一键接入大模型:One-Api本地安装配置实操
前言
最近准备学习一下 Semantic Kernel, OpenAI 的 Api 申请麻烦,所以想通过 One-api 对接一下国内的在线大模型,先熟悉一下 Semantic Kernel 的基本用法,本篇文章重点记录一下OneApi安装配置的过程。
讯飞星火有 3.5 模型的 200w 个人免费 token,可以拿来学习。
什么是 One-Api?
通过标准的 OpenAI API 格式访问所有的大模型
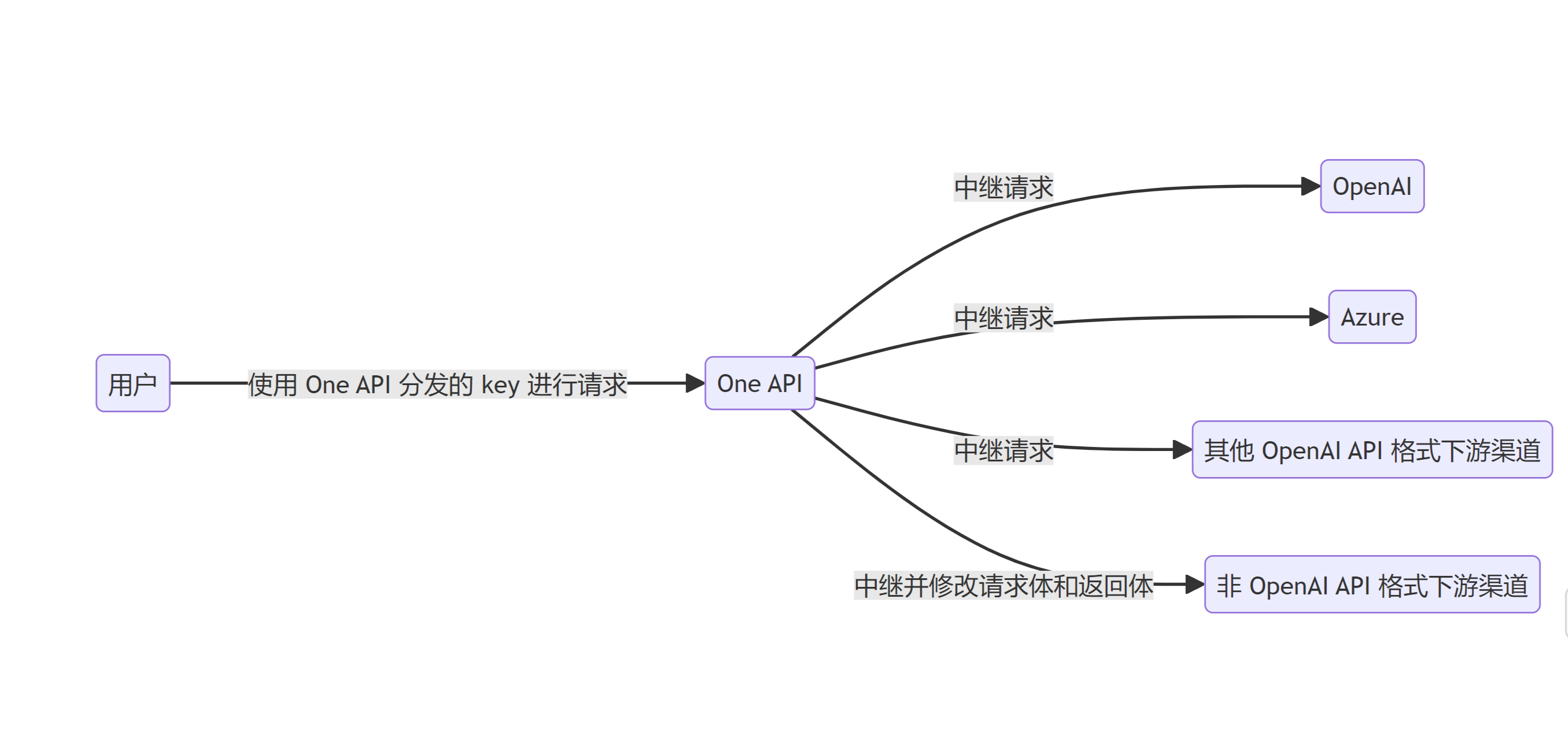
支持多种大模型:
- OpenAI ChatGPT 系列模型(支持 Azure OpenAI API)
- Anthropic Claude 系列模型 (支持 AWS Claude)
- Google PaLM2/Gemini 系列模型
- Mistral 系列模型
- 百度文心一言系列模型
- 阿里通义千问系列模型
- 讯飞星火认知大模型
- 智谱 ChatGLM 系列模型
- 360 智脑
- 腾讯混元大模型
- Moonshot AI
- 百川大模型
- 字节云雀大模型 (WIP)
- MINIMAX
- Groq
- Ollama
- 零一万物
- 阶跃星辰
- Coze
- Cohere
- DeepSeek
- Cloudflare Workers AI
- DeepL
本地 Docker Destop 安装 One-Api
- 先拉取
one-api镜像
docker pull justsong/one-api
使用 SQLite 的部署命令:
- 启动容器 默认宿主机端口为
3000
docker run --name one-api -d --restart always -p 3000:3000 -e TZ=Asia/Shanghai -v C:/LLM/OneApi-V-Data:/data justsong/one-api
因为我的宿主机是
Windows的操作系统所以数据卷映射的宿主机盘需要注意是带Windows盘符

one-api 配置界面
浏览器打开http://localhost:3000/
- 默认
root账号
one-api提供了开箱即用的功能,有一个默认的root账号,密码是123456
第一次登录后需要修改密码。
配置渠道
- 配置讯飞星火 3.5 模型!
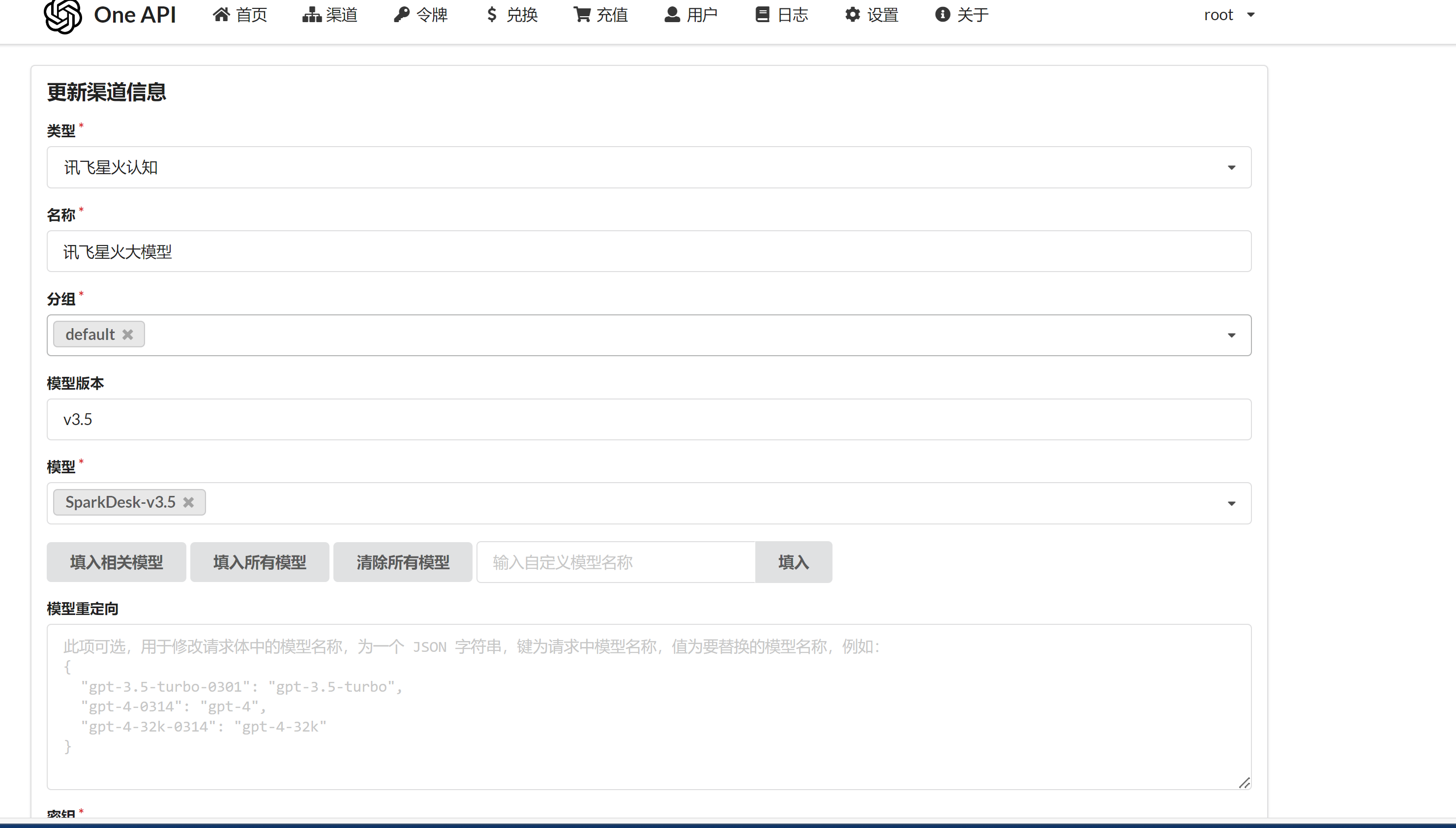
- 查看渠道列表
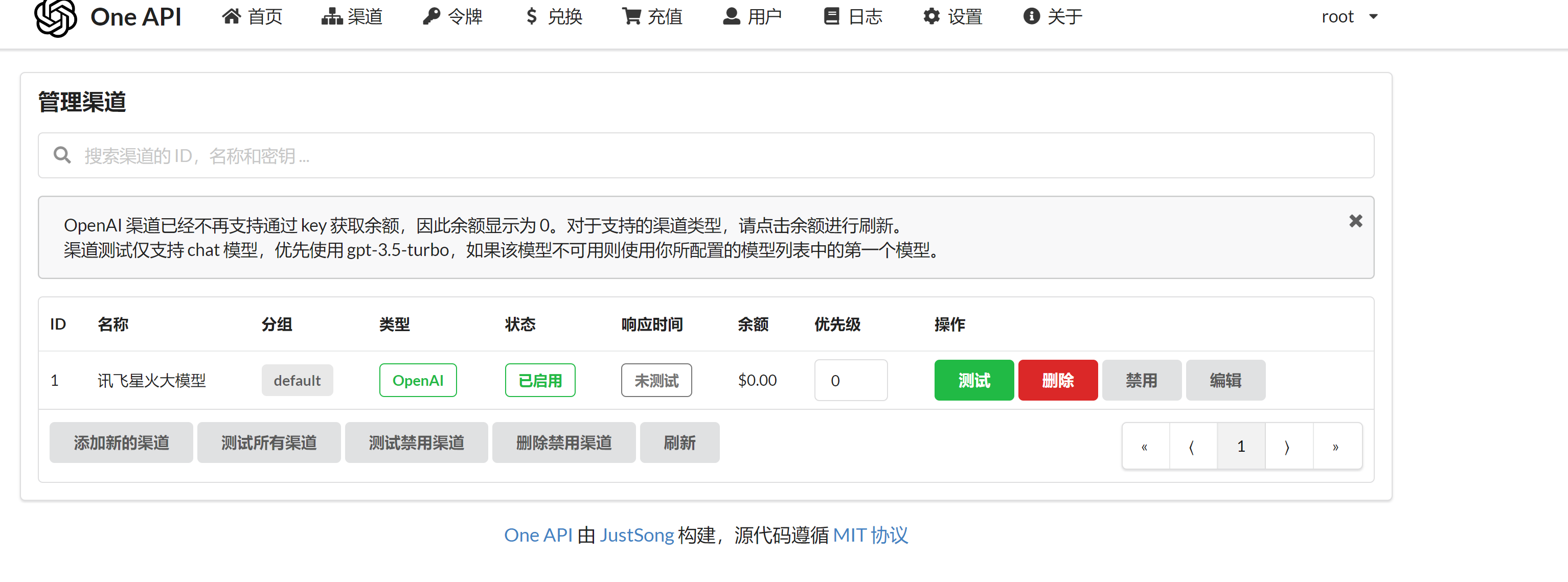
密钥这个地方需要注意格式:APPID|APISecret|APIKey
- 申请令牌
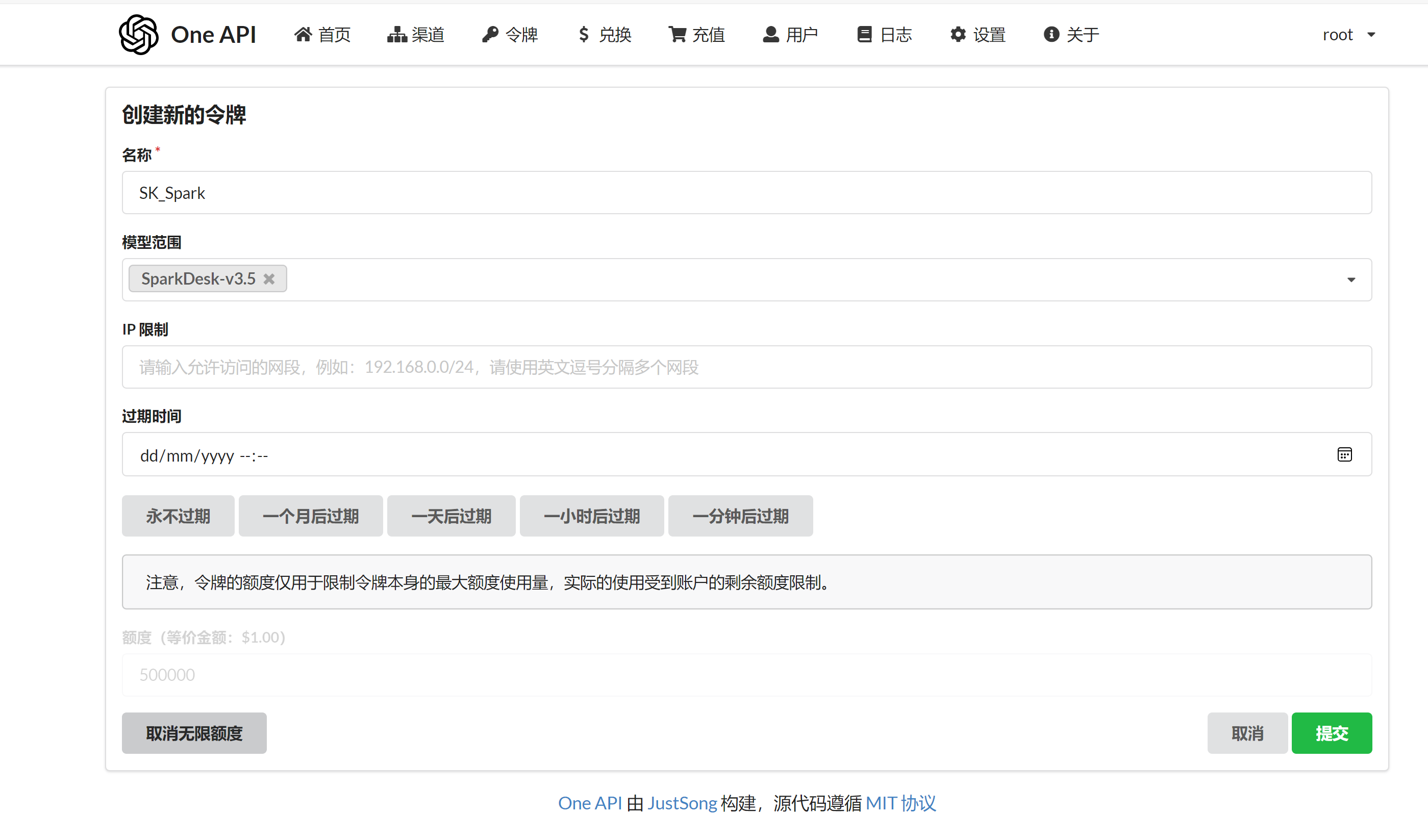
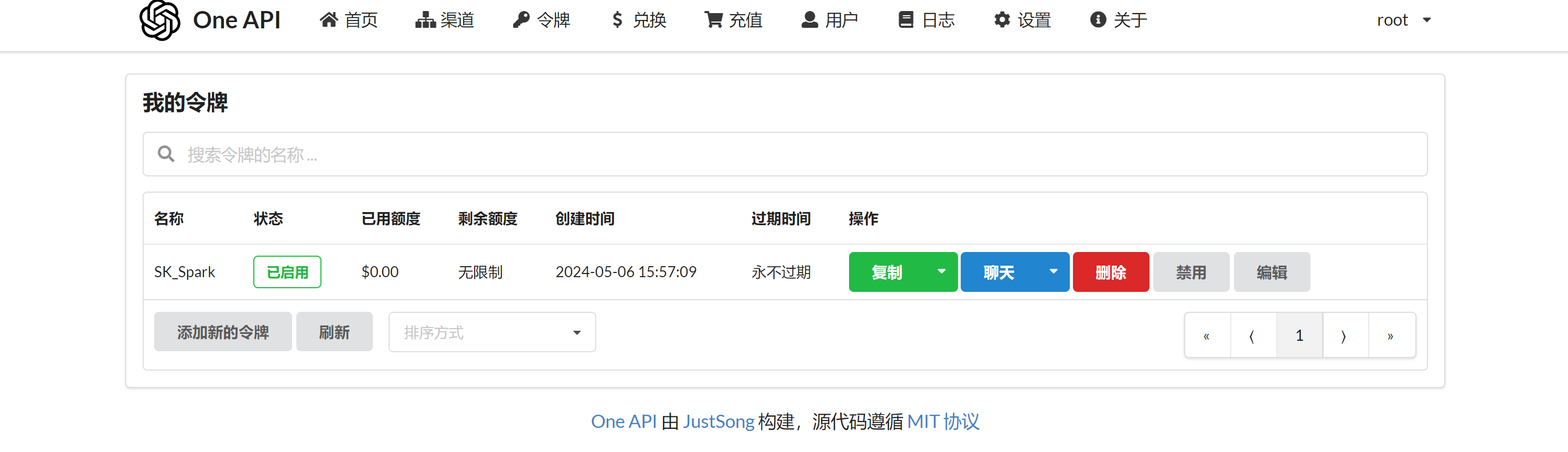
拿到密钥就可以在我们项目中以
OpenAI格式去请求我们的大模型接口
测试
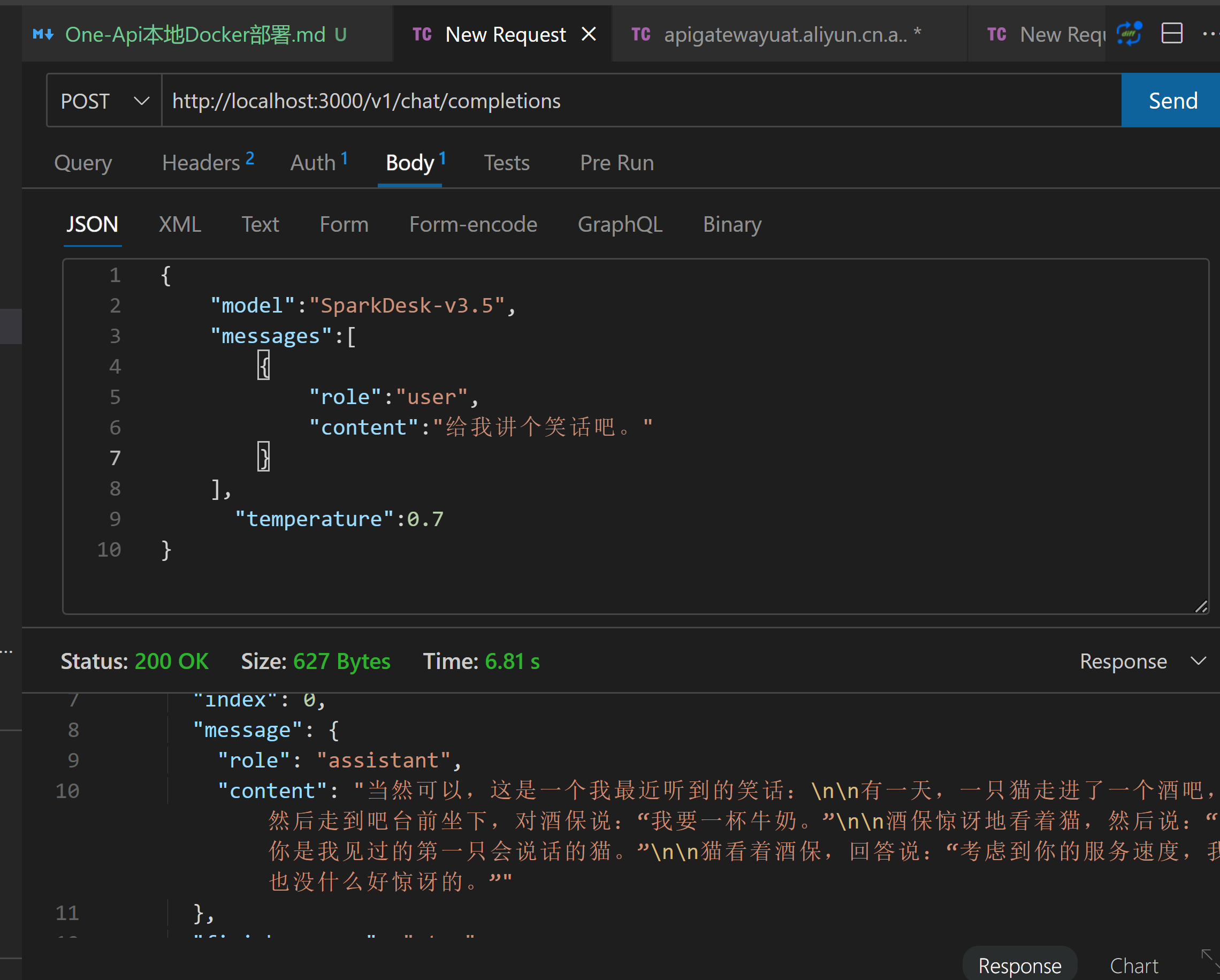
- 在接口测试工具先看一下效果
地址
http://localhost:3000/v1/chat/completions
请求头
Authorization:Bearer {OneApiToken}
- 接口管理工具查看效果
接口入参
{
"model": "SparkDesk-v3.5",
"messages": [
{
"role": "user",
"content": "给我讲个笑话吧。"
}
],
"temperature": 0.7
}
接口回参
{
"id": "chatcmpl-04025f1484c54770a8d854de360fd06e",
"object": "chat.completion",
"created": 1715000959,
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "当然可以,这是一个我最近听到的笑话:\n\n有一天,一只猫走进了一个酒吧,然后走到吧台前坐下,对酒保说:“我要一杯牛奶。”\n\n酒保惊讶地看着猫,然后说:“你是我见过的第一只会说话的猫。”\n\n猫看着酒保,回答说:“考虑到你的服务速度,我也没什么好惊讶的。”"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 6,
"completion_tokens": 75,
"total_tokens": 81
}
}
最后
到现在为止我们的 One-Api 对接讯飞星火已经成功了,后面就可以愉快的进入 Semantic Kernel 入门学习的教程啦,社区内也有大佬提供了星火大模型的 SDK(Sdcb.SparkDesk)通过SK的 CustomLLM 实现ITextGenerationService等接口也可以愉快的使用SK当然这也是我们后面要学习的内容。
参考文献
实战教学:用 Semantic Kernel 框架集成腾讯混元大模型应用
一键接入大模型:One-Api本地安装配置实操的更多相关文章
- Web APi之安装配置实现Cors跨域
参考:http://www.cnblogs.com/CreateMyself/p/4836628.html 1.通过NuGet下载程序包,搜索程序包[Microsoft.AspNet.WebApi.C ...
- Oracle10gXE和Oracle SQL Developer本地安装配置
第1部分 Oracle10gXE安装 Oracle10gXE安装的安装几乎是一路next就可以安装好:但是中间设置的用户名.密码.口令.SID等信息一定记住,后面需要使用. 第2部分 Oracle S ...
- 吴裕雄--天生自然 HADOOP大数据分布式处理:安装配置MYSQL数据库
安装之前先安装基本环境:yum install -y perl perl-Module-Build net-tools autoconf libaio numactl-libs # 下载mysql源安 ...
- 【大数据】Hadoop单机安装配置
1.解压缩hadoop-2.7.6.tar.gz到/home/hadoop/Soft目录中 2.创建软链接,方便hadoop升级 ln -s /home/hadoop/Soft/hadoop-2.7 ...
- 本地安装配置redis
Windows中redis的下载及安装.设置 本文是转载自:https://www.cnblogs.com/jylee/p/9844965.html 下载地址: https://github.co ...
- 本地安装配置Gradle及IDEA使用本地Gradle
一.下载Gradle 下载地址:http://services.gradle.org/distributions/ 下载版本的bin.zip 二.配置环境变量 三.验证 在cmd模式下查看 ...
- 吴裕雄--天生自然 HADOOP大数据分布式处理:安装配置Tomcat服务器
下载链接:https://tomcat.apache.org/download-80.cgi tar -zxvf apache-tomcat-8.5.42.tar.gz -C /usr/local/s ...
- 吴裕雄--天生自然 HADOOP大数据分布式处理:安装配置JAVA
tar -xzvf jdk-8u151-linux-x64.tar.gz -C /usr/local/src sudo vim /etc/profile .编辑/etc/profile # JAVA ...
- GitBook安装部署实操手册
前言 GitBook是一个基于Node.js的命令行工具,可使用Git和Markdown来编写文档,赞誉太多,不再赘述. Node.js 下载安装包 cd /tmp wget https://node ...
- zookeeper之二:zookeeper3.7.0安装过程实操
前面分享了zookeeper的基本知识,下面分享有关zookeeper安装的知识. 1.下载 zookeeper的官网是:https://zookeeper.apache.org/ 在官网上找到下载链 ...
随机推荐
- KingbaseES V8R6 集群运维案例 -- 磁盘空间问题导致集群故障
某商业银行生产系统KingbaseES读写分离集群主库出现故障,导致集群主备发生切换.客户要求说明具体的原因. KingbaseES读写分离集群基本信息: KingbaseES集群信息 操作系统 ...
- KingbaseES 咨询锁
传统的事务性锁,读/写会自动加锁,读/写完成后会自动解锁(加解锁机制在细节上复杂),这是一种隐式的锁机制.对于加锁后的并发控制,也就是默认的写不阻塞读,是通过MVCC机制解决的.这种锁完全不需要人为干 ...
- linux 禁用休眠,挂起,睡眠
参照 https://www.cnblogs.com/minseo/p/13557947.html 禁用休眠前查看状态 systemctl status sleep.target suspend.ta ...
- docker笔记之安装
本文于2017年上半年完成,发布在个人博客网站上. 考虑个人博客因某种原因无法修复,于是在博客园安家,之前发布的文章逐步搬迁过来. 最近由于工作关系,接触到了docker技术.为了对docker有更多 ...
- SQL 数据操作技巧:SELECT INTO、INSERT INTO SELECT 和 CASE 语句详解
SQL SELECT INTO 语句 SELECT INTO 语句将数据从一个表复制到一个新表中. SELECT INTO 语法 将所有列复制到新表中: SELECT * INTO newtable ...
- Go 语言中切片的使用和理解
切片与数组类似,但更强大和灵活.与数组一样,切片也用于在单个变量中存储相同类型的多个值.然而,与数组不同的是,切片的长度可以根据需要增长和缩小.在 Go 中,有几种创建切片的方法: 使用[]datat ...
- 动态库 DLL 封装四:对dll二次封装,开放回调函数,并减少回调函数中参数个数
背景: 我需要对一个dll进行二次封装,其中有一个接口,里面的参数需要传回调函数. 需求: 这个回调函数,我需要开放出去,并且减少回调函数参数的个数 示例: // 回调原型 VOID __stdcal ...
- 【直播预告】HarmonyOS极客松赋能直播第三期:一次开发多端部署与ArkTS卡片开发
- DevEco Studio强大的预览功能让开发效率大大提升!
原文:https://mp.weixin.qq.com/s/C5DL0wBubDX3exvPpeXBPQ,点击链接查看更多技术内容. 应用的开发过程中,往往需要多次调试和修改,如果支持实时预览,边 ...
- sql 语句系列(计算的进阶)[八百章之第十六章]
前言 介绍两个实用的sql查询语句. 1.计算平均数时候,去除最大值和最小值. 2.修改累计值. 计算平均数时候,去除最大值和最小值 sql server: select AVG(sal) from( ...