爬虫之scrapy工作流程
Scrapy是什么?
scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
异步与非阻塞的区别:异步:调用在发出之后,这个调用就直接返回,不管有无结果。
非阻塞:关注的是程序在等待调用结果(消息,返回值)时的状态,指在不能立刻得到结果之前,该调用不会阻塞当前线程。

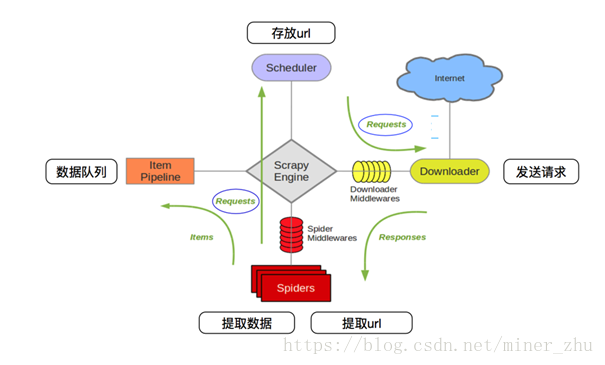
scrapy详细工作流程:
1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。
2.Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)交给Downloader。
3.Downloader向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4.Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。
5.提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
Scrapy主要包括了以下组件:
- 引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
爬虫之scrapy工作流程的更多相关文章
- scrapy 工作流程
Scrapy的整个数据处理流程由Scrapy引擎进行控制,其主要的运行方式为: 引擎打开一个域名,蜘蛛处理这个域名,然后获取第一个待爬取的URL. 引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求 ...
- scrapy工作流程
整个scrapy流程,我们可以用去超市取货的过程来比喻一下 两个采购员小王和小李开着采购车,来到一个大型商场采购公司月饼.到了商场之后,小李(spider)来到商场前台,找到服务台小花(引擎)并对她说 ...
- Scrapy项目结构分析和工作流程
新建的空Scrapy项目: spiders目录: 负责存放继承自scrapy的爬虫类.里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或 ...
- Linux企业级项目实践之网络爬虫(2)——网络爬虫的结构与工作流程
网络爬虫是捜索引擎抓取系统的重要组成部分.爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份. 一个通用的网络爬虫的框架如图所示:
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- scrapy核心组件工作流程和post请求
一 . 五大核心组件的工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返 ...
- Scrapy中的核心工作流程以及POST请求
五大核心组件工作流程 post请求发送 递归爬取 五大核心组件工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, ...
- 一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助. 1.Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且 ...
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
随机推荐
- Vue --6 router进阶、单页面应用(SPA)带来的问题
一.Vue-router进阶 回顾学过的vue-router,并参考官方文档学习嵌套路由等路由相关知识. 二.单页面应用(SPA)带来的问题 1.虽然单页面应用有优点,但是,如果后端不做服务器渲染(h ...
- beanshell解析json(从简单到复杂)
使用beanshell 解析单层Json: Json 数据如下: { "status":200, "code": 0, "message": ...
- java实现access数据上传
一. --springMvc实现上传 https://blog.csdn.net/qian_ch/article/details/69258465 --转换成spring64位上传 https://b ...
- DotNetAnywhere
DotNetAnywhere:可供选择的 .NET 运行时 原文 : DotNetAnywhere: An Alternative .NET Runtime作者 : Matt Warren译者 : ...
- python 1 学习廖雪峰博客
输出 用print()在括号中加上字符串,就可以向屏幕上输出指定的文字.比如输出'hello, world',用代码实现如下: >>> print('hello, world') p ...
- wpf ComboBox的SelectionBoxItem相关依赖属性
以前没有注意SelectionBoxItem相关依赖属性,这几天看wpf源码 特意研究了一番 <Style x:Key="ComboBoxStyle1" TargetType ...
- 用于<挣值管理>的各种指标计算
PV(Planning Value) 含义:计划价值,截至到某个时间计划工作经批准的成本预算. 公式:PV=计划工作数X计划单价. BAC 含义:完工预算,截至到完工时间计划工作经批准的成本预算,即完 ...
- 开源项目android-uitableview介绍
在iOS应用中,UITableView应该是使用率最高的视图之一了.iPod.时钟.日历.备忘录.Mail.天气.照片.电话.短信. Safari.App Store.iTunes.Game Cent ...
- 初识Adapter
首先得了解Adapter层级关系: 示例,将user对象适配到textview public class User { private String userName; private String ...
- freebsd快速删除磁盘数据
At the start, mark all system disks as empty. Repeat the following command for each hard drive: dd i ...