顶会ICSE-2023发布LIBRO技术,利用大模型技术进行缺陷重现,自动重现率达33%
摘要:本文围绕LIBRO技术的主要步骤进行介绍。
本文分享自华为云社区《【LLM for SE】顶会ICSE-2023发布LIBRO技术,利用大模型技术进行缺陷重现,自动重现率(33%)实现业界突破》,作者: 华为云软件分析Lab 。
随着大模型(Large Language Model, LLM)技术的发展,LLM在许多软件工程任务上表现出良好的效果,比如代码生成、搜索、对话等任务。近期,许多研究工作结合LLM技术和软件分析技术来解决软件工程领域的问题。软件工程顶级会议ICSE2023文章《Large Language Models are Few-shot Testers: Exploring LLM-based General Bug Reproduction》(来自韩国科学技术院大学的Shin Yoo团队)发布了LIBRO技术,是首个面向通用缺陷的自动重现工作。该技术有效利用大模型技术提升了缺陷重现技术的有效性,实现业界突破。实验结果表明,在主流数据集Defects4J中,LIBRO技术可根据缺陷报告自动生成测试用例并重现出251个缺陷(共750个缺陷),自动重现率达33%。LIBRO借助LLM技术在NLP领域的突出进展,在SE领域中的缺陷重现问题中实现重大突破。利用LLM的技术优势来提升SE领域的技术能力有望成为行业趋势,吸引越来越多的研究者和业界从业人员。
论文链接详见:https://arxiv.org/abs/2209.11515
以下围绕LIBRO技术的主要步骤进行介绍。如图1所示,LIBRO框架主要包括四个步骤,分别是:(A) 提示工程、(B) LLM查询、(C) 后处理、(D) 选择&排序。
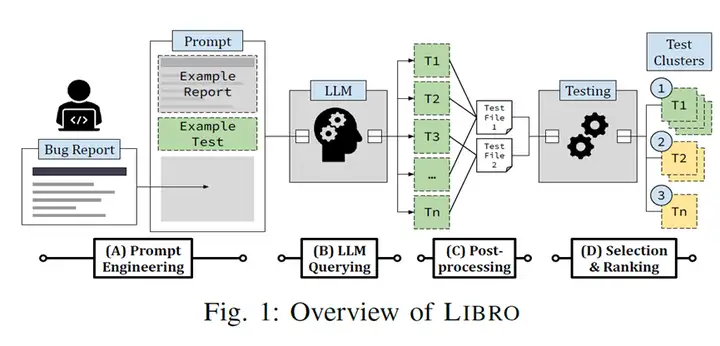
步骤A(提示工程):在LLM技术中,如何构造有效的提示进行查询是一个关键问题。LIBRO基于缺陷报告构建提示信息,利用的信息包括缺陷报告的标题和描述信息。此外,LIBRO还在提示信息中加入测试用例实例引导大模型生成测试用例。下图给出了一个缺陷报告的实例和对应的提示信息。


步骤B (LLM查询):将之前构造的提示信息输入大模型,大模型将输出一个测试用例生成的结果。具体来说,LIBRO使用的大模型是基于GPT-3的CodeX模型。LIBRO构造的提示信息末尾是“public void test”,这会引导大模型生成一段测试用例代码。此外,LIBRO通过加权随机采样(weighted random sampling)来提升大模型查询效果,并生成多个测试用例作为备选测试用例。下图是基于之前例子里的提示信息生成的一段测试用例代码。

步骤C (后处理):LIBRO对大模型生成的测试用例的后处理指将测试用例函数放入对应测试类中,并解决执行该测试用例所需的依赖。具体来说,LIBRO首先根据测试类与测试用例函数的文本相似度来计算测试类和测试函数的映射关系。该策略在业界主流数据集中能够成功匹配89%的测试类与测试函数的关系,是一种有效的匹配策略。为了解决测试用例函数的依赖问题,LIBRO首先解析生成的测试用例函数,并识别变量类型以及引用的类名/构造函数/异常。然后,LIBRO通过在测试类中与现有import语句进行词法匹配,并过滤掉已经导入的类名。
步骤D (选择&排序):一个能够重现缺陷的测试用例指当且仅当测试用例因为缺陷报告中说明的缺陷而执行失败。换而言之,LIBRO生成能够重现缺陷的必要条件是:该测试用例在被测程序的错误版本中编译成功但是执行失败。该研究工作将这类测试用例称为FIB(Fail In the Buggy program)。LIBRO对大模型生成的若干测试用例进行选择和排序,从而优先推荐质量更高的生成结果。
LIBRO的选择和排序算法主要包括三种启发式策略:(1)如果测试用例执行失败信息和/或显示了在缺陷报告中提到的行为(比如异常或输出值),那么该测试用例可能是重现缺陷的测试用例。(2)LIBRO根据选择测试用例的集合大小来观察大模型生成的测试用例之间的一致性。直觉上,如果大模型生成大量相似的测试用例,那么说明大模型认为这类测试用例具有更高的可信度。即,这类测试用例是大模型达成的共识。(3)LIBRO根据测试用例的长度来决定它们的优先级,原因是短的测试用例更便于用户理解。
缺陷重现实例介绍:
以下是一个LIBRO重现AssertJ-Core项目中编号为2666的缺陷报告的真实案例介绍。如下截图Table VIII是实际缺陷报告,如下截图Listing 4是利用LIBRO生成的测试用例。缺陷报告中提到在特定条件下比较i和I会失败。LIBRO根据缺陷报告的描述自动生成了能够重现该缺陷的测试用例。


文章来自:PaaS技术创新Lab;PaaS技术创新Lab隶属于华为云,致力于综合利用软件分析、数据挖掘、机器学习等技术,为软件研发人员提供下一代智能研发工具服务的核心引擎和智慧大脑。我们将聚焦软件工程领域硬核能力,不断构筑研发利器,持续交付高价值商业特性!加入我们,一起开创研发新“境界”!
PaaS技术创新Lab主页链接:https://www.huaweicloud.com/lab/paas/home.html
顶会ICSE-2023发布LIBRO技术,利用大模型技术进行缺陷重现,自动重现率达33%的更多相关文章
- 利用大数据技术处理海量GPS数据
我秀中国物联网地图服务平台目前接入的监控车辆近百万辆,每天采集GPS数据7亿多条,产生日志文件70GB,使用传统的数据处理方式非常耗时. 比如,仅仅对GPS做一些简单的统计分析,程序就需要几个小时才能 ...
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
- 大数据技术人年度盛事! BDTC 2016将于12月8-10日在京举行
2016年12月8日-10日,由中国计算机学会(CCF)主办,CCF大数据专家委员会承办,中国科学院计算技术研究所和CSDN共同协办的2016中国大数据技术大会(Big Data Technology ...
- 跟我一起学WCF(2)——利用.NET Remoting技术开发分布式应用
一.引言 上一篇博文分享了消息队列(MSMQ)技术来实现分布式应用,在这篇博文继续分享下.NET平台下另一种分布式技术——.NET Remoting. 二..NET Remoting 介绍 2.1 . ...
- TOP100summit:【分享实录-WalmartLabs】利用开源大数据技术构建WMX广告效益分析平台
本篇文章内容来自2016年TOP100summitWalmartLabs实验室广告平台首席工程师.架构师粟迪夫的案例分享. 编辑:Cynthia 粟迪夫:WalmartLabs实验室广告平台首席工程师 ...
- 利用Spring.Net技术打造可切换的分布式缓存读写类
利用Spring.Net技术打造可切换的Memcached分布式缓存读写类 Memcached是一个高性能的分布式内存对象缓存系统,因为工作在内存,读写速率比数据库高的不是一般的多,和Radis一样具 ...
- 利用过采样技术提高ADC测量微弱信号时的分辨率
1. 引言 随着科学技术的发展,人们对宏观和微观世界逐步了解,越来越多领域(物理学.化学.天文学.军事雷达.地震学.生物医学等)的微弱信号需要被检测,例如:弱磁.弱光.微震动.小位移.心电.脑电等[1 ...
- 利用JSP编程技术实现一个简单的购物车程序
实验二 JSP编程 一.实验目的1. 掌握JSP指令的使用方法:2. 掌握JSP动作的使用方法:3. 掌握JSP内置对象的使用方法:4. 掌握JavaBean的编程技术及使用方法:5. 掌握JSP ...
- 利用apache伪静态技术防止盗链
(在我们制作网站的过程中,可能会遇到这样的问题,就是其他的网站直接盗用了我们网站的图片或css或js,这样可能会大大增加我们自己网站的负载. 所以,我们应该考虑一下怎样防止这样的事情发生.) 下面我们 ...
- 利用内存锁定技术防止CE修改
利用内存锁定技术防止CE修改 通过这种在R3环利用的技术,我们可以来达到保护内存的目的,像VirtualProtect等函数来修改页属性根本无法修改. 而CE修改器推测应该使用VirtualProte ...
随机推荐
- (原创)【B4A】一步一步入门07:EditText,文本框、密码框、键盘样式、提示文本(控件篇03)
一.前言 本篇教程,我们来讲一下常用的控件:EditText(文本输入框). 本篇教程将会讲解文本框的基本使用,如:提示文本.密码文本.键盘样式等. 相信看完的你,一定会有所收获! 本文地址:http ...
- Salesforce Javascript(三) 小结1
本篇参考: https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Functions https://developer.mozi ...
- Google Protobuf 编解码
更多内容,前往个人博客 Protobuf 全称:Google Protocol Buffers,由谷歌开源而来,经谷歌内部测试使用.它将数据结构以 .proto 文件进行描述,通过代码生成工具可以生成 ...
- 【LeetCode动态规划#05】背包问题的理论分析(基于代码随想录的个人理解,多图)
背包问题 问题描述 背包问题是一系列问题的统称,具体包括:01背包.完全背包.多重背包.分组背包等(仅需掌握前两种,后面的为竞赛级题目) 下面来研究01背包 实际上即使是最经典的01背包,也不会直接出 ...
- 深入理解 python 虚拟机:字节码灵魂——Code obejct
深入理解 python 虚拟机:字节码灵魂--Code obejct 在本篇文章当中主要给大家深入介绍在 cpython 当中非常重要的一个数据结构 code object! 在上一篇文章 深入理解 ...
- 超全 泛微 E9 Ecology 9开发资料大全 开源资源下载 泛微E9二次开发 泛微开发实战经验 泛微开发实战例子 泛微二次开发项目例子 泛微二次开发Demo 泛微二次开发完整例子 泛微二次开发入门
由于工作需要,E9在泛微一推出来,以前所在的企业就第一时间上线了,经过四年多的运行,功能强大再加上在上面开发非常多的业务,一般的企业员工只需要打开泛微就可以处理完平时信息化的业务.后来又去外包公司专业 ...
- Anaconda 安装 PyTorch 和 DGL
安装 PyTorch Anaconda 是 PyTorch 官方推荐的包管理工具,它会帮助安装所有的依赖项.当使用 conda 安装的时候,可能会出现下载过慢的问题,需要更换清华源来代替默认的cond ...
- Django笔记二十二之多数据库操作
本文首发于公众号:Hunter后端 原文链接:Django笔记二十二之多数据库操作 这一篇笔记介绍一下多数据库操作. 在第十篇笔记的时候,简单介绍过 using() 的使用方法,多个数据库就是通过 u ...
- FreeSWITCH添加iLBC编码及转码
操作系统 :CentOS 7.6_x64 FreeSWITCH版本 :1.10.9 一.安装ilbc库 从第三方库里下载指定版本: git clone https://freeswitch.org/s ...
- 飞桨paddlespeech语音唤醒推理C实现
上篇(飞桨paddlespeech 语音唤醒初探)初探了paddlespeech下的语音唤醒方案,通过调试也搞清楚了里面的细节.因为是python 下的,不能直接部署,要想在嵌入式上部署需要有C下的推 ...