Python爬虫(1-4)-基本概念、六个读取方法、下载(源代码、图片、视频 )、user-agent反爬
Python爬虫
一、爬虫相关概念介绍
1.什么是互联网爬虫
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据
解释1:通过一个程序,根据URL进行爬取网页,获取有用信息
解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息
2.爬虫核心
- 爬取网页:爬取整个网页,包含了网页中所有的内容
- 解析数据:将网页中你得到的数据进行解析,也就是找到你所需要的数据
- 难点:爬虫和反爬虫之间的博弈。即“抓取数据”和”拒绝给你数据”之间的博弈
3.爬虫分类
- 通用爬虫
- 聚焦爬虫
根据需求,实现爬虫程序,抓取需要的数据
设计思路
1.确定要爬取的url
如何获取Url
2.模拟浏览器通过http协议访问url,获取服务器返回的html代码
如何访问
3.解析html字符串(根据一定规则提取需要的数据)
如何解析
4.urllib库使用
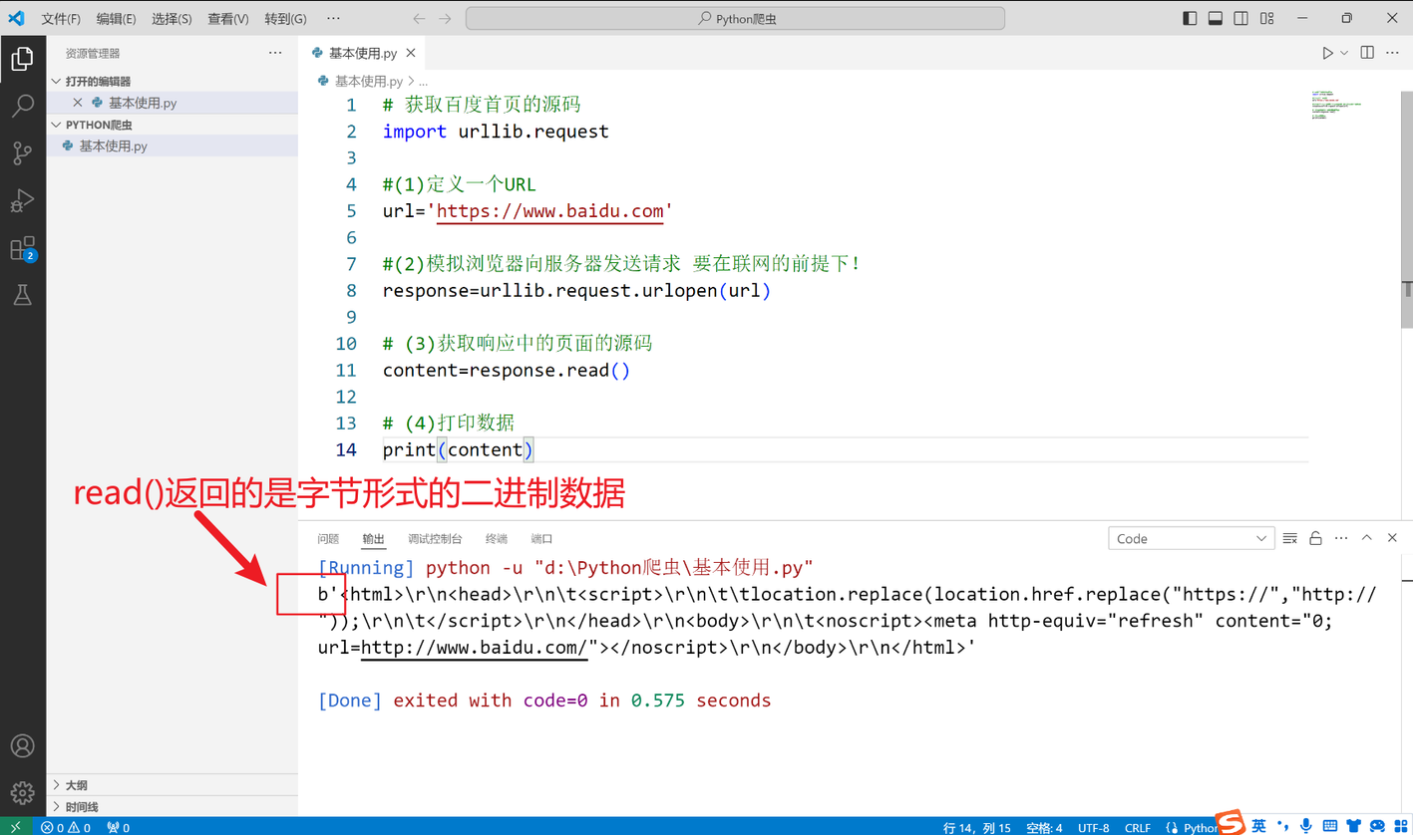
二、一个类型and六个方法
HTTPResponse类型
表示从服务器接收到的 HTTP 响应的对象类型,通常在处理网络请求时使用。它包含了服务器返回的各种信息,如状态码、响应头和响应体
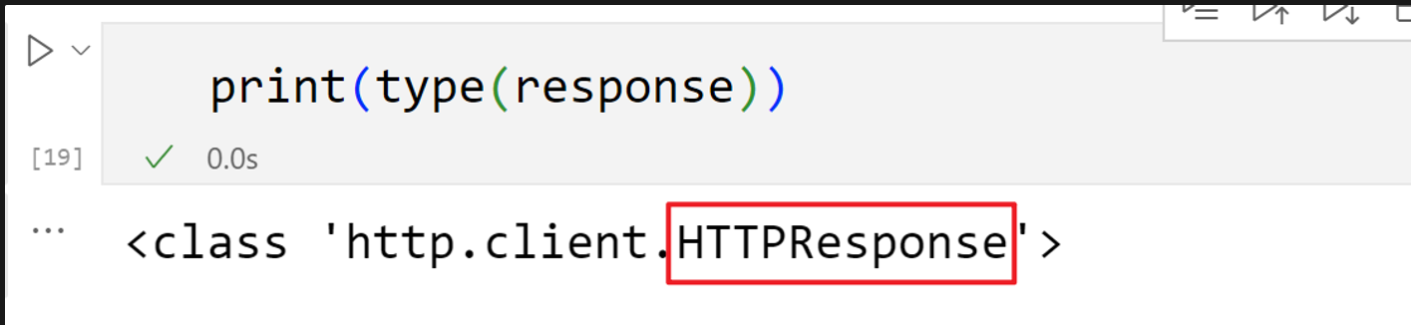
read()readline()只读取一行readlines()读取多行getcode()获取状态码geturl()getheaders()获取状态信息
三、下载
下载网页
#下载网页
url_page='http://www.baidu.com'
urllib.request.urlretrieve(url_page,'baidu.html')
下载图片
通过“复制图像链接”获取图片的存取路径,注意urlretrieve()函数里要对应好文件格式
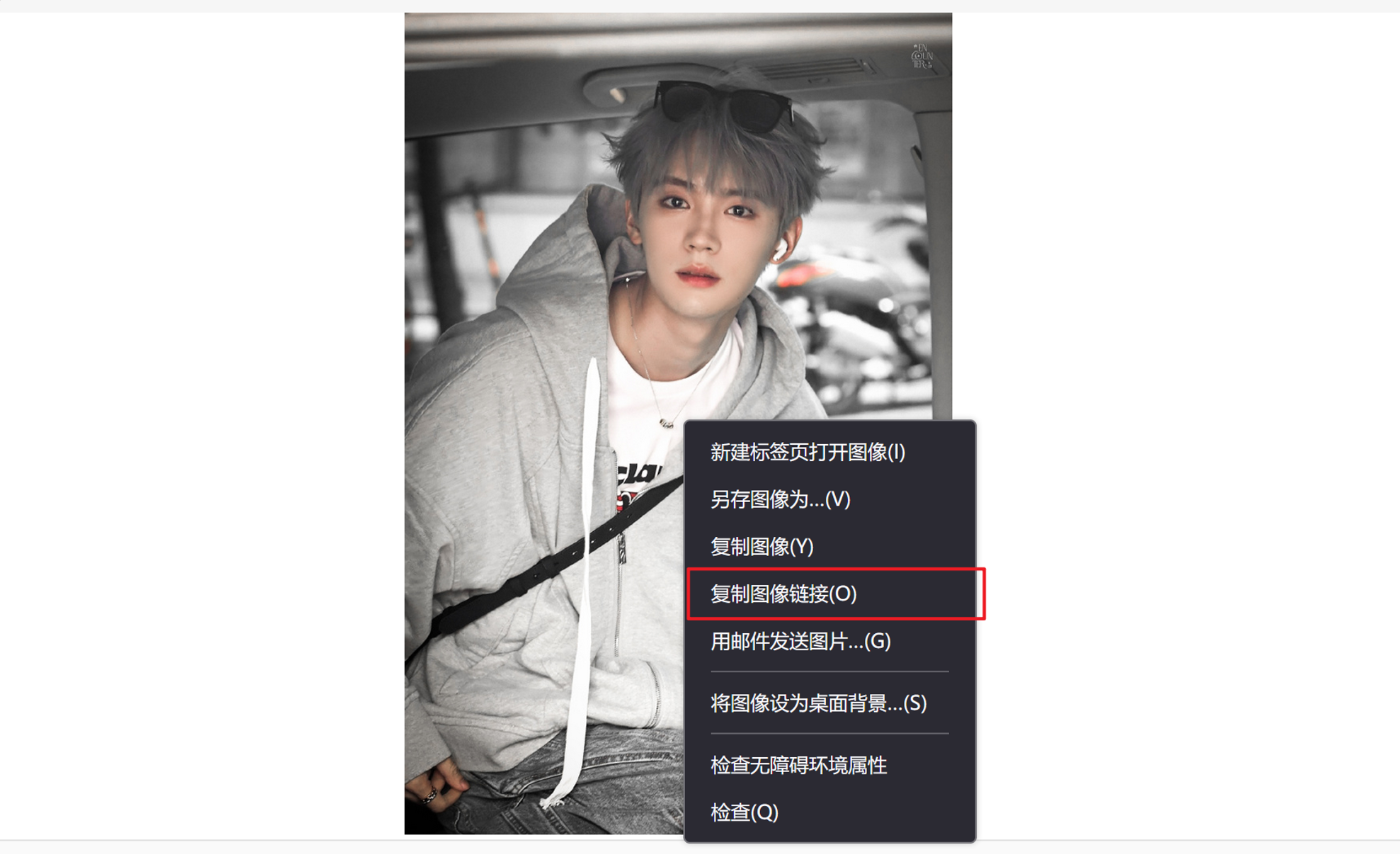
#下载图片
url_img='https://ww1.sinaimg.cn/mw690/007SWX7Ugy1hr6kqd0netj32wi4crqve.jpg'
urllib.request.urlretrieve(url_img,'zhouyiran.jpg')
下载视频
鼠标右击选择“检查”
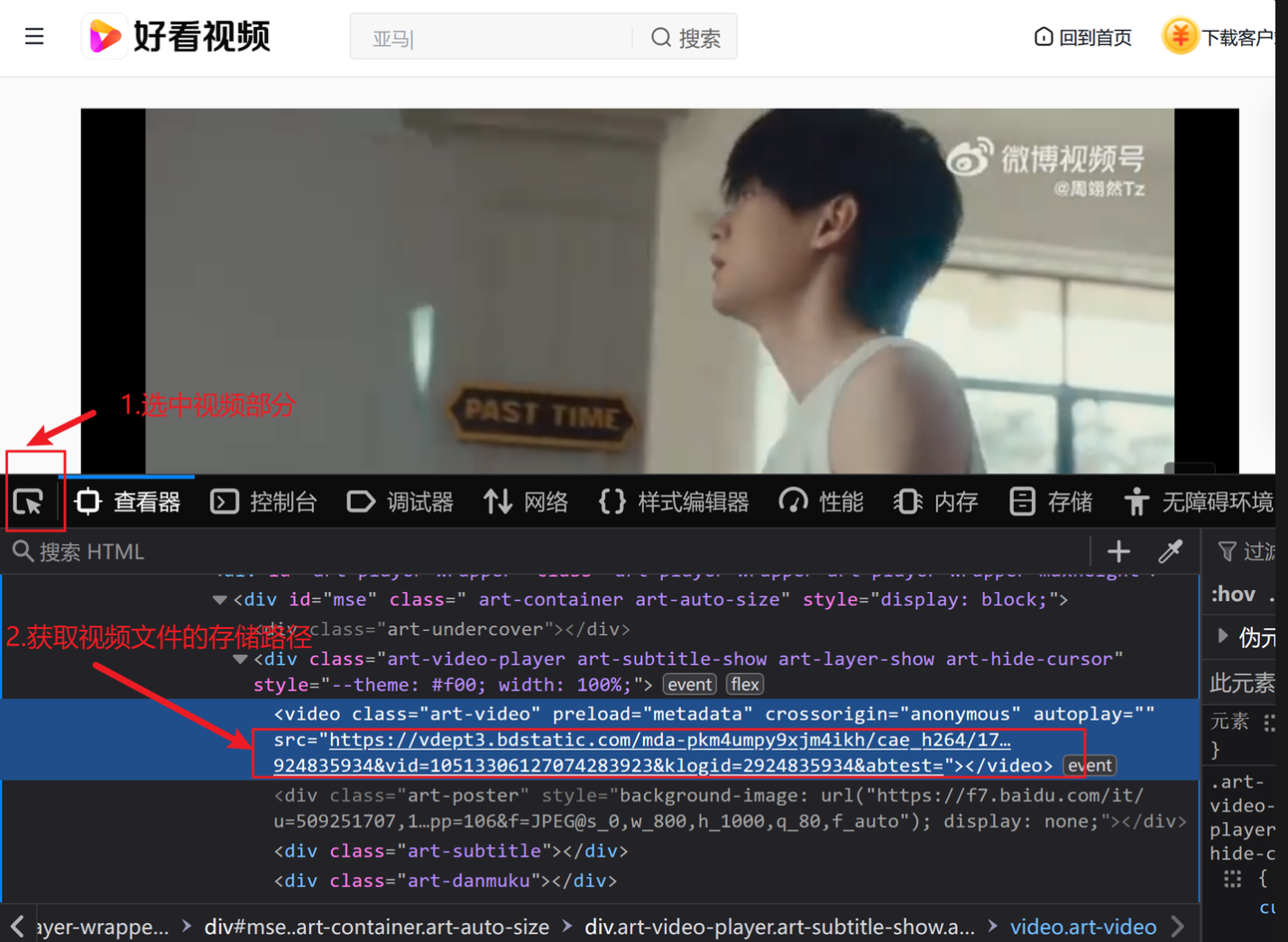
# 下载视频
url_video='https://vdept3.bdstatic.com/mda-pi79hyfq8jscww7u/360p/h264/1694155424021989258/mda-pi79hyfq8jscww7u.mp4?v_from_s=hkapp-haokan-hbf&auth_key=1720607496-0-0-d017b040f470523698685d8261770983&bcevod_channel=searchbox_feed&pd=1&cr=0&cd=0&pt=3&logid=1896481070&vid=10142877359436078513&klogid=1896481070&abtest=101830_2-102148_1-17451_2-3000225_3'
urllib.request.urlretrieve(url_video,'zhou.mp4')
四、请求对象的定制(user-agent反爬)
HTTP:HTTP以明文形式传输数据,数据在传输过程中没有加密,容易被中间人截获和篡改。
HTTPS:HTTPS使用SSL/TLS协议对数据进行加密,确保数据在传输过程中是安全的,即使被截获也无法轻易解密
user-agent:Http协议中的一部分,属于头域的组成部分,User Agent也简称UA。它是一个特殊字符串头,是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。通过这个标识,用户所访问的网站可以显示不同的排版从而为用户提供更好的体验或者进行信息统计;例如用手机访问谷歌和电脑访问是不一样的,这些是谷歌根据访问者的UA来判断的。UA可以进行伪装。
URL的组成

首先找到百度首页的user-agent
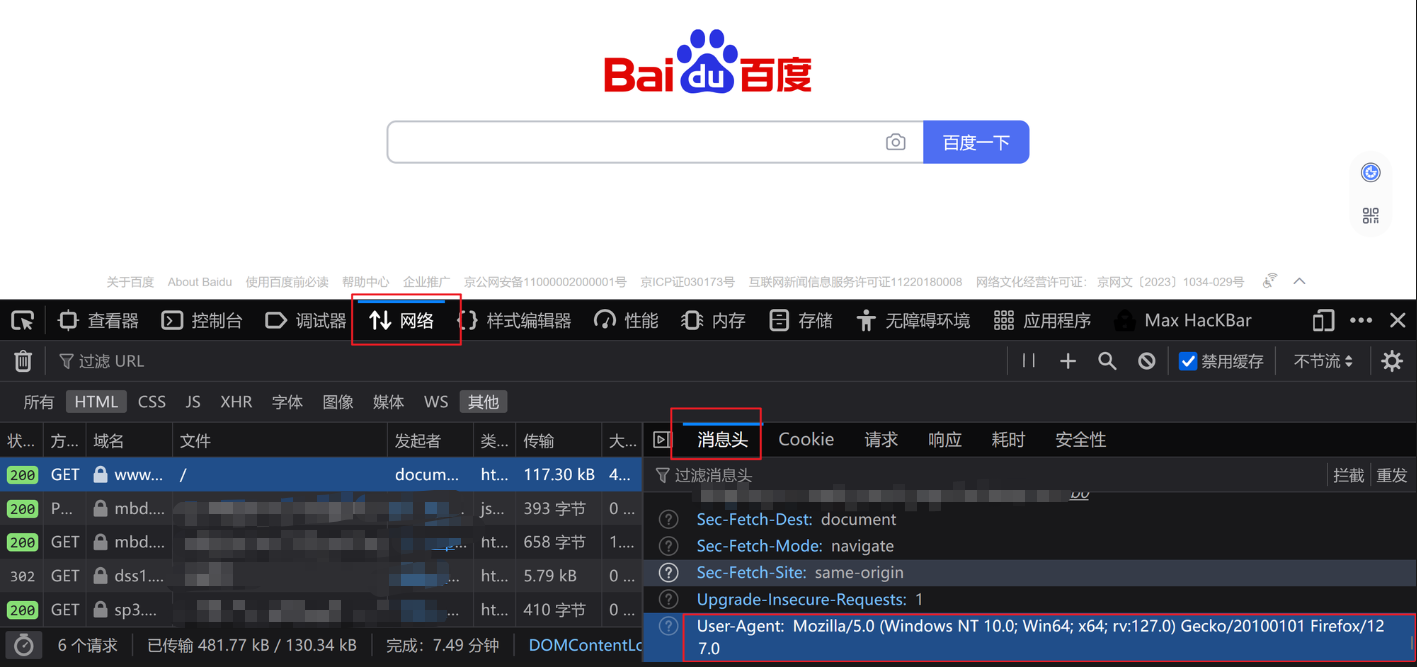
然后用以下代码进行反爬
import urllib.request
url='https://www.baidu.com'
# 构造字典
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0'
}
# 因为参数位置不对应,所以要写明参数名,再写参数值
request=urllib.request.Request(url=url,headers=headers)
# 进行包装后再读取
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
print(content)
Python爬虫(1-4)-基本概念、六个读取方法、下载(源代码、图片、视频 )、user-agent反爬的更多相关文章
- Python爬虫突破封禁的6种常见方法
转 Python爬虫突破封禁的6种常见方法 2016年08月17日 22:36:59 阅读数:37936 在互联网上进行自动数据采集(抓取)这件事和互联网存在的时间差不多一样长.今天大众好像更倾向于用 ...
- Python爬虫之PyQuery使用(六)
Python爬虫之PyQuery使用 PyQuery简介 pyquery能够通过选择器精确定位 DOM 树中的目标并进行操作.pyquery相当于jQuery的python实现,可以用于解析HTML网 ...
- Python爬虫个人记录(二) 获取fishc 课件下载链接
参考: Python爬虫个人记录(一)豆瓣250 (2017.9.6更新,通过cookie模拟登陆方法,已成功实现下载文件功能!!) 一.目的分析 获取http://bbs.fishc.com/for ...
- Python之路(第四十六篇)多种方法实现python线程池(threadpool模块\multiprocessing.dummy模块\concurrent.futures模块)
一.线程池 很久(python2.6)之前python没有官方的线程池模块,只有第三方的threadpool模块, 之后再python2.6加入了multiprocessing.dummy 作为可以使 ...
- python爬虫与mysql,mongobd(1)(2)第一个视频python_pymysql 安装与使用类型,import解决 问题之模块引ru 就是解决你的问题
import pymysql.cursors ''' 1.创建连接 2.创建游标 3.执行sql 5.接受结果 ''' # 1.连接 connection =pymysql.Connect( # 域名 ...
- Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站爬取---前言 从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情.希望可以做好. 为了写好爬虫,我们 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- Python爬虫入门教程 61-100 写个爬虫碰到反爬了,动手破坏它!
python3爬虫遇到了反爬 当你兴冲冲的打开一个网页,发现里面的资源好棒,能批量下载就好了,然后感谢写个爬虫down一下,结果,一顿操作之后,发现网站竟然有反爬措施,尴尬了. 接下来的几篇文章,我们 ...
- Python 爬虫——抖音App视频抓包
APP抓包 前面我们了解了一些关于 Python 爬虫的知识,不过都是基于 PC 端浏览器网页中的内容进行爬取.现在手机 App 用的越来越多,而且很多也没有网页端,比如抖音就没有网页版,那么上面的视 ...
- 23个Python爬虫开源项目代码,让你一次学个够
今天为大家整理了23个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快 1.WechatSogou [1]– 微信公众号 ...
随机推荐
- Vue 3 组件基础与模板语法详解
title: Vue 3 组件基础与模板语法详解 date: 2024/5/24 16:31:13 updated: 2024/5/24 16:31:13 categories: 前端开发 tags: ...
- C# winform GDI+ 五子棋 (二):根据博弈算法写的人机AI(抄的别人的)
白棋是ai,最后ai走赢了. 根据博弈算法的一个AI.遍历深度6层,下子很慢.其实我是从别人的代码里复制的算法,改到自己上面用了. 这个博弈算法 class GameAI { /// <summ ...
- Ceph对象网关,多区域网关
目录 Ceph对象网关,多区域网关 1. 文件系统与对象存储的区别 1.1 对象存储使用场景 1.2 对象存储的接口标准 1.3 桶(bucket) 2. rgw 2.1 对象存储认证 2.2 对象网 ...
- mysql binlog查看指定数据库
1.mysql binlog查看指定数据库的方法 MySQL 的 binlog(二进制日志)主要记录了数据库上执行的所有更改数据的 SQL 语句,包括数据的插入.更新和删除等操作.但直接查看 binl ...
- kali linux主题美化
Kali 主题美化 先放张安装了主题的图片: 执行下面命令下载主题文件: git clone https://github.com/daniruiz/flat-remix-gtk.git git cl ...
- 喜讯!INFINI Easysearch 在墨天轮数据库排名中挺进前30!
近日,2023 年 10 月的 墨天轮中国数据库流行度排行 火热出炉,本月共有 283 个数据库参与排名,中国数据库行业竞争日益激烈.其中,极限科技旗下软件产品 INFINI Easysearch 稳 ...
- ES 关于 remote_cluster 的一记小坑
最近有小伙伴找到我们说 Kibana 上添加不了 Remote Cluster,填完信息点 Save 直接跳回原界面了.具体页面,就和没添加前一样. 我们和小伙伴虽然隔着网线但还是进行了深入.详细的交 ...
- OpenTelemetry Logging 思维导图,收藏
Log 是最常用.最自然的监控数据类型之一,具有以下的优点: 日志的内容比指标更加丰富,可以提供更多的细节信息,帮助开发人员和运维人员更好地理解应用程序的运行状况,通过日志几乎可以重现.还原系统的完整 ...
- 什么是spring框架?
spring是一个开放源代码的设计层面框架,它解决的是业务逻辑层和其他各层的松耦合问题,是一个分层的javaEE一站式轻量级开源框架
- Javascript高级程序设计第四章 | ch4 | 阅读笔记
变量.作用域与内存 原始值与引用值 什么是字面量形式? let obj = { key1: val1, key2: val2, foo () { } } 这就是字面量形式,手动声明一个对象的属性和方法 ...