吴裕雄--天生自然 pythonTensorFlow自然语言处理:交叉熵损失函数
import tensorflow as tf # 1. sparse_softmax_cross_entropy_with_logits样例。
# 假设词汇表的大小为3, 语料包含两个单词"2 0"
word_labels = tf.constant([2, 0]) # 假设模型对两个单词预测时,产生的logit分别是[2.0, -1.0, 3.0]和[1.0, 0.0, -0.5]
predict_logits = tf.constant([[2.0, -1.0, 3.0], [1.0, 0.0, -0.5]]) # 使用sparse_softmax_cross_entropy_with_logits计算交叉熵。
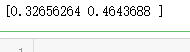
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=word_labels, logits=predict_logits) # 运行程序,计算loss的结果是[0.32656264, 0.46436879], 这对应两个预测的
# perplexity损失。
sess = tf.Session()
print(sess.run(loss))
# 2. softmax_cross_entropy_with_logits样例。
# softmax_cross_entropy_with_logits与上面的函数相似,但是需要将预测目标以
# 概率分布的形式给出。
word_prob_distribution = tf.constant([[0.0, 0.0, 1.0], [1.0, 0.0, 0.0]])
loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_distribution, logits=predict_logits)
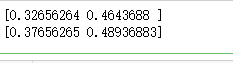
# 运行结果与上面相同:[ 0.32656264, 0.46436879]
print(sess.run(loss)) # label smoothing:将正确数据的概率设为一个比1.0略小的值,将错误数据的概率
# 设为比0.0略大的值,这样可以避免模型与数据过拟合,在某些时候可以提高训练效果。
word_prob_smooth = tf.constant([[0.01, 0.01, 0.98], [0.98, 0.01, 0.01]])
loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_smooth, logits=predict_logits)
# 运行结果:[ 0.37656265, 0.48936883]
print(sess.run(loss)) sess.close()
吴裕雄--天生自然 pythonTensorFlow自然语言处理:交叉熵损失函数的更多相关文章
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:PTB 语言模型
import numpy as np import tensorflow as tf # 1.设置参数. TRAIN_DATA = "F:\TensorFlowGoogle\\201806- ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Attention模型--测试
import sys import codecs import tensorflow as tf # 1.参数设置. # 读取checkpoint的路径.9000表示是训练程序在第9000步保存的ch ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Attention模型--训练
import tensorflow as tf # 1.参数设置. # 假设输入数据已经转换成了单词编号的格式. SRC_TRAIN_DATA = "F:\\TensorFlowGoogle ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Seq2Seq模型--测试
import sys import codecs import tensorflow as tf # 1.参数设置. # 读取checkpoint的路径.9000表示是训练程序在第9000步保存的ch ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Seq2Seq模型--训练
import tensorflow as tf # 1.参数设置. # 假设输入数据已经用9.2.1小节中的方法转换成了单词编号的格式. SRC_TRAIN_DATA = "F:\\Tens ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:文本数据预处理--生成训练文件
import sys import codecs # 1. 参数设置 MODE = "PTB_TRAIN" # 将MODE设置为"PTB_TRAIN", &qu ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:数据集高层操作
import tempfile import tensorflow as tf # 1. 列举输入文件. # 输入数据生成的训练和测试数据. train_files = tf.train.match_ ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:输入数据处理框架
import tensorflow as tf # 1. 创建文件列表,通过文件列表创建输入文件队列 files = tf.train.match_filenames_once("F:\\o ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:循环神经网络预测正弦函数
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt # 定义RNN的参数. HIDDEN_SIZE = ...
随机推荐
- 用Python复制文件的9个方法(转)
转自:https://zhuanlan.zhihu.com/p/35725217 用Python复制文件的9个方法 Python 中有许多“开盖即食”的模块(比如 os,subprocess 和 sh ...
- 11 ~ express ~ 解决 cookie 中文报错的问题
使用cookies包需要注意:1,cookie中是不能有中文的,一旦有中文,就会报错2,cookie是通过 中间件的形式直接挂载到 req对象上的,那么cookies有的方法,req.cookies就 ...
- TP中统计指定字段的总数
如统计已激活设备数量和未激活设备数量 $condition = [ ['member_id', '=', $member_id] ]; $field = [ 'COUNT(IF(active_memb ...
- Java IO 乱码
InputStreamReader isr = new InputStreamReader(new FileInputStream("./test/垃圾短信训练集80W条.txt" ...
- maven项目从本地向本地仓库导入jar包
方法一(推荐): <dependency> <groupId>guagua-commons</groupId> <artifactId>guagua-c ...
- 可塑性|Exosomes
五流解释 肿瘤发源于不同组织如果不从各种组织出发,则不能有正确的解决方法. Hallmarks of cancer LncRNAs操作流 Exosomes ,它的基本故事是平衡流,但是具体内涵是操作流 ...
- javaweb02
第一个web服务器程序:开发部署到Tomcat服务器下运行 1).在eclipse新建一个Javaproject2).在java项目下创建web开发的目录结构 -Webcontent -WEB-INF ...
- JaveSE--getResource
System.out.println(ConfigUtils.class.getProtectionDomain().getCodeSource().getLocation().getPath()); ...
- MySQL--InnoDB 关键特性
插入缓冲 Insert Buffer 对于非聚集索引的插入或更新操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,若在,则直接插入:若不在,则先放入到一个 Insert ...
- 编写shell脚本,使用 nohup 让springboot 项目在后台持续运行
1.将springboot项目打成jar放在linux的某个目录下. 2.新建一个nohup.log文件. 3.使用vi命令新建一个start.sh文件并写下以下内容: #!/bin/sh nohup ...