pandas常见函数详细使用
read_csv函数
常见参数:
header:
header=None 指明原始文件数据没有列索引,这样read_csv会自动加上列索引,除非你给定列索引的名字。
header=0 表示文件第0行(即第一行,索引从0开始)为列索引,这样加names会替换原来的列索引。如果没有传入names参数,默认行为是将文件第0行作为列索引。
sep : 字符串,分割符,默认值为‘,’
names : 列名数组,缺省值 None
df=pd.read_csv('data/testA/totalExposureLog.out', sep='\t',names=['id','request_timestamp','position','uid','aid','imp_ad_size','bid','pctr','quality_ecpm','totalEcpm']).sort_values(by='request_timestamp')
sort_values函数
DataFrame.sort_values(self, by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
默认按照行进行排序,by参数可以是数组

series values属性:
Return Series as ndarray or ndarray-like depending on the dtype.
统计groupby的key对应的记录数:
tmp = pd.DataFrame(train_df.groupby(['aid','request_day']).size()).reset_index()
tmp.columns=['aid','request_day','imp']
log=log.merge(tmp,on=['aid','request_day'],how='left')
groupby函数
pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作,根据一个或多个键(可以是函数、数组、Series或DataFrame列名)拆分pandas对象,继而计算分组摘要统计,如计数、平均值、标准差,或用户自定义函数。
ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings',
'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'],
'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2],
'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],
'Points':[876,789,863,673,741,812,756,788,694,701,804,690]}
df = pd.DataFrame(ipl_data)
1、根据series进行分组
按照Team进行分组,并计算Points列的平均值:我们可以先访问Points,并根据Team调用groupby:
grouped = df['Points'].groupby(df['Team'])
#等价于df['Points'].groupby(df.Team) 以及 df['Points'].groupby(df.Team.values)
print(grouped.groups)
grouped.mean()
输出:
{'Devils': Int64Index([2, 3], dtype='int64'), 'Kings': Int64Index([4, 6, 7], dtype='int64'), 'Riders': Int64Index([0, 1, 8, 11], dtype='int64'), 'Royals': Int64Index([9, 10], dtype='int64'), 'kings': Int64Index([5], dtype='int64')}
Team
Devils 768.000000
Kings 761.666667
Riders 762.250000
Royals 752.500000
kings 812.000000
Name: Points, dtype: float64
说明:数据(Series)根据分组键进行了聚合,产生了一组新的Series,其索引为Team列中的唯一值。grouped中的key为Team列中的值,value为series。
2、根据数组进行分组,实际上分组键可以是任何长度适当的数组(长度得等于行数),不一定得是series
grouped = df['Points'].groupby([df['Team'], df['Year']])
print(grouped.groups) age = np.array([2, 3, 3, 4, 5, 6, 7, 8, 8, 8, 8, 13])
grouped = df['Points'].groupby(age)
print(grouped.groups)
输出:
{('Devils', 2014): Int64Index([2], dtype='int64'), ('Devils', 2015): Int64Index([3], dtype='int64'), ('Kings', 2014): Int64Index([4], dtype='int64'), ('Kings', 2016): Int64Index([6], dtype='int64'), ('Kings', 2017): Int64Index([7], dtype='int64'), ('Riders', 2014): Int64Index([0], dtype='int64'), ('Riders', 2015): Int64Index([1], dtype='int64'), ('Riders', 2016): Int64Index([8], dtype='int64'), ('Riders', 2017): Int64Index([11], dtype='int64'), ('Royals', 2014): Int64Index([9], dtype='int64'), ('Royals', 2015): Int64Index([10], dtype='int64'), ('kings', 2015): Int64Index([5], dtype='int64')}
{2: Int64Index([0], dtype='int64'), 3: Int64Index([1, 2], dtype='int64'), 4: Int64Index([3], dtype='int64'), 5: Int64Index([4], dtype='int64'), 6: Int64Index([5], dtype='int64'), 7: Int64Index([6], dtype='int64'), 8: Int64Index([7, 8, 9, 10], dtype='int64'), 13: Int64Index([11], dtype='int64')}
3、将列名作为分组键
grouped = df.groupby('Team')
print(grouped.groups)
print(grouped.mean())
输出:
{'Devils': Int64Index([2, 3], dtype='int64'), 'Kings': Int64Index([4, 6, 7], dtype='int64'), 'Riders': Int64Index([0, 1, 8, 11], dtype='int64'), 'Royals': Int64Index([9, 10], dtype='int64'), 'kings': Int64Index([5], dtype='int64')}
Rank Year Points
Team
Devils 2.500000 2014.500000 768.000000
Kings 1.666667 2015.666667 761.666667
Riders 1.750000 2015.500000 762.250000
Royals 2.500000 2014.500000 752.500000
kings 4.000000 2015.000000 812.000000
1、对groupby结果进行迭代
grouped = df.groupby(['Team', 'Year'])
for (team, year), v in grouped:
print (("{0}--{1}").format(team, year))
print(v)
2、选取一个或多个列进行分组
对于由DataFrame产生的GroupBy对象,如果用一个(单个字符串)或一组(字符串数组)列名对其进行索引,就能实现选取部分列进行聚合的目的
# 下面两行等价
print(df.groupby('Team')['Points'].groups)
print(df['Points'].groupby(df['Team']).groups)
聚合函数:https://www.jianshu.com/p/4345878fb316
1、内置的聚合函数
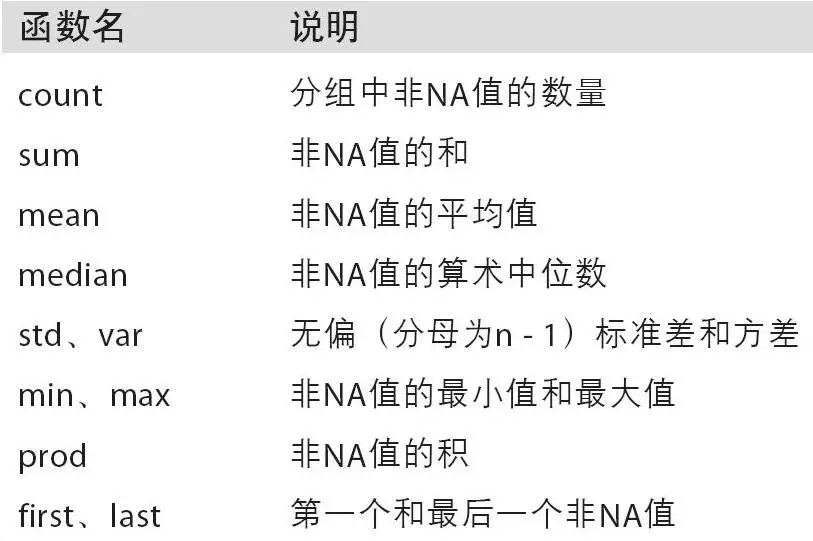
sum(), mean(), max(), min(), count(), size(), describe()
df.groupby('Team').sum()
df.groupby('Team').agg(np.sum) # 等价
df.groupby('Team').mean()
df.groupby('Team').agg(np.mean) # 等价
df.groupby('Team').max()
df.groupby('Team').min()
df.groupby('Team').count()
df.groupby('Team').size()
df.groupby('Team').describe()
2、自定义函数,传入agg方法中
def peak_range(df):
return df.max() - df.min()
for k, v in df.groupby('Team'):
print (k)
print (v) # v的type是DataFrame
df.groupby('Team').agg(peak_range) #传给peak_ranged的参数是分组后的DataFrame
df.groupby('Team').agg(lambda df: df.max() - df.min()) # 等价上面这行
使用agg后得到的series结果应用到原DataFrame中的某一列(即groupby的列),生成新的一列,这里的agg后的结果相当于一个字典:【重要】
agg1 = df['Points'].groupby(df.Team).agg(np.size)
print(agg1) # Series
print(agg1[df.Team])
print(agg1[df.Team].values)
输出结果:
Team
Devils 2
Kings 3
Riders 4
Royals 2
kings 1
Name: Points, dtype: int64
Team
Riders 4
Riders 4
Devils 2
Devils 2
Kings 3
kings 1
Kings 3
Kings 3
Riders 4
Royals 2
Royals 2
Riders 4
Name: Points, dtype: int64
[4 4 2 2 3 1 3 3 4 2 2 4]
总结:通过groupby和agg函数生成新的特征,eg:统计每个user点击的广告次数 => 统计类特征
def get_agg(group_by, value, func):
g1 = pd.Series(value).groupby(group_by)
agg1 = g1.aggregate(func)
#print agg1
r1 = agg1[group_by].values
return r1 t0['cnt_dev_ip'] = get_agg(t0.device_ip.values, t0.id, np.size)
numpy.argsort函数
-返回的是数组值从小到大的索引值,若传入的是series,返回的也是series, index为从0开始的数字,value为数组值从小到大的索引值。
总结:针对某类特征统计每个特征值的数目,eg:统计每个user出现的次数 => 统计类特征
def my_cnt(group_by):
_ts = time.time()
_ord = np.argsort(group_by)
print time.time() - _ts
_ts = time.time()
#_cs1 = _ones.groupby(group_by[_ord]).cumsum().values
_cs1 = np.zeros(group_by.size)
_prev_grp = '___'
runnting_cnt = 0
for i in xrange(1, group_by.size):
i0 = _ord[i]
if _prev_grp == group_by[i0]:
running_cnt += 1
else:
running_cnt = 1
_prev_grp = group_by[i0]
if i == group_by.size - 1 or group_by[i0] != group_by[_ord[i+1]]:
j = i
while True:
j0 = _ord[j]
_cs1[j0] = running_cnt
if j == 0 or group_by[_ord[j-1]] != group_by[j0]:
break
j -= 1 print time.time() - _ts
return _cs1
numpy.lexsort函数
-用于对多个序列进行排序, 会优先使用后面列排序,后面相同才使用前面的列排序,返回的是数组值从小到大的索引值
a = np.array([1,2,3,4,5])
b = np.array([40,40,30,20,10])
c = np.lexsort((a,b))
print(c)
print(list(zip(a[c],b[c])))
输出:
[4 3 2 0 1]
[(5, 10), (4, 20), (3, 30), (1, 40), (2, 40)]
总结:排序特征,eg:对每个usr点击过的广告按照时间进行排序
# 关键是获取原始输入中的每个值在排序后的结果中的位置
def my_grp_idx(group_by, order_by):
_ts = time.time()
_ord = np.lexsort((order_by, group_by)) # 先根据groupby排序,再根据orderby排序。index是0,1..., value是groupby和orderby的索引
print time.time() - _ts
_ts = time.time()
_ones = pd.Series(np.ones(group_by.size))
print time.time() - _ts
_ts = time.time()
_cs1 = np.zeros(group_by.size) # 记录排序
_prev_grp = '___'
for i in xrange(1, group_by.size): # 此处应该从0开始
i0 = _ord[i]
if _prev_grp == group_by[i0]:
_cs1[i] = _cs1[i - 1] + 1
else:
_cs1[i] = 1
_prev_grp = group_by[i0]
print time.time() - _ts
_ts = time.time()
# 此处_cs1的value对应的index顺序是_ord的value顺序(4,3,2,0,1)即排序后的顺序,如何改为对应的index是原始输入的index(0,1,2...) org_idx = np.zeros(group_by.size, dtype=np.int)
print time.time() - _ts
_ts = time.time()
org_idx[_ord] = np.asarray(xrange(group_by.size)) # org_idx的含义:_ord数组的value在_ord数组中的index,即原始输入的index在_ord数组中的index
# org_idx的value表示的是原始输入该位置的值在_ord中的位置
print time.time() - _ts
_ts = time.time() return _cs1[org_idx]
order_by = np.array([1,2,3,4,5])
group_by = np.array([40,40,30,20,10])
res = my_grp_idx(group_by, order_by)
总结:历史点击率特征
1、生成组合特征,并one-hot化
df['Team-Year'] = pd.Series(np.add(df.Team.values, df.Year.astype('string').values)).astype('category').values.codes
2、numpy.logical_and函数
filtered = np.logical_and(df.Year.values > 2015, df.Year.values <=2017)
print(filtered) # 输出: [False False False False False False True True True False False True]
print(df.iloc[filtered, :])
3、生成历史点击率特征calc_exptv:
df['_key1'] = df[vn].astype('category').values.codes
df_yt = df.ix[filter_train, ['_key1', vn_y]]
# 聚合后求历史ctr
grp1 = df_yt.groupby(['_key1'])
sum1 = grp1[vn_y].aggregate(np.sum)
cnt1 = grp1[vn_y].aggregate(np.size)
vn_sum = 'sum_' + vn
vn_cnt = 'cnt_' + vn
v_codes = df.ix[~filter_train, '_key1']
# 相当于对v_codes进行查字典,聚合后的结果作为字典
_sum = sum1[v_codes].values
_cnt = cnt1[v_codes].values
_cnt[np.isnan(_sum)] = 0
_sum[np.isnan(_sum)] = 0
r = {}
# mean0是某维度特征的平均点击率,用于平滑
r['exp'] = (_sum + cred_k * mean0)/(_cnt + cred_k)
r['cnt'] = _cnt
return r
set、numpy.unique函数
比较两个集合的差异:
set1 = set(np.unique(df.loc[df.Year == 2014,'Team'].values))
print(set1)
set2 = set(np.unique(df.loc[df.Year == 2015,'Team'].values))
print(set2)
set2_1 = set2 - set1
print(set2_1)
print(len(set2_1) * 1.0 / len(set2))
总结:calcDualKey => 统计用户下一天的点击率,感觉没有意义啊
总结:my_grp_cnt => 统计某类特征下另外一类特征的特征值的数目,eg:统计每个user安装的app的数量 => 统计类特征
def my_grp_cnt(group_by, count_by):
_ts = time.time()
_ord = np.lexsort((count_by, group_by))
print time.time() - _ts
_ts = time.time()
_ones = pd.Series(np.ones(group_by.size))
print time.time() - _ts
_ts = time.time()
#_cs1 = _ones.groupby(group_by[_ord]).cumsum().values
_cs1 = np.zeros(group_by.size)
_prev_grp = '___'
runnting_cnt = 0
for i in xrange(1, group_by.size):
i0 = _ord[i]
if _prev_grp == group_by[i0]:
if count_by[_ord[i-1]] != count_by[i0]:
running_cnt += 1
else:
running_cnt = 1
_prev_grp = group_by[i0]
if i == group_by.size - 1 or group_by[i0] != group_by[_ord[i+1]]:
j = i
while True:
j0 = _ord[j]
_cs1[j0] = running_cnt
if j == 0 or group_by[_ord[j-1]] != group_by[j0]:
break
j -= 1 print time.time() - _ts
if True:
return _cs1
else:
_ts = time.time() org_idx = np.zeros(group_by.size, dtype=np.int)
print time.time() - _ts
_ts = time.time()
org_idx[_ord] = np.asarray(xrange(group_by.size))
print time.time() - _ts
_ts = time.time() return _cs1[org_idx]
总结:信息泄漏,eg:分别统计user在上个小时,当前小时,下个小时点击的广告数 => 统计类特征
def cntDualKey(df, vn, vn2, key_src, key_tgt, fill_na=False):
print "build src key"
_key_src = np.add(df[key_src].astype('string').values, df[vn].astype('string').values)
print "build tgt key"
_key_tgt = np.add(df[key_tgt].astype('string').values, df[vn].astype('string').values)
if vn2 is not None:
_key_src = np.add(_key_src, df[vn2].astype('string').values)
_key_tgt = np.add(_key_tgt, df[vn2].astype('string').values)
print "aggreate by src key"
grp1 = df.groupby(_key_src)
cnt1 = grp1[vn].aggregate(np.size)
print "map to tgt key"
vn_sum = 'sum_' + vn + '_' + key_src + '_' + key_tgt
_cnt = cnt1[_key_tgt].values
if fill_na is not None:
print "fill in na"
_cnt[np.isnan(_cnt)] = fill_na
vn_cnt_tgt = 'cnt_' + vn + '_' + key_tgt
if vn2 is not None:
vn_cnt_tgt += '_' + vn2
df[vn_cnt_tgt] = _cnt
cntDualKey(t0, 'device_ip', None, 'day_hour', 'day_hour_prev', fill_na=0)
cntDualKey(t0, 'device_ip', None, 'day_hour', 'day_hour', fill_na=0)
cntDualKey(t0, 'device_ip', None, 'day_hour', 'day_hour_next', fill_na=0)
pandas常见函数详细使用的更多相关文章
- Pandas使用详细教程(个人自我总结版)
Pandas 是我最喜爱的库之一.通过带有标签的列和索引,Pandas 使我们可以以一种所有人都能理解的方式来处理数据.它可以让我们毫不费力地从诸如 csv 类型的文件中导入数据.我们可以用它快速地对 ...
- 机器学习(4):数据分析的工具-pandas的使用
前面几节说一些沉闷的概念,你若看了估计已经心生厌倦,我也是.所以,找到了一个理由来说一个有兴趣的话题,就是数据分析.是什么理由呢?就是,机器学习的处理过程中,数据分析是经常出现的操作.就算机器对大量样 ...
- Python爬虫简单实现CSDN博客文章标题列表
Python爬虫简单实现CSDN博客文章标题列表 操作步骤: 分析接口,怎么获取数据? 模拟接口,尝试提取数据 封装接口函数,实现函数调用. 1.分析接口 打开Chrome浏览器,开启开发者工具(F1 ...
- Pyinstaller 中 pandas出错问题的解决(详细)
环境配置 pip install pyinstaller pyinstaller中的参数 -F 表示生成单个可执行文件 -c 显示命令行窗口,一般一开始的时候使用,如果没有错误,那就使用-w命令 -w ...
- pandas模块(很详细归类),pd.concat(后续补充)
6.12自我总结 一.pandas模块 import pandas as pd约定俗称为pd 1.模块官方文档地址 https://pandas.pydata.org/pandas-docs/stab ...
- Spark与Pandas中DataFrame对比(详细)
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- Python学习教程:Pandas中第二好用的函数
从网上看到一篇好的文章是关于如何学习python数据分析的迫不及待想要分享给大家,大家也可以点链接看原博客.希望对大家的学习有帮助. 本次的Python学习教程是关于Python数据分析实战基础相关内 ...
- 用scikit-learn和pandas学习线性回归
对于想深入了解线性回归的童鞋,这里给出一个完整的例子,详细学完这个例子,对用scikit-learn来运行线性回归,评估模型不会有什么问题了. 1. 获取数据,定义问题 没有数据,当然没法研究机器学习 ...
- 【原】十分钟搞定pandas
http://www.cnblogs.com/chaosimple/p/4153083.html 本文是对pandas官方网站上<10 Minutes to pandas>的一个简单的翻译 ...
随机推荐
- 缓存淘汰算法之FIFO
前段时间去网易面试,被这个问题卡住,先做总结如下: 常用缓存淘汰算法 FIFO类:First In First Out,先进先出.判断被存储的时间,离目前最远的数据优先被淘汰. LRU类:Least ...
- 学习 JSP:第二步 创建一个JSP Web Project
接上文 学习 JSP:第一步Eclipse+Tomcat+jre(配置环境) [创建新工程](Dynamic Web Project) 1.选择 "File-->New-->Dy ...
- 大杂烩 Classpath / Build path / Debug关联源码 / JDK&JRE区别
Classpath的理解及其使用方式 原文地址:http://blog.csdn.net/wk1134314305/article/details/77940147?from=bdhd_site 摘要 ...
- 表单编码 appliation/x-www-form-urlencoded 与 multipart/form-data 的区别
当表单使用POST方法时,表单数据提交到服务器端之前有两种编码类型可供选择.默认编码类型为 application/x-www-form-urlencoded,此时所有非字母数字类型的字符都需要转换为 ...
- element-ui 的input组件 @keyup.enter事件的添加办法
<el-input placeholder="请输入密码" type="password" @keyup.enter.native="login ...
- UVa1476 Error Curves
画出函数图像后,发现是一个类似V字型的图. 可以用三分法找图像最低点 WA了一串,之后发现是读入优化迷之被卡. /*by SilverN*/ #include<iostream> #inc ...
- vue2 vuex 简单入门基础
1.vuex中文文档 https://vuex.vuejs.org/zh-cn/api.html 2.我理解vuex 应用观察者模式 设置了全局的状态 state 状态变化即通知更新全局state 3 ...
- 学习javascript设计模式之单例模式
1.单例模式的核心是确保只有一个实例,并提供全局访问. 2.惰性单例 指的是在需要的时候才创建对象实例. 如在页面中创建唯一div 普通做法 var createDiv = (function(){ ...
- 从Java源码到Java字节码
Java最主流的源码编译器,javac,基本上不对代码做优化,只会做少量由Java语言规范要求或推荐的优化:也不做任何混淆,包括名字混淆或控制流混淆这些都不做.这使得javac生成的代码能很好的维持与 ...
- 关于Red5整合springMVC提示scope not found 的错误
https://www.cnblogs.com/qgc88: