hdfs的读写数据流
hdfs的读:
hdfs的读写数据流的更多相关文章
- HDFS 文件读写过程
HDFS 文件读写过程 HDFS 文件读取剖析 客户端通过调用FileSystem对象的open()来读取希望打开的文件.对于HDFS来说,这个对象是分布式文件系统的一个实例. Distributed ...
- hdfs api读写文写件个人练习
看下hdfs的读写原理,主要是打开FileSystem,获得InputStream or OutputStream: 那么主要用到的FileSystem类是一个实现了文件系统的抽象类,继承来自org. ...
- HDFS04 HDFS的读写流程
HDFS的读写流程(面试重点) 目录 HDFS的读写流程(面试重点) HDFS写数据流程 网络拓扑-节点距离计算 机架感知(副本存储节点的选择) HDFS的读数据流程 HDFS写数据流程 客服端把D: ...
- HDFS的读写流程——宏观与微观
HDFS的读写流程--宏观与微观 HDFS:分布式文件系统,负责存放数据 分布式文件系统:就是将我们的数据放到多台电脑上存储. 写数据:就是将客户端上的数据上传到HDFS 宏观过程 客户端向HDFS发 ...
- HDFS中的读写数据流
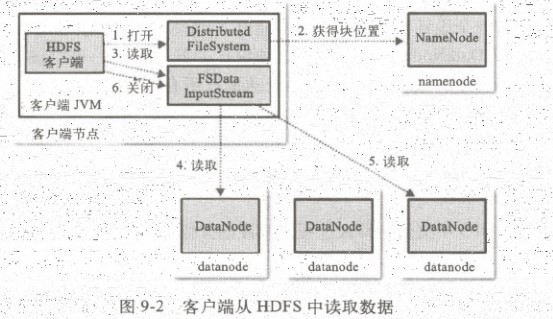
1.文件的读取 在客户端执行读取操作时,客户端和HDFS交互过程以及NameNode和各DataNode之间的数据流是怎样的?下面将围绕图1进行具体讲解. 图 1 客户端从HDFS中读取数据 1)客户 ...
- 【Hadoop】二、HDFS文件读写流程
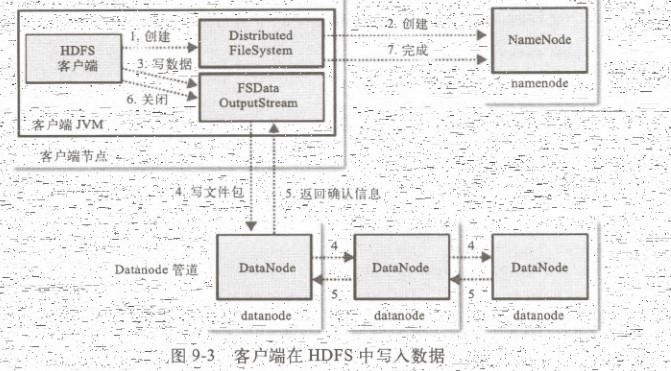
(二)HDFS数据流 作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和dat ...
- hadoop笔记-hdfs文件读写
概念 文件系统 磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍. 文件系统块一般为几千字节,磁盘块一般512字节. hdfs的block.pocket.chu ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- HDFS文件读写过程
参考自<Hadoop权威指南> [http://www.cnblogs.com/swanspouse/p/5137308.html] HDFS读文件过程: 客户端通过调用FileSyste ...
随机推荐
- 【Python】[面性对象编程] 获取对象信息,实例属性和类属性
获取对象信息1.使用isinstance()判断class类型2.dir() 返回一个对象的所有属性和方法3.如果试图获取不存在的对象会抛出异常[AttributeError]4.正确利用对象内置函数 ...
- iOS开发知识点总结
main文件做了这几件事: 1. 创建当前的应用程序 2. 根据4个参数的最后为应用程序设置代理类(默认情况下是AppDelegate) 3. 将appDelegate 和 应用程序 建立关联(指定代 ...
- redis 学习 01(下载 学习资源)
1. windows 版 redis 下载地址 https://github.com/MSOpenTech/redis/releases 2. redis 实战源码 http://redisinact ...
- Ajax表单序列化后的数据格式转成Json发送给后台
<script> $(function(){ //表单转json函数 $.fn.serializeObject = function(){ var o = {}; var a = this ...
- C语言拾遗(一)
越来越体会到C语言的重要性,不管是在计算机底层的理解上,还是在算法数据结构上,所以遂决定重新拾起C语言,不定期更新一些知识点. 推荐博客:http://blog.csdn.net/itcastcpp ...
- 解决:Cannot get http://gerrit.googlesource.com/git-repo/clone.bundle
同步cm12.1初始化出现的问题: fatal: Cannot get https://gerrit.googlesource.com/git-repo/clone.bundle fatal: err ...
- 移动端meta
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scal ...
- 关于获取、设置css样式封装的函数入门版
<html> <head> <meta charset="UTF-8"> <title>CSS样式的获取和设置:简单版</ti ...
- a冲刺总结随笔
Alpha版本计划完成一般的便签功能: 预期项目 实际进展 首页瀑布流方块布局 1 按新旧顺序排列 1 增加记录 1 编辑文字信息 1 标记喜爱 0 删除文字信息 1 手动添加分类 0 反馈页面 ...
- windows下cmd记录MYSQL操作
我们在cmd下操作MYSQL,当需要复制某条命令的时候,需要右键标记,然后选取,然后......各种不方便! 有没有比较方便的方式,可以将我们的操作记录自动的实时保存下来,当我们需要操作的时候,可以高 ...