深度学习基础课:使用交叉熵损失函数和Softmax激活函数(下)
大家好~本课程为“深度学习基础班”的线上课程,带领同学从0开始学习全连接和卷积神经网络,进行数学推导,并且实现可以运行的Demo程序
线上课程资料:
本节课录像回放
加QQ群,获得ppt等资料,与群主交流讨论:106047770
本系列文章为线上课程的复盘,每上完一节课就会同步发布对应的文章
本课程系列文章可进入索引查看:
深度学习基础课系列文章索引
主问题:如何加快多分类的训练速度?
- “识别手写数字“属于单分类还是多分类?
答:多分类 - “识别手写数字“是否能使用单分类中的交叉熵损失函数?
答:不能 - 为什么?
答:
\frac{dE}{dw_{kj}} &=\delta_k a_j \\
&= \frac{dE}{dy_k}\frac{df(net_k)}{dnet_k} a_j \\
\end{aligned}
\]
因为目前的交叉熵损失函数是在单分类下推导的。
而在多分类下,由于原有的激活函数不再适合,需要更换新的激活函数,导致上面公式中的\(\frac{df(net_k)}{dnet_k}\)发生了变化,导致损失函数E也需要改变,
所以需要新的损失函数
- 输出层原来的sigmoid激活函数是否适用于多分类的情况?
答:不适用 - 输出层需要新的激活函数
- 如何设计新的激活函数?
- 我们现在用a表示激活函数的输出值
- 激活函数要满足什么条件?
答: \(
a_k \in [0.0, 1.0] 以及 \sum_{k=1}^n a_k= 1
\) - 你能设计一个满足该条件的激活函数吗?
答:\(a_k = \frac{t_k}{\sum_{i} t_i} 且t_i(包括t_k) >0.0\)
- 我们使用softmax激活函数,它的公式为:
答: \(
a_k = \frac{e^{net_k}}{\sum_{i=1}^n e^{net_i}}
\)
为什么\(t_k\)使用\(e^k\)这种函数呢?这可能是因为它大于0.0;并且由于是非线性的所以值的间隔拉的比较开,从而能适应更多的变化 - softmax是否满足条件?
答:满足 - 我们现在用y表示真实值(即标签)
- 如何计算loss?
答:\(
\overrightarrow{loss} = \overrightarrow{a_{输出层}} - \overrightarrow{y}
\) - 如何参考设计单分类误差项公式的思路来设计多分类误差项的公式,使其满足loss与误差项成正比?
答:\(
\overrightarrow{\delta_{输出层}} =\overrightarrow{loss} = \overrightarrow{a_{输出层}} - \overrightarrow{y}
\) - 我们需要将单分类的交叉熵损失函数修改一下,使其满足什么公式?
答:为了简单,我们暂时不考虑误差项向量,而只考虑单个神经元的误差项。所以应该满足下面的公式:
\(
E = ?从而
\sum_{i=1}^n \frac{dE}{da_i} \frac{da_i}{dnet_k}=\delta_k =a_k - y_k
\)
(注意:因为每个a的计算都有所有的net参加,所以要使用全导数公式进行累加) - 现在直接给出修改后的交叉熵损失函数的公式: \(E = - \sum_{j=1}^n y_j \ln a_j \\\)
- 请根据修改后的损失函数和softmax激活函数公式,推导误差项,看下是否为设计的公式: \(
\delta_k =\sum_{i=1}^n \frac{dE}{da_i} \frac{da_i}{dnet_k}= ?(应该为a_k - y_k)
\)
答:
\(\because\)
\frac{dE}{da_i} &= \frac{d- \sum_{j=1}^n y_j \ln a_j }{da_i}
&= - \frac{y_i}{a_i}
\end{aligned}
\]
\(\therefore\)
\delta_k &= \sum_{i=1}^n \frac{dE}{da_i} \frac{da_i}{dnet_k} \\
&= - \sum_{i=1}^n \frac{y_i}{a_i} \frac{da_i}{dnet_k} \\
\end{aligned}
\]
因为只能有一个真实值为1,所以假设\(y_j=1\),其它\(y_i=0\),则
\delta_k &= - \frac{1}{a_j} \frac{da_j}{dnet_k} \\
\end{aligned}
\]
现在需要推导\(\frac{da_j}{dnet_k}\),推导过程如下:
因为\(a_j\)可以看作是\(net_j\)的复合函数:
a_j =\frac{e^{net_j}}{\sum_{m=1}^n e^{net_m}} = f(e^{net_j}, \sum_m e^{net_m})
\\
\]
所以:
\]
现在分两种情况:
- 若 k = j
\frac{da_j}{dnet_j}
=
\frac{da_j}{de^{net_j}} \frac{de^{net_j}}{dnet_j} + \frac{da_j}{d\sum_m e^{net_m}} \frac{d\sum_m e^{net_m}}{dnet_j} \\
\]
\(\because\)
\begin{aligned}
\frac{da_j}{de^{net_j}} &= \frac{1}{\sum_j e^{net_j}} \\
\frac{de^{net_j}}{dnet_j} &= e^{net_j}\\
\frac{da_j}{d\sum_m e^{net_m}} &= - \frac{e^{net_j}}{(\sum_m e^{net_m})^2} \\
\frac{d\sum_m e^{net_m}}{dnet_k} &= \frac{d\sum_m e^{net_m}}{de^{net_k}} \frac{de^{net_k}}{dnet_k}
= e^{net_k} \\
\end{aligned}
\]
\(\therefore\)
\frac{da_j}{dnet_k} =
\frac{da_j}{dnet_j}
= a_j(1-a_j)
\]
- 若 k \(\neq\) j
\]
\(\because\)
\begin{aligned}
\frac{da_j}{de^{net_k}} &= 0 \\
\frac{da_j}{d\sum_m e^{net_m}} &= - \frac{e^{net_j}}{(\sum_m e^{net_m})^2} \\
\frac{d\sum_m e^{net_m}}{dnet_k} &= e^{net_k} \\
\end{aligned}
\]
\(\therefore\)
\frac{da_j}{dnet_k}
= -a_j a_k
\]
经过上面的推导后,写成向量的形式就是:
\overrightarrow{\delta_{输出层}} = \begin{bmatrix}
- \frac{1}{a_j} \cdot (-a_j a_1) \\
\vdots \\
- \frac{1}{a_j} \cdot (a_j(1-a_j)) \\
\vdots \\
- \frac{1}{a_j} \cdot (-a_j a_n) \\
\end{bmatrix}
= \begin{bmatrix}
a_1 \\
\vdots \\
a_j - 1 \\
\vdots \\
a_n \\
\end{bmatrix}
= \overrightarrow{a_{输出层}} - \overrightarrow{y} \\
\]
结学
- 如何加快多分类的训练速度?
- 根据交叉熵损失函数和softmax,推导误差项的过程是什么?
任务:识别手写数字使用交叉熵损失函数和softmax激活函数
- 请在“识别手写数字Demo”中使用交叉熵损失函数和softmax激活函数,并且加入“通过打印loss来判断收敛”
答:待实现的代码为:NewCross_softmax,实现后的代码为:NewCross_softmax_answer - 请每个同学运行代码
- 刚开始训练时,有什么警告?
答:如下图所示:有“输出层梯度过大”的警告
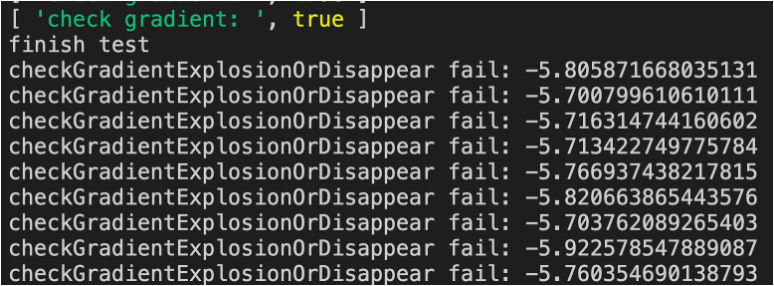
- 注释掉警告代码后,看下loss的训练速度与之前的代码相比是否明显加快?
答:没有
- 刚开始训练时,有什么警告?
任务:改进代码
- 找到发生警告的原因?
答: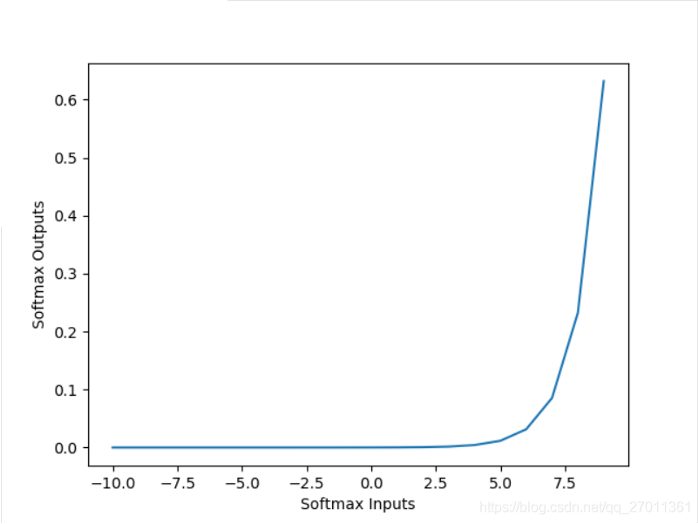
因为输出层加权和没有做缩小处理,所以加权和比较大(范围为[10.0,15.0]左右)。
通过上图(softmax的图像)可知,该范围内的梯度很大,所以报“梯度爆炸”的警告 - 如何改进代码?
答:将输出层的学习率变小为0.1 - 将输出层的学习率分别变小为1.0、0.1,运行代码,看是否解决了警告,并提升了训练速度?
答:变小为0.1后运行代码的结果如下图所示:
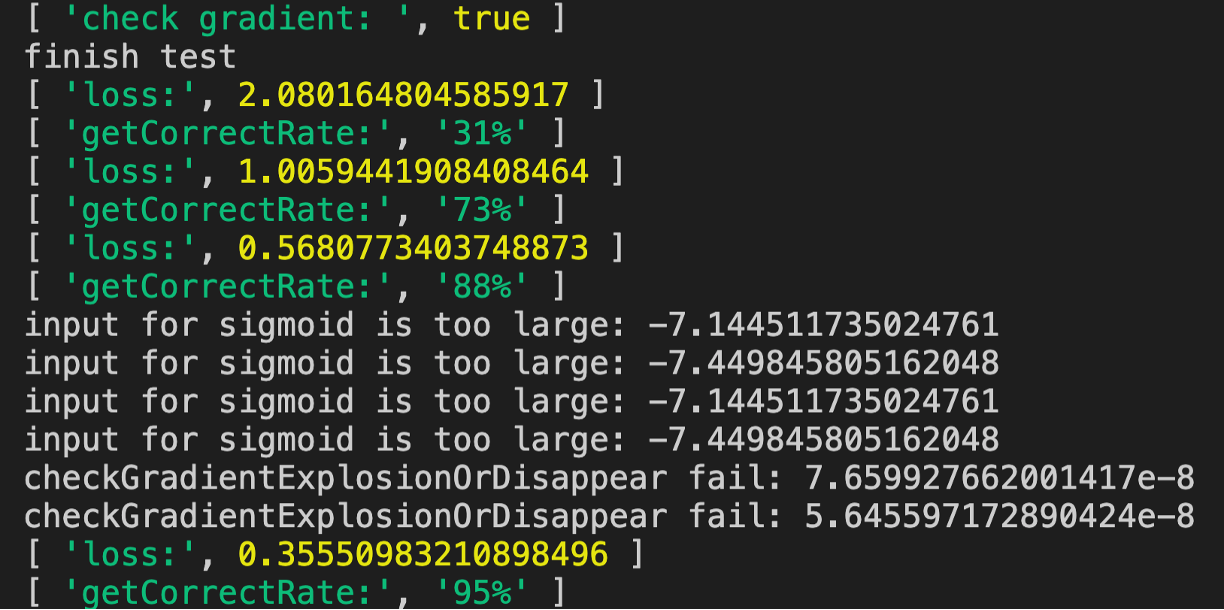
我们看到只需要四轮训练既达到95%的正确率
那么为什么在正确率到88%后会开始报输出层的一些梯度值过小的警告呢?这是因为此时loss小,所以梯度也小了
总结
- 请总结本节课的内容?
- 请回答所有主问题?
参考资料
谢谢你~
深度学习基础课:使用交叉熵损失函数和Softmax激活函数(下)的更多相关文章
- 深度学习基础5:交叉熵损失函数、MSE、CTC损失适用于字识别语音等序列问题、Balanced L1 Loss适用于目标检测
深度学习基础5:交叉熵损失函数.MSE.CTC损失适用于字识别语音等序列问题.Balanced L1 Loss适用于目标检测 1.交叉熵损失函数 在物理学中,"熵"被用来表示热力学 ...
- 【转载】深度学习中softmax交叉熵损失函数的理解
深度学习中softmax交叉熵损失函数的理解 2018-08-11 23:49:43 lilong117194 阅读数 5198更多 分类专栏: Deep learning 版权声明:本文为博主原 ...
- 深度学习原理与框架-神经网络结构与原理 1.得分函数 2.SVM损失函数 3.正则化惩罚项 4.softmax交叉熵损失函数 5. 最优化问题(前向传播) 6.batch_size(批量更新权重参数) 7.反向传播
神经网络由各个部分组成 1.得分函数:在进行输出时,对于每一个类别都会输入一个得分值,使用这些得分值可以用来构造出每一个类别的概率值,也可以使用softmax构造类别的概率值,从而构造出loss值, ...
- [ch03-02] 交叉熵损失函数
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI, 点击star加星不要吝啬,星越多笔者越努力. 3.2 交叉熵损失函数 交叉熵(Cross Entrop ...
- 关于交叉熵损失函数Cross Entropy Loss
1.说在前面 最近在学习object detection的论文,又遇到交叉熵.高斯混合模型等之类的知识,发现自己没有搞明白这些概念,也从来没有认真总结归纳过,所以觉得自己应该沉下心,对以前的知识做一个 ...
- softmax交叉熵损失函数求导
来源:https://www.jianshu.com/p/c02a1fbffad6 简单易懂的softmax交叉熵损失函数求导 来写一个softmax求导的推导过程,不仅可以给自己理清思路,还可以造福 ...
- 机器学习之路:tensorflow 深度学习中 分类问题的损失函数 交叉熵
经典的损失函数----交叉熵 1 交叉熵: 分类问题中使用比较广泛的一种损失函数, 它刻画两个概率分布之间的距离 给定两个概率分布p和q, 交叉熵为: H(p, q) = -∑ p(x) log q( ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:交叉熵损失函数
import tensorflow as tf # 1. sparse_softmax_cross_entropy_with_logits样例. # 假设词汇表的大小为3, 语料包含两个单词" ...
- BCE和CE交叉熵损失函数的区别
首先需要说明的是PyTorch里面的BCELoss和CrossEntropyLoss都是交叉熵,数学本质上是没有区别的,区别在于应用中的细节. BCE适用于0/1二分类,计算公式就是 " - ...
- 【深度学习】深入理解ReLU(Rectifie Linear Units)激活函数
论文参考:Deep Sparse Rectifier Neural Networks (很有趣的一篇paper) Part 0:传统激活函数.脑神经元激活频率研究.稀疏激活性 0.1 一般激活函数有 ...
随机推荐
- 听懂未来:AI语音识别技术的进步与实战
本文全面探索了语音识别技术,从其历史起源.关键技术发展到广泛的实际应用案例,揭示了这一领域的快速进步和深远影响.文章深入分析了语音识别在日常生活及各行业中的变革作用,展望了其未来发展趋势. 关注Tec ...
- 整合SpringBoot + Dubbo + Nacos 出现 Unable to make protected final java.lang.Class java.lang.ClassLoader.defineClass
版本 SpringBoot:2.7.3 Dubbo:3.0.4 Nacos:2.0.3 异常信息如下 Unable to make protected final java.lang.Class ja ...
- Kernel Memory 入门系列: RAG 简介
Kernel Memory 入门系列: RAG 简介 开一个新坑,Semantic Kernel系列会在 Release 1.0 之后陆续更新. 当我们有了一定的产品资料或者知识内容之后,自然想着提供 ...
- keycloak~对接login-status-iframe页面判断用户状态变更
上次我们说了,keycloak的login-status-iframe页面的作用,并解决了跨域情况下,iframe与主页面数据传递的方法,这一次,我们主要分析login-status-iframe.h ...
- 万界星空科技服装行业mes解决方案
服装行业MES特色 企业透过全球供应链网络掌握实时的订单进度信息来实现电子商务排除生产现场自动化"孤岛",建立起业务计划层到控制层的桥梁,JIT库存管理与看板管理.精益生产与敏 ...
- shopify主题模板速度优化
前两天一位新客户说他的shopify店铺加载速度很慢,首页完全加载需要 5~6 秒甚至更高,问ytkah有没办法帮忙优化一下.shopify网站速度优化要看具体用了什么模板,有什么功能,哪些可以改哪些 ...
- Java注解,看完就会用
一.什么是注解 定义:注解(Annotation),也叫元数据.一种代码级别的说明. 它是JDK1.5及以后版本引入的一个特性,与类.接口.枚举是在同一个层次. 它可以声明在包.类.字段.方法.局部变 ...
- Windows Server 2016配置NTP客户端
前提:开通Windows Time 服务 输入services.msc进入服务管理界面,找到Windows Time 开启服务. 情况1:可以直接设置NTP时钟 控制面板--时钟和区域--设置时间和日 ...
- DVWA File Inclusion(文件包含)全等级
File Inclusion(文件包含) 目录: File Inclusion(文件包含) 前言 PHP伪协议 1.Low get webshell 本地文件包含 远程文件包含 2.Medium 3. ...
- DNS解析中CNAME和MX记录冲突
转载:DNS中CNAME和MX记录的冲突 在DNS解析中,CNAME记录与其他记录往往是互斥的.最常见的是CNAME记录和MX记录的互斥.例如我们在http://example.com部署官网,通过C ...