多智能体强化学习算法【三】【QMIX、MADDPG、MAPPO】
相关文章:
多智能体强化学习算法【一】【MAPPO、MADDPG、QMIX】
多智能体强化学习算法【二】【MADDPG、QMIX、MAPPO】
多智能体强化学习算法【三】【QMIX、MADDPG、MAPPO】
1.QMIX算法简述
QMIX是一个多智能体强化学习算法,具有如下特点:
1. 学习得到分布式策略。
2. 本质是一个值函数逼近算法。
3. 由于对一个联合动作-状态只有一个总奖励值,而不是每个智能体得到一个自己的奖励值,因此只能用于合作环境,而不能用于竞争对抗环境。
4. QMIX算法采用集中式学习,分布式执行应用的框架。通过集中式的信息学习,得到每个智能体的分布式策略。
5. 训练时借用全局状态信息来提高算法效果。是后文提到的VDN方法的改进。
6. 接上一条,QMIX设计一个神经网络来整合每个智能体的局部值函数而得到联合动作值函数,VDN是直接求和。
7. 每个智能体的局部值函数只需要自己的局部观测,因此整个系统在执行时是一个分布式的,通过局部值函数,选出累积期望奖励最大的动作执行。
8. 算法使联合动作值函数与每个局部值函数的单调性相同,因此对局部值函数取最大动作也就是使联合动作值函数最大。
9. 算法针对的模型是一个分布式多智能体部分可观马尔可夫决策过程(Dec-POMDP)。
1. 1 多智能体强化学习核心问题
在多智能体强化学习中一个关键的问题就是如何学习联合动作值函数,因为该函数的参数会随着智能体数量的增多而成指数增长,如果动作值函数的输入空间过大,则很难拟合出一个合适函数来表示真实的联合动作值函数。另一个问题就是学得了联合动作值函数后,如何通过联合值函数提取出一个优秀的分布式的策略。这其实是单智能体强化学习拓展到MARL的核心问题。
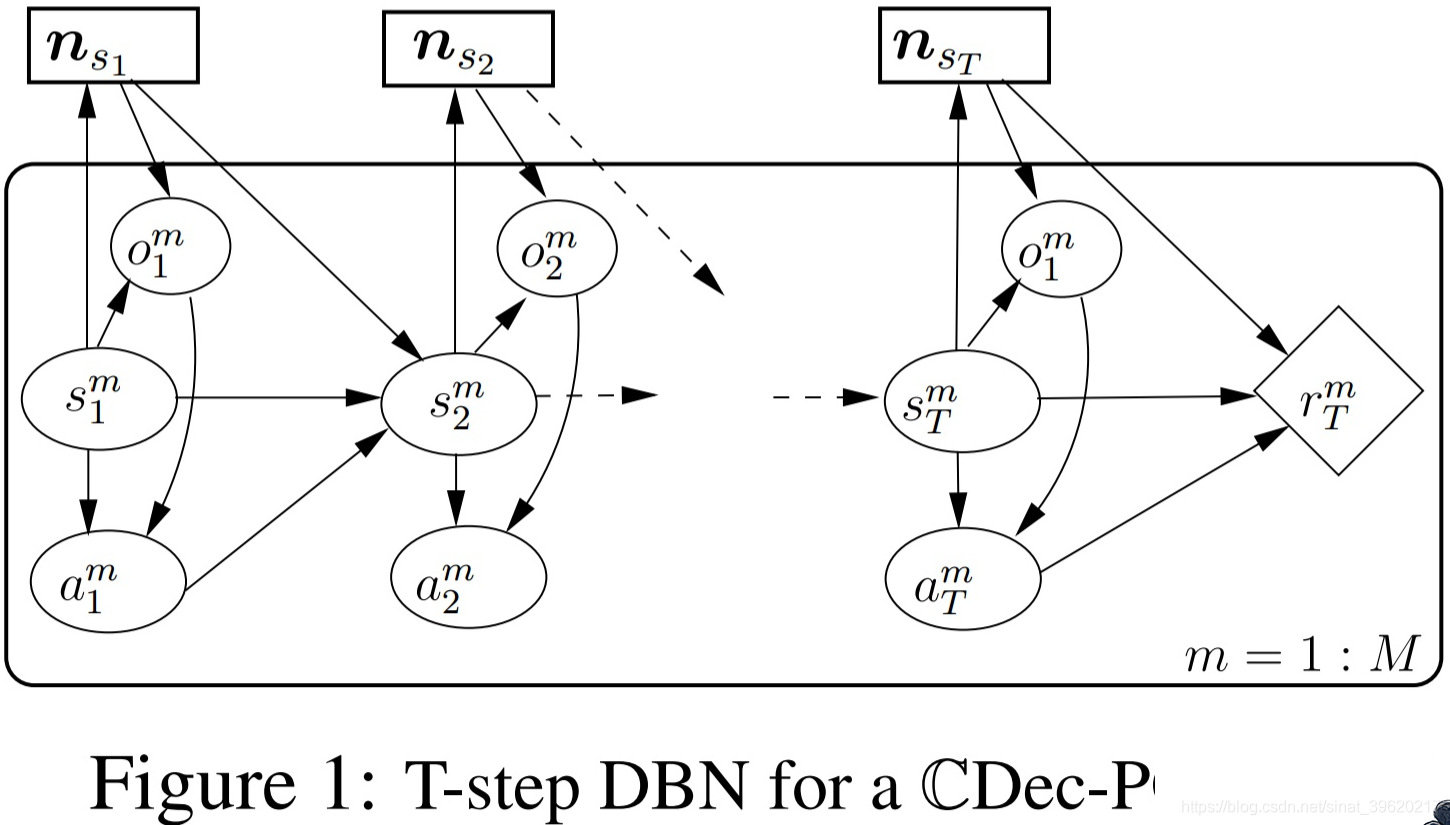
1)Dec-POMDP
Dec-POMDP是将POMDP拓展到多智能体系统。每个智能体的局部观测信息,动作
,系统状态为
。其主要新定义了几个概念,简要介绍几个主要的。每个智能体的动作-观测历史可表示为
表示从初始状态开始,该智能体的时序动作-观测记录,联合动作-观测历史
表示从初始状态开始,所有智能体的时序动作-观测记录。则每个智能体的分布式策略为
,其值函数为
都是跟动作-观测历史
有关,而不是跟状态有关了。
2) IQL
IQL(independent Q-learning)就是非常暴力的给每个智能体执行一个Q-learning算法,因为共享环境,并且环境随着每个智能体策略、状态发生改变,对每个智能体来说,环境是动态不稳定的,因此这个算法也无法收敛,但是在部分应用中也具有较好的效果。
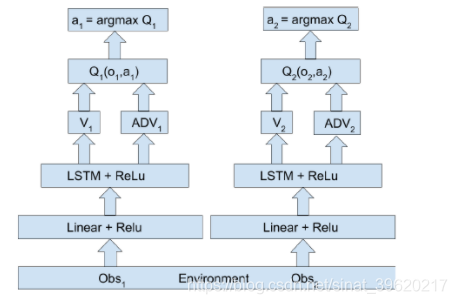
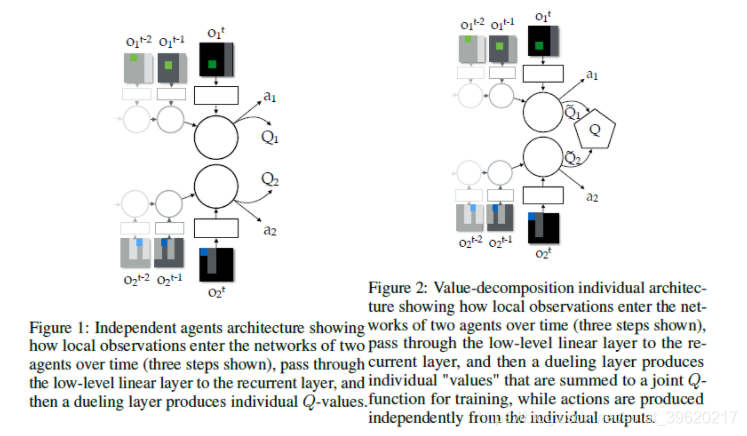
3) VDN
VDN(value decomposition networks)也是采用对每个智能体的值函数进行整合,得到一个联合动作值函数。令表示联合动作-观测历史,其中
为动作-观测历史,
表示联合动作。
为联合动作值函数,
为智能体i的局部动作值函数,局部值函数只依赖于每个智能体的局部观测。VDN采用的方法就是直接相加求和的方式
虽然不是用来估计累积期望回报的,但是这里依然叫它为值函数。分布式的策略可以通过对每个
取max得到。
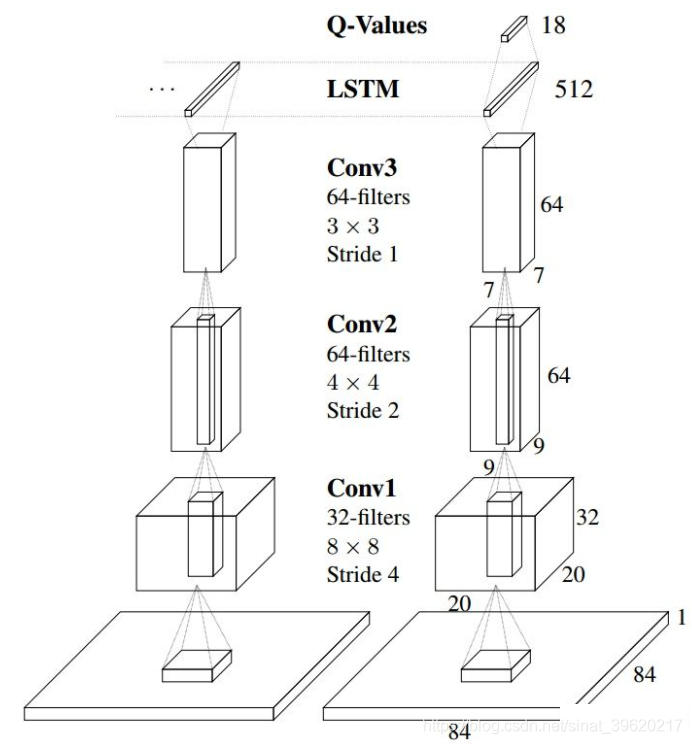
4) DRQN
DRQN是一个用来处理POMDP(部分可观马尔可夫决策过程)的一个算法,其采用LSTM替换DQN卷基层后的一个全连接层,来达到能够记忆历史状态的作用,因此可以在部分可观的情况下提高算法性能。具体讲解可以看强化学习——DRQN分析详解。由于QMIX解决的是多智能体的POMDP问题,因此每个智能体采用的是DRQN算法。
1.2 QMIX
上文“多智能体强化学习核心问题”提到的就是QMIX解决的最核心问题。其是在VDN上的一种拓展,由于VDN只是将每个智能体的局部动作值函数求和相加得到联合动作值函数,虽然满足联合值函数与局部值函数单调性相同的可以进行分布化策略的条件,但是其没有在学习时利用状态信息以及没有采用非线性方式对单智能体局部值函数进行整合,使得VDN算法还有很大的提升空间。
QMIX就是采用一个混合网络对单智能体局部值函数进行合并,并在训练学习过程中加入全局状态信息辅助,来提高算法性能。
为了能够沿用VDN的优势,利用集中式的学习,得到分布式的策略。主要是因为对联合动作值函数取等价于对每个局部动作值函数取
,其单调性相同,如下所示
因此分布式策略就是贪心的通过局部获取最优动作。QMIX将(1)转化为一种单调性约束,如下所示
若满足以上单调性,则(1)成立,为了实现上述约束,QMIX采用混合网络(mixing network)来实现,其具体结构如下所示
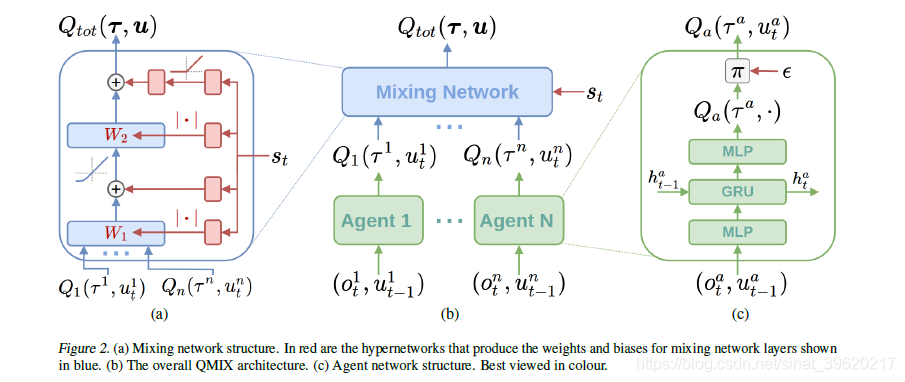
图(c)表示每个智能体采用一个DRQN来拟合自身的Q值函数的到 ,DRQN循环输入当前的观测
以及上一时刻的动作
来得到Q值。
图(b)表示混合网络的结构。其输入为每个DRQN网络的输出。为了满足上述的单调性约束,混合网络的所有权值都是非负数,对偏移量不做限制,这样就可以确保满足单调性约束。
为了能够更多的利用到系统的状态信息 ,采用一种超网络(hypernetwork),将状态
作为输入,输出为混合网络的权值及偏移量。为了保证权值的非负性,采用一个线性网络以及绝对值激活函数保证输出不为负数。对偏移量采用同样方式但没有非负性的约束,混合网络最后一层的偏移量通过两层网络以及ReLU激活函数得到非线性映射网络。由于状态信息
是通过超网络混合到
中的,而不是仅仅作为混合网络的输入项,这样带来的一个好处是,如果作为输入项则
的系数均为正,这样则无法充分利用状态信息来提高系统性能,相当于舍弃了一半的信息量。
QMIX最终的代价函数为
更新用到了传统的DQN的思想,其中b表示从经验记忆中采样的样本数量
表示目标网络。
由于满足上文的单调性约束,对 进行
操作的计算量就不在是随智能体数量呈指数增长了,而是随智能体数量线性增长,极大的提高了算法效率。
1.3 demo
原文中给了一个小示例来说明QMIX与VND的效果差异,虽然QMIX也不能完全拟合出真实的联合动作值函数,但是相较于VDN已经有了很大的提高。
如下图为一个两步合作矩阵博弈的价值矩阵

在第一阶段,只有智能体1的动作能决定第二阶段的状态。在第一阶段,如果智能体1采用动作A 则跳转到上图state2A状态,如果智能体1采用动作B则跳转到上图state2B状态,第二阶段的每个状态的价值矩阵如上两图所示。
现在分别用VDN与QMIX学习上述矩阵博弈各个状态的值函数矩阵,得到结果如下图所示
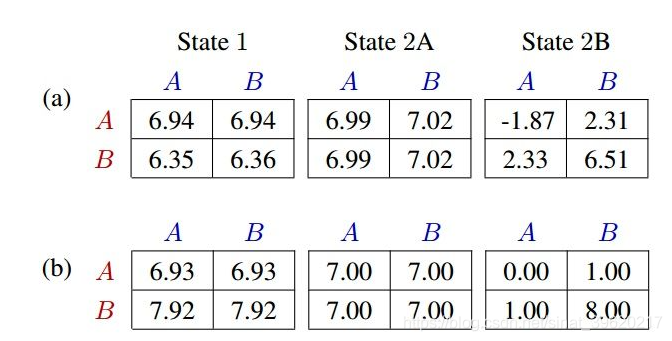
(a)为VDN拟合结果,(b)为QMIX拟合结果。可以从上图,VDN的结果是智能体1 在第一阶段采用动作A ,显然这不是最佳状态,而QMIX是智能体1在第一阶段采用动作B,得到了最大的累积期望奖励。由上可得QMIX的逼近能力比VDN更强,QMIX算法的效果更好
多智能体强化学习算法【三】【QMIX、MADDPG、MAPPO】的更多相关文章
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 强化学习算法DQN
1 DQN的引入 由于q_learning算法是一直更新一张q_table,在场景复杂的情况下,q_table就会大到内存处理的极限,而且在当时深度学习的火热,有人就会想到能不能将从深度学习中借鉴方法 ...
- 强化学习(三)用动态规划(DP)求解
在强化学习(二)马尔科夫决策过程(MDP)中,我们讨论了用马尔科夫假设来简化强化学习模型的复杂度,这一篇我们在马尔科夫假设和贝尔曼方程的基础上讨论使用动态规划(Dynamic Programming, ...
- 【转载】 强化学习(三)用动态规划(DP)求解
原文地址: https://www.cnblogs.com/pinard/p/9463815.html ------------------------------------------------ ...
- 强化学习(三)—— 时序差分法(SARSA和Q-Learning)
1.时序差分法基本概念 虽然蒙特卡洛方法可以在不知道状态转移概率矩阵的前提下,灵活地求解强化学习问题,但是蒙特卡洛方法需要所有的采样序列都是完整的状态序列.如果我们没有完整的状态序列就无法用蒙特卡洛方 ...
- 强化学习算法Policy Gradient
1 算法的优缺点 1.1 优点 在DQN算法中,神经网络输出的是动作的q值,这对于一个agent拥有少数的离散的动作还是可以的.但是如果某个agent的动作是连续的,这无疑对DQN算法是一个巨大的挑战 ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 强化学习Q-Learning算法详解
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
随机推荐
- 【Boost】boost.log 要点笔记
常用简写: namespace logging = boost::log; namespace src = boost::log::sources; namespace expr = boost::l ...
- 0x01 基本算法-位运算
A题:a^b https://ac.nowcoder.com/acm/contest/996/A 题目描述 求 a 的 b 次方对 p 取模的值,其中 0 <= a,b,p <= 10^9 ...
- AISing Programming Contest 2021(AtCoder Beginner Contest 202) 简单题解记录
补题链接:Here A - Three Dice 水题,问给定三次摇色子的正面,请问3次结果以后相对面的点数和 cout << (21 - a - b - c) << &quo ...
- Metastability 亚稳态问题
亚稳态问题 各种跨时钟域的问题都会归结于亚稳态的问题,IP设计时钟域不超过两个,对于CDC设计要求不高;对于SoC设计来说,CDC处理十分重要 1.什么是亚稳态? transition time 是可 ...
- VSCODE配置tasks.json
1.新建配置任务tasks.json 选择gcc.exe 可以在其中按需修改 { "version": "2.0.0", "tasks": ...
- 【SHELL】跨行内容查找、替换、删除
跨行内容查找.替换.删除 sed '/START-TAG/{:a;N;/END-TAG/!ba};/ID: 222/d' data.txt /START-TAG/ { # Match 'START-T ...
- java - Array 数组反序输出
通过Array类的静态 sort() 方法可实现对数组排序,sort() 方法提供了许多种重载形式,可对任意类型数组进行升序排序. 然而,Array类中没有类似 js 的 reverse 反序输出 ...
- Go-数组-切片
- JVM的GC学习
JVM的GC学习 2023-12-28T17:20:25.182+0800: 7.363: [Full GC (Metadata GC Threshold) [PSYoungGen: 29067K-& ...
- [转帖]Shell脚本数组(实现冒泡排序,直接选择排序,反转排序)
目录 数组 数组定义方法 数组包括的数据类型 获取数组长度 读取某下标赋值 数组遍历 数组切片 数组替换 删除数组 追加数组中的元素 从函数返回数组 加法传参运算 乘法传参运算 数组排序算法 冒泡排序 ...