【爬虫案例】用Python爬取知乎热榜数据!
一、爬取目标
您好,我是@马哥python说,一名10年程序猿。
本次爬取的目标是:知乎热榜
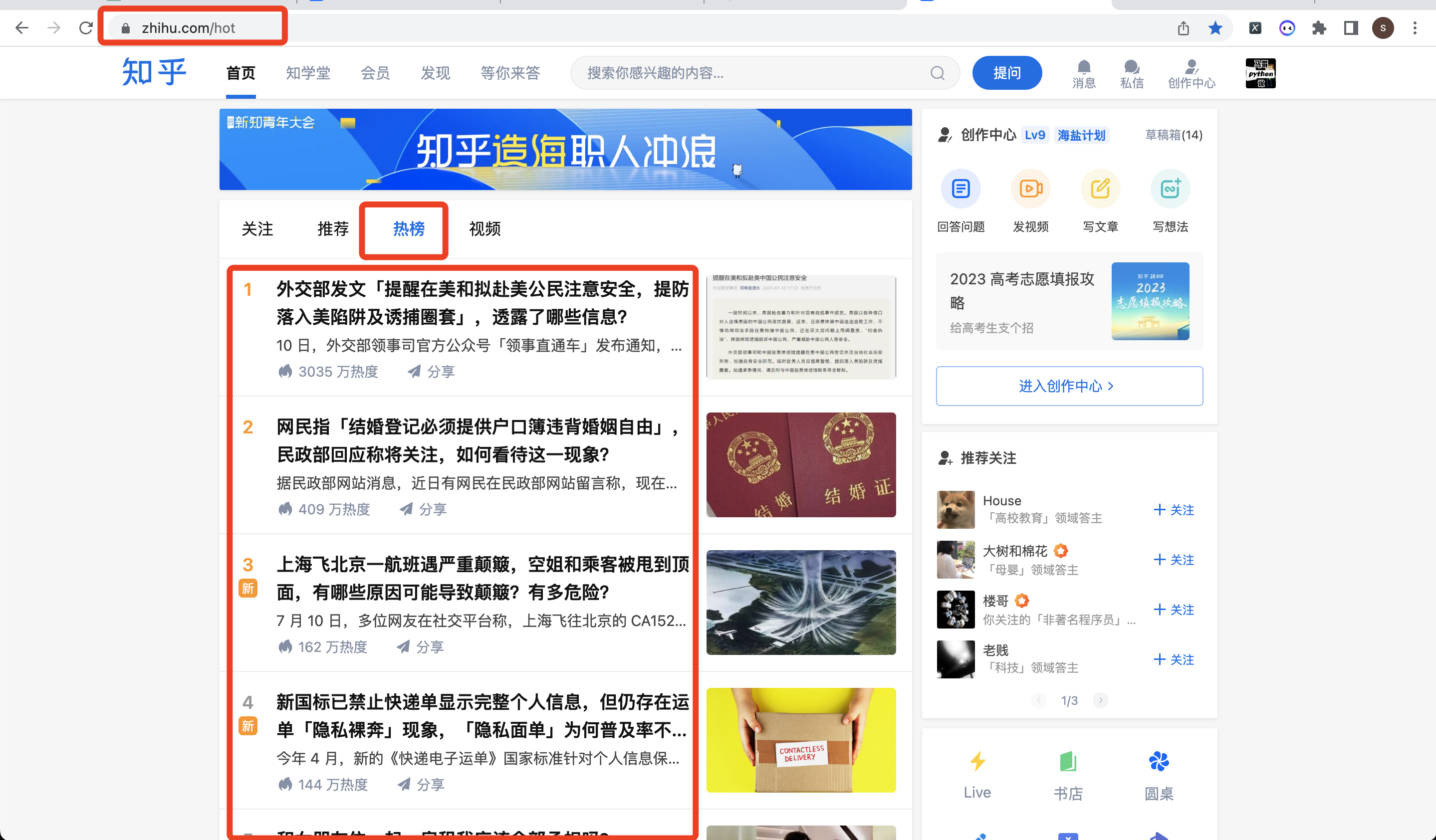
共爬取到6个字段,包含:
热榜排名, 热榜标题, 热榜链接, 热度值, 回答数, 热榜描述。
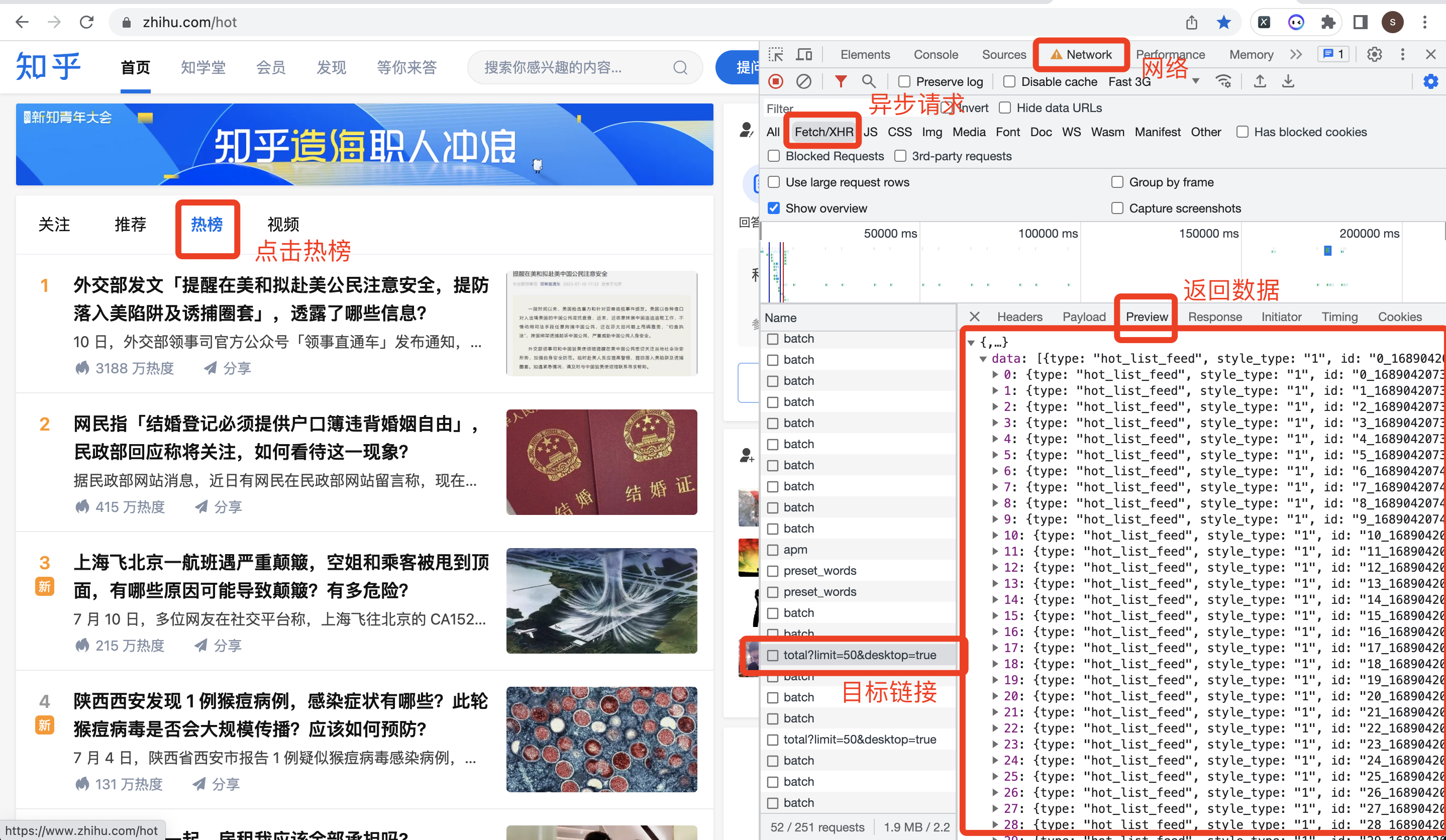
用CHrome浏览器,右键打开开发者模式,选择:网络->XHR这个选项,重新点击一下【热榜】按钮,或者切换到【视频】页再切换回【热榜】页。
操作过程,如下图所示:
下面,开始编码爬虫代码。
二、编写爬虫代码
首先,导入需要用到的库:
import requests
import pandas as pd
定义一个请求地址,即上图中的目标链接地址:
# 接口地址
url = 'https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total?limit=50&desktop=true'
定义一个请求头,从开发者模式中的Headers->Request Headers中复制下来:
# 构造请求头
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15',
'Referer': 'https://www.zhihu.com/hot',
'Connection': 'keep-alive',
'Cookie': '换成自己的cookie值',
'x-ab-pb': 'CgQnB/gMEgIAAA==',
'x-requested-with': 'fetch',
'x-zst-81': '3_2.0aR_sn77yn6O92wOB8hPZn490EXtucRFqwHNMUrL8YunpELY0w6SmDggMgBgPD4S1hCS974e1DrNPAQLYlUefii_qr6kxELt0M4PGDwN8gGcYAupMWufIoLVqr4gxrRPOI0cY7HL8qun9g93mFukyigcmebS_FwOYPRP0E4rZUrN9DDom3hnynAUMnAVPF_PhaueTF8Lme9gKSq3_BBOG1UVmggHYFJefYqeYfhO_rTgBSMSMpGYLwqcGYDVfXUSTVHefr_xmBq399qX0jCgKNcr_cCSmi9xYvhoLeXx18qCYEw3Of0NLwuc8TUOpS8tMdCcGuCo8kCp_pbLf6hgO_JVKXwFY2JOLG7VCSXxYqrSBICL_5GxmOg_z6XVxqBLfMvxqYDuf3DOf6GLGhDHCbRxO0qLpTDXfbvxCSAH0BhCmJ4NmRBY8rJwB6MS124SqKuo_ywS8ACtBfqwC8XC9QA3KxCepuuCYXhLyWgNCuwYs',
'x-zse-93': '101_3_3.0',
'x-api-version': '3.0.76',
'x-zse-96': '2.0_CkAT7RdDtmW9PikRDfWa4CZIMx50XeUMQ7r34wP2JRAtFiCKXsSmoxCzrKWi2nJ1'
}
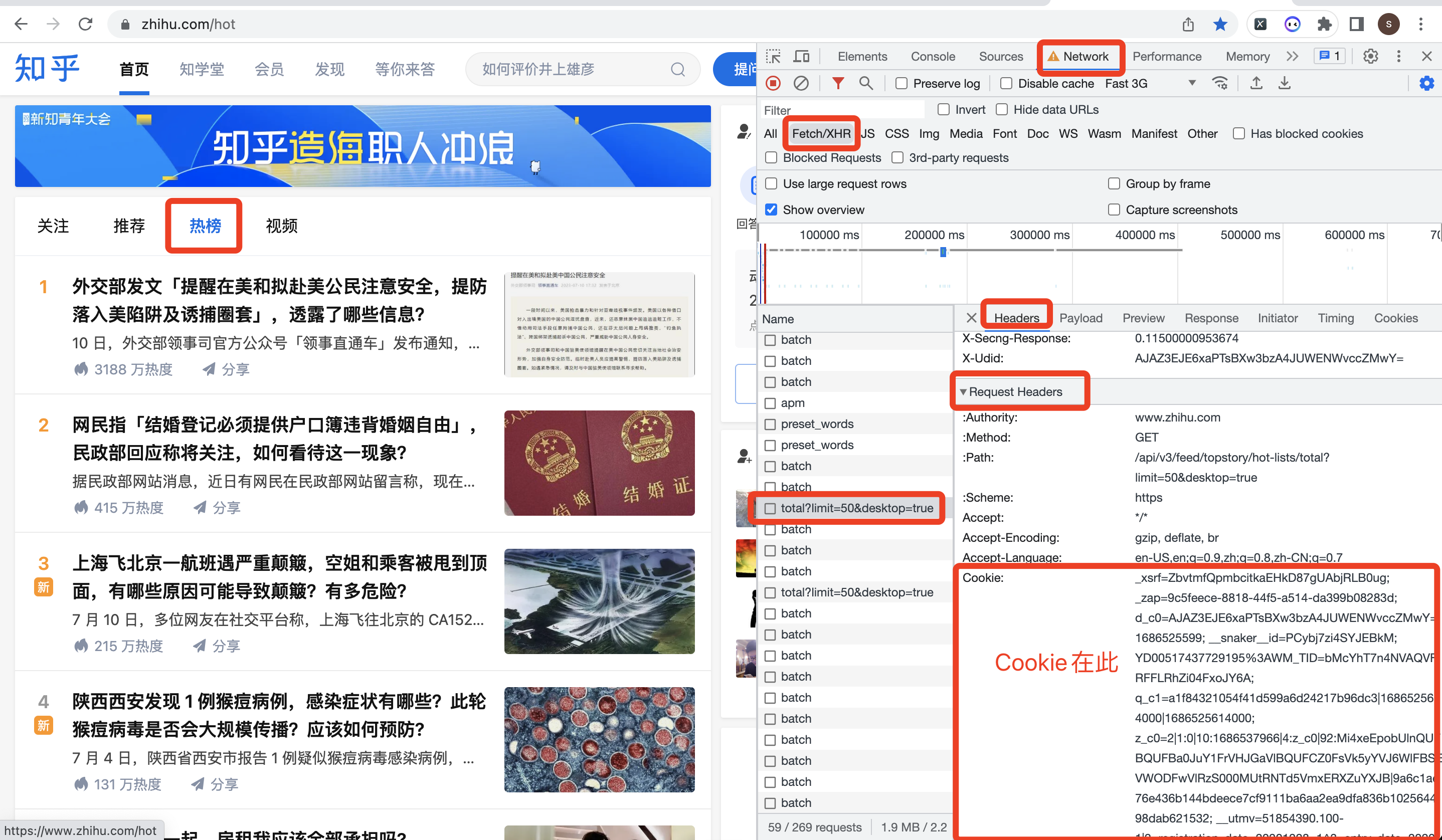
不知如何获取Cookie?参考下图:
向目标地址发送请求(带上请求头),并用json格式接收返回数据:
# 发送请求
r = requests.get(url, headers=headers)
# 用json接收请求数据
json_data = r.json()
定义一些空列表,用于存储数据:
order_list = [] # 热榜排名
title_list = [] # 热榜标题
desc_list = [] # 热榜描述
url_list = [] # 热榜链接
hot_value_list = [] # 热度值
answer_count_list = [] # 回答数
以“热榜标题”为例,解析数据:
for data in data_list:
# 热榜标题
title = data['target']['title_area']['text']
print(order, '热榜标题:', title)
title_list.append(title)
其他字段同理,不再赘述。
最后,把解析到的数据,存储到Dataframe中,并保存到csv文件里:
# 拼装爬取到的数据为DataFrame
df = pd.DataFrame(
{
'热榜排名': order_list,
'热榜标题': title_list,
'热榜链接': url_list,
'热度值': hot_value_list,
'回答数': answer_count_list,
'热榜描述': desc_list,
}
)
# 保存结果到csv文件
df.to_csv('知乎热榜.csv', index=False, encoding='utf_8_sig')
这里需要注意的是,to_csv要加上encoding='utf_8_sig'参数,防止保存到csv文件产生乱码数据。
查看爬取结果:
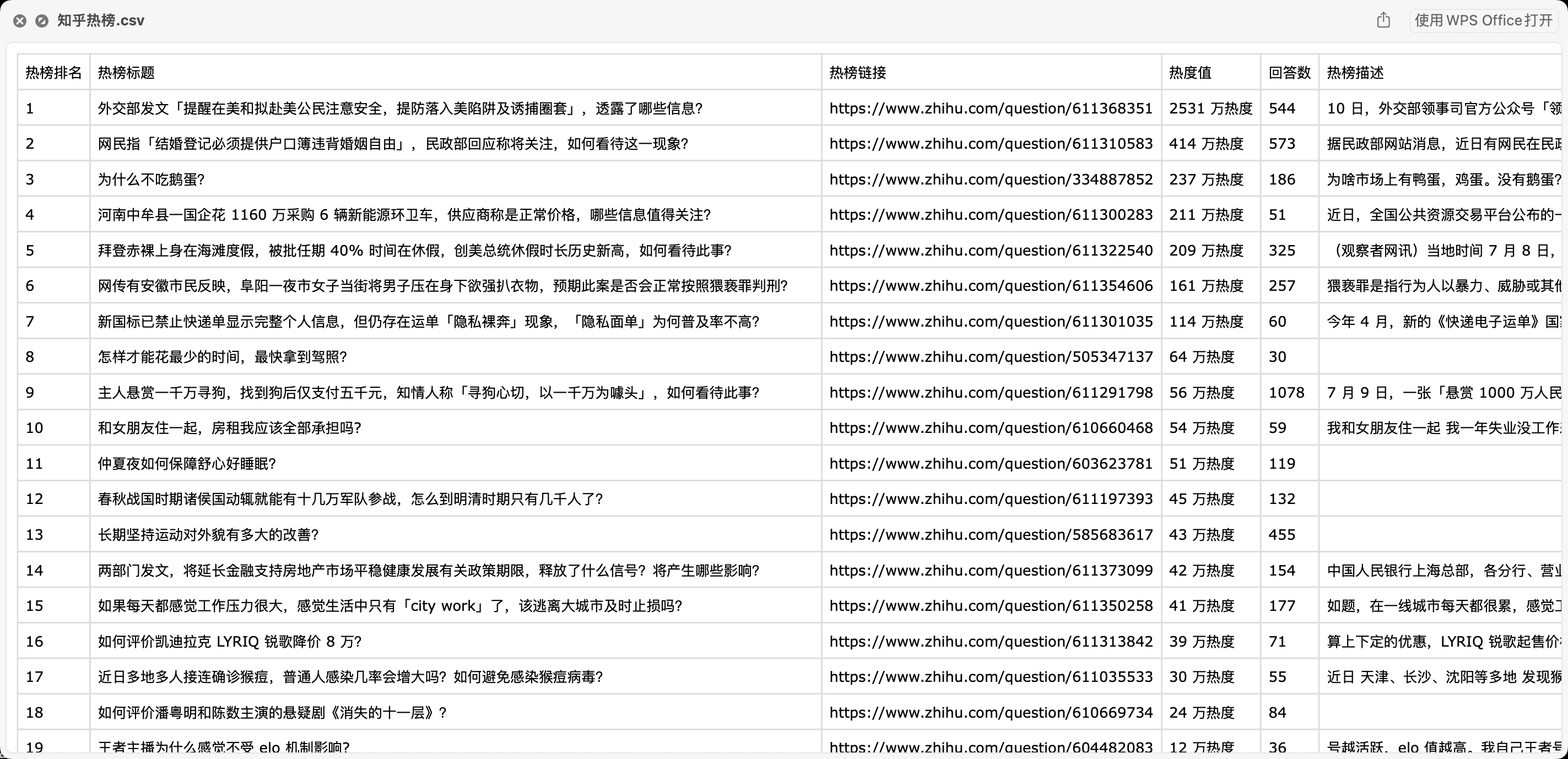
共50条数据,对应热榜TOP50排名。
每条数据含6个字段:热榜排名, 热榜标题, 热榜链接, 热度值, 回答数, 热榜描述。
三、同步讲解视频
3.1 代码演示视频
代码演示: 【Python爬虫演示】用Python爬知乎热榜数据
3.2 详细讲解视频
讲解教程:【Python爬虫教程】5分钟讲解用Python爬取知乎热榜
四、获取完整源码
get完整源码:【爬虫案例】用Python爬取知乎热榜数据!
我是@马哥python说 ,持续分享python源码干货中!
【爬虫案例】用Python爬取知乎热榜数据!的更多相关文章
- 爬取知乎热榜标题和连接 (python,requests,xpath)
用python爬取知乎的热榜,获取标题和链接. 环境和方法:ubantu16.04.python3.requests.xpath 1.用浏览器打开知乎,并登录 2.获取cookie和User—Agen ...
- python抓取知乎热榜
知乎热榜讨论话题,https://www.zhihu.com/hot,本文用python抓取下来分析 #!/usr/bin/python # -*- coding: UTF-8 -*- from ur ...
- 通过scrapy,从模拟登录开始爬取知乎的问答数据
这篇文章将讲解如何爬取知乎上面的问答数据. 首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录: 先说一下我的思路: 1.首先我们需要控制登录的入口,重写star ...
- python 爬取知乎图片
先上完整代码 import requests import time import datetime import os import json import uuid from pyquery im ...
- python网络爬虫第三弹(<爬取get请求的页面数据>)
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是通过代码模拟浏览器发送请求,其常被用到的子模块在 python3中的为urllib.request 和 urllib ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- python 爬取天猫美的评论数据
笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行.对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了.本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似 ...
- Python爬取网易云热歌榜所有音乐及其热评
获取特定歌曲热评: 首先,我们打开网易云网页版,击排行榜,然后点击左侧云音乐热歌榜,如图: 关于如何抓取指定的歌曲的热评,参考这篇文章,很详细,对小白很友好: 手把手教你用Python爬取网易云40万 ...
- python scrapy简单爬虫记录(实现简单爬取知乎)
之前写了个scrapy的学习记录,只是简单的介绍了下scrapy的一些内容,并没有实际的例子,现在开始记录例子 使用的环境是python2.7, scrapy1.2.0 首先创建项目 在要建立项目的目 ...
随机推荐
- MySQL(三)数据目录
目录 Mysql的主要目录结构 1 数据库文件的存放路径 /var/lib/mysql/ 2 相关命令目录 /usr/bin/mysql /usr/sbin/mysql 3 配置文件目录 /usr/s ...
- Dotnet初探: 尝试使用 dotnet6 的miniapi
引子 最近我们学校要求我们使用dotnet实现一个登录功能,由于我们学校的教程老旧(万年经典asp .net 4.x,慢的要死),我看有高性能又免费的Dotnet6不用,还又要退回几年前,于是决定另开 ...
- 浅谈php GC(垃圾回收)机制及其与CTF的一点缘分
0x00 侠客日常(一):CTF江湖试剑 众所周知,在php中,当对象被销毁时会自动调用__destruct()方法,同时也要知道,如果程序报错或者抛出异常,则就不会触发该魔术方法. 看题: < ...
- 2023-04-22:给你两个正整数数组 nums 和 target ,两个数组长度相等。 在一次操作中,你可以选择两个 不同 的下标 i 和 j , 其中 0 <= i, j < nums.leng
2023-04-22:给你两个正整数数组 nums 和 target ,两个数组长度相等. 在一次操作中,你可以选择两个 不同 的下标 i 和 j , 其中 0 <= i, j < num ...
- 2021-11-21:map[i][j] == 0,代表(i,j)是海洋,渡过的话代价是2, map[i][j] == 1,代表(i,j)是陆地,渡过的话代价是1, map[i][j] == 2,代表
2021-11-21:map[i][j] == 0,代表(i,j)是海洋,渡过的话代价是2, map[i][j] == 1,代表(i,j)是陆地,渡过的话代价是1, map[i][j] == 2,代表 ...
- 2021-11-13:至少有 K 个重复字符的最长子串。给你一个字符串 s 和一个整数 k ,请你找出 s 中的最长子串, 要求该子串中的每一字符出现次数都不少于 k 。返回这一子串的长度。提示:1
2021-11-13:至少有 K 个重复字符的最长子串.给你一个字符串 s 和一个整数 k ,请你找出 s 中的最长子串, 要求该子串中的每一字符出现次数都不少于 k .返回这一子串的长度.提示:1 ...
- Luogu1772 [ZJOI2006] 物流运输
传送门 简化题意 给你 \(m\) 个码头,码头之间有双向边连接,\(n\) 天,其中一些码头在某些天会不可用,这 \(n\) 天都要有一条从 \(1\) 到 \(m\) 的路,每一次更换道路会需要 ...
- linux中使用jenkins自动部署前端工程
1.去年在自己的服务器上安装了jenkins,说用来自己研究一下jenkins自动化部署前端项目,jenkins安装好了,可是一直没管,最近终于研究了一下使用jenkins自动化部署,以此记录下来. ...
- 【Java】按钮数组波纹效果
简介 最近Java学到了布局管理器,看到GridLayout就很有意思,老师说可以做Excel表格什么的,心中突发奇想,于是就想做一个波纹状按钮效果(事后一想可能是我键盘光效的影响-.-),网上一搜, ...
- c#优雅高效的读取字节数组——不安全代码(1)
在开发上位机的经历中,会有很多需要和下位机交互通信的场景,大多数都会定义一个和硬件的通信协议,最终在上位机代码中的形式其实就是符合通信协议的字节数组. 目录 场景 如何解析字节数组到类或结构体中 建立 ...