
c4548abb-da65-4f7d-827f-e95dca25a13d 问题 无法ping通域名, 检查事项 确定在同一个子网,能访问DNS服务器. DNS服务器正确设置了正反向解析,且DNS服务器 ...
- 2022-12-01:从不订购的客户。找出所有从不订购任何东西的客户,以下数据的答案输出是Henry和Max,sql语句如何写? DROP TABLE IF EXISTS `customers`; C
2022-12-01:从不订购的客户.找出所有从不订购任何东西的客户,以下数据的答案输出是Henry和Max,sql语句如何写? DROP TABLE IF EXISTS `customers`; C ...
- 2022-09-14:以下go语言代码输出什么?A:0 0;B:0 1;C:1 1;D:1 0。 package main func main() { println(f(1)) } func
2022-09-14:以下go语言代码输出什么?A:0 0:B:0 1:C:1 1:D:1 0. package main func main() { println(f(1)) } func f(x ...
- 2020-11-15:手写代码:行有序、列也有序的二维数组中,找num,找到返回true,否则false?
福哥答案2020-11-15: 此题来源于leetcode240和剑指 Offer(第 2 版)面试题4.1.线性查找.从二维数组的坐下角开始查找.如果当前元素等于目标值,则返回 true.如果当前元 ...
- 2021-05-21:给定一个数组arr,先递减然后递增,返回arr中有多少个绝对值不同的数字?
2021-05-21:给定一个数组arr,先递减然后递增,返回arr中有多少个绝对值不同的数字? 福大大 答案2021-05-21: 双指针.左指针最左,符合条件时右移:右指针最右,符合条件时左移.左 ...
- Python从零到壹丨图像增强的顶帽运算和底帽运算
摘要:这篇文章详细介绍了顶帽运算和底帽运算,它们将为后续的图像分割和图像识别提供有效支撑. 本文分享自华为云社区<[Python从零到壹] 四十九.图像增强及运算篇之顶帽运算和底帽运算>, ...
- SpringMVC 后台从前端获取单个参数
1.编写web.xml(模板) 2.springmvc配置文件 3.编写对应数据库字段的pojo实体类 @Data @AllArgsConstructor @NoArgsConstructor pub ...
- Linux,会这些就够了
在测试当中,其实对Linux的要求不高,我们在工作中需要记住常用的一些命令,不常用的实际用到的时候再查在记即可,最重要我们要使用命令可以查看日志,定位bug 目录篇: 可用 pwd 命令查看用 ...
- kprobe_events shell模式使用教程
kprobe_events shell模式使用教程 kprobe 使用前提 需要内核启用以下配置 CONFIG_KPROBES=y CONFIG_HAVE_KPROBES=y CONFIG_KPROB ...