centos6.6安装hadoop-2.5.0(二、伪分布式部署)
操作系统:centos6.6(一台服务器)
环境:selinux disabled;iptables off;java 1.8.0_131
安装包:hadoop-2.5.0.tar.gz
伪分布式环境(适用于学习环境)
安装步骤:
1、解压安装包
# tar zxvf hadoop-2.5.0.tar.gz -C /data/hadoop/hadoopfake/
2、配置hadoop参数
1)设置环境变量 #vim /etc/profile

追加下面两行:
export HADOOP_HOME=/data/hadoop/hadoopfake/hadoop-2.5.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#source /etc/profile 使环境变量生效
#echo $HADOOP_HOME 验证hadoop参数

2)设置JAVA_HOME参数
分别修改/data/hadoop/hadoopfake/hadoop-2.5.0/etc/hadoop/下的hadoop-env.sh、mapred-env.sh、yarn-env.sh文件的JAVA_HOME参数
(如果JAVA_HOME在/etc/expofile或者~/.bashrc设置了环境变量export JAVA_HOME,那以上文件不用修改JAVA_HOME的参数)
3)配置core-site.xml文件
#vim /data/hadoop/hadoopfake/hadoop-2.5.0/etc/hadoop/core-site.xml
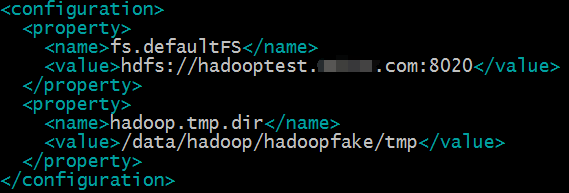
fs.defaultFS参数设置的是hdfs的地址;
hadoop.tmp.dir设置的是hadoop的临时目录,例如namenode的数据都会默认存放在这个目录;如果不配置这个参数,namenode数据会默认放在/tmp/hadoop*目录下,操作系统重启这个目录的所有数据都会清空,namenode的元数据会丢失,所以最好新建目录存放namenode的元数据。
4)配置hdfs-site.xml文件
#vim /data/hadoop/hadoopfake/hadoop-2.5.0/etc/hadoop/hdfs-site.xml

dfs.replication配置的是HDFS存储时的备份数量,伪分布式环境只有一个节点,所以设置为1就可以。
3、格式化、启动HDFS
#/data/hadoop/hadoopfake/hadoop-2.5.0/bin/hdfs namenode -format 格式化hdfs
#ll /data/hadoop/hadoopfake/tmp/dfs/name/current 查看格式化后的目录

格式化是对分布式文件系统HDFS中的datanode进行分块,统计所有分块后的初始元数据存储在namenode中
格式化后hadoop.tmp.dir下面有dfs目录则格式化成功
fsimage是namenode元数据在内存满了后,持久化保存到文件
fsimage*md5是校验文件,用于校验fsimage的完整性
seen_txid是hadoop的版本
VERSION:namespaceID是namenode的唯一ID
clusterID是集群的ID,namenode和datanode集群ID一致时表明是一个集群
4、启动namenode
#/data/hadoop/hadoopfake/hadoop-2.5.0/sbin/hadoop-daemon.sh start namenode

5、启动datanode
#/data/hadoop/hadoopfake/hadoop-2.5.0/sbin/hadoop-daemon.sh start datanode

6、启动secondarynamenode
#/data/hadoop/hadoopfake/hadoop-2.5.0/sbin/hadoop-daemon.sh start secondarynamenode

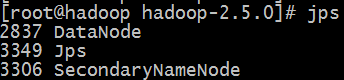
7、使用jps命令查看node是否启动
#jps
8、测试创建目录,上传文件
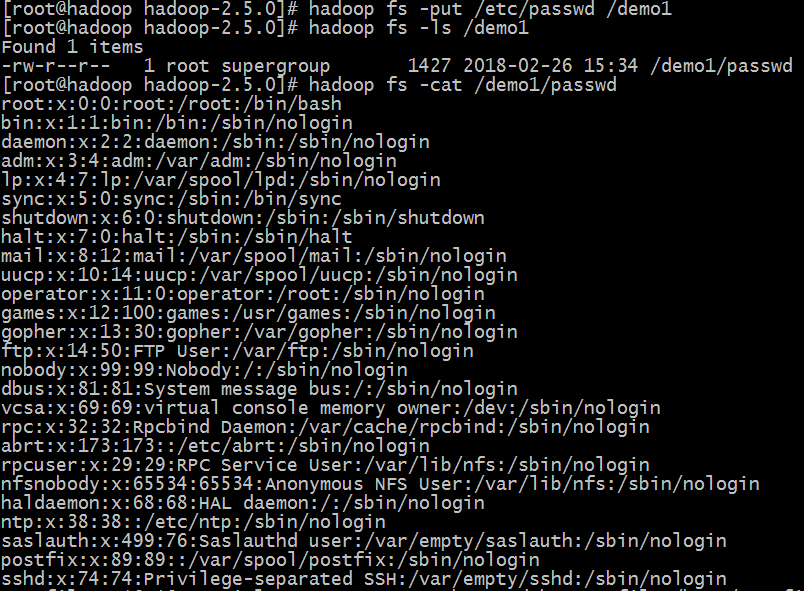
#hadoop fs -mkdir /demo1

#hadoop fs -put /etc/passwd /demo1
#hadoop fs -cat /demo1/passwd 读取文件内容
#hadoop fs -get /demo1/passwd

9、配置启动YARN
1)配置mapred-site.xml
#cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
#vim etc/hadoop/mapred-site.xml
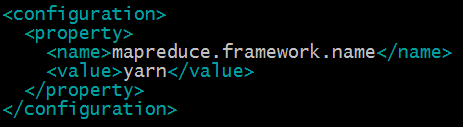
指定mapreduce运行在yarn框架上
2)配置yarn-site.xml
#vim etc/hadoop/yarn-site.xml
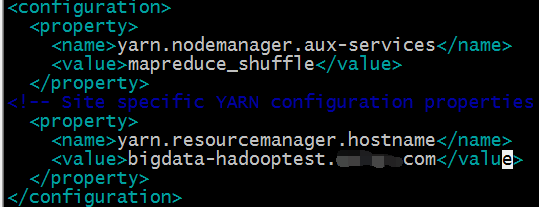
yarn.nodemanager.aux-services配置了yarn的默认混洗方式,选择为mapreduce的默认混洗算法
yarn.resourcemanager.hostname指定了Resourcemanager运行在哪个节点上
3)启动Resourcemanager
#vim /etc/hosts

#/sbin/yarn-daemon.sh start resourcemanager

#jps

4)启动nodemanager
#/sbin/yarn-daemon.sh start nodemanager

#jps
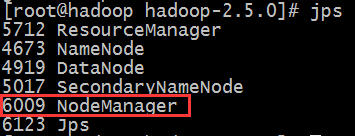
5)web界面
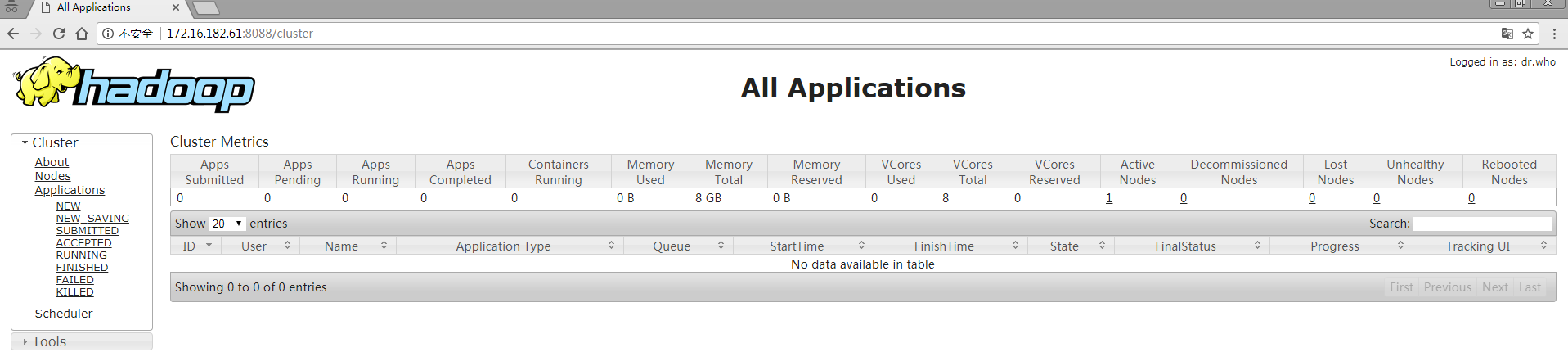
10、运行mapreduce job
1)创建输入目录
#hadoop fs -mkdir -p /wordcountdemo/input

2)创建文件并上传到/wordcountdemo/input目录中
#cat wc.input
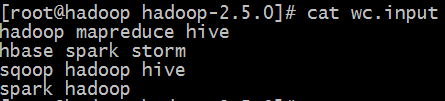
#hadoop fs -put wc.input /wordcountdemo/input/

3)运行wordcount mapreduce job
#bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-example-2.5.0.jar wordcount /wordcountdemo/input /wordcountdemo/output
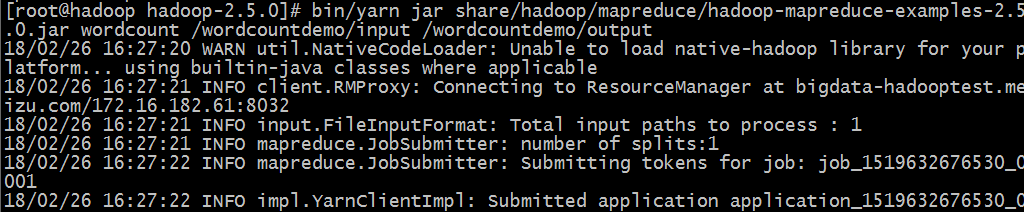
#hadoop fs -ls /wordcountdemo/output 查看输出结果

_SUCCESS文件是个空文件,只是来说明job执行成功
part-r-00000是结果文件,-r-说明这个文件是reduce阶段产生的结果,如没有reduce则应该是-m-
#hadoop fs -cat /wordcountdemo/output/part-r-00000 查看输出文件内容

11、停止hadoop
#sbin/hadoop-daemon.sh stop namenode
#sbin/hadoop-daemon.sh stop datanode
#sbin/hadoop-daemon.sh stop secondarynode
#sbin/yarn-daemon.sh stop resourcemanager
#sbin/yarn-daemon.sh stop nodemanager
12、开启历史服务
开启历史服务可在web界面上查看yarn上执行的job情况等信息
#sbin/mr-jobhistory-daemon.sh start historyserver
正在执行中的任务


centos6.6安装hadoop-2.5.0(二、伪分布式部署)的更多相关文章
- Ubuntu 14.04 LTS 安装 spark 1.6.0 (伪分布式)-26号开始
需要下载的软件: 1.hadoop-2.6.4.tar.gz 下载网址:http://hadoop.apache.org/releases.html 2.scala-2.11.7.tgz 下载网址:h ...
- Hadoop三种安装模式:单机模式,伪分布式,真正分布式
Hadoop三种安装模式:单机模式,伪分布式,真正分布式 一 单机模式standalone单 机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守 ...
- 超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群
超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群 ps:本文的步骤已自实现过一遍,在正文部分避开了旧版教程在新版使用导致出错的内容,因此版本一致的情况下照搬执行基本不会有大错误. ...
- CentOS7.0分布式安装HADOOP 2.6.0笔记-转载的
三台虚拟机,IP地址通过路由器静态DHCP分配 (这样就无需设置host了). 三台机器信息如下 - 1. hadoop-a: 192.168.0.20 #master 2. ha ...
- 安装hadoop 2.2.0
安装环境为 CentOS 64位系统, 大概分下面几个步奏, 0. 安装JDK1. 配置SSH2. 配置/etc/hosts3. 拷贝hadoop包到没台机器上4. 修改hadoop配置文件5. 关闭 ...
- hadoop 2.6.0 伪分布式部署安装遇到的问题
之前读到了一篇关于配置安装hadoop的博文(地址:http://www.powerxing.com/install-hadoop/)能正确安装和运行,但是在网页进行Jobtracker监控时,输入l ...
- Ubuntu 13.10下Hadoop 2.2 安装、配置、编译(伪分布式)
1.安装JDK.在此不做解说,上篇博文里已介绍过.http://www.cnblogs.com/lifeinsmile/p/3578677.html 2.配置ssh. ssh服务,用于管理远程Hado ...
- Hadoop1.0.4伪分布式安装
前言: 目前,学习hadoop的目的是想配合其它两个开源软件Hbase(一种NoSQL数据库)和Nutch(开源版的搜索引擎)来搭建一个知识问答系统,Nutch从指定网站爬取数据存储在Hbase数据库 ...
- hadoop2.2.0 单机伪分布式(含64位hadoop编译) 及 eclipse hadoop开发环境搭建
hadoop中文镜像地址:http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.2.0/ 第一步,下载 wget 'http://archive ...
随机推荐
- J - Jesus Is Here HDU - 5459 (递推)
大意: 定义$f_1="c",f_2="ff",f_n=f_{n-2}+f_{n-1}$, 求所有"cff"的间距和. 记录c的个数, 总长 ...
- 卸载WPS后怎么WORD的图标还是WPS
在电脑中选择使用Microsoft Office并将之前安装的WPS Office办公软件卸载了.但是卸载之后发现电脑系统中的Word.Excel等文件无法正常显示图标.在这样的情况下,我们应该如何解 ...
- 安卓——animotion
在 layout下建立文件夹 animator写入动画文件xml <?xml version="1.0" encoding="utf-8"?> &l ...
- linux创建定时任务,定时执行sql
终于弄清楚一个问题了.linux创建定时任务,定时执行sql,其中分为两个case. case-1 sql语句较少,因此直接在 shell脚本中 写sql语句.如下: [oracle@Oracle11 ...
- windows 系统分布式版本控制 git 使用学习
1. 在 Windows 上安装 Git 在Windows上使用Git,可以从Git官网直接下载安装程序,(网速慢的同学请移步国内镜像),然后按默认选项安装即可. 安装完成后,在开始菜单里找到“Git ...
- python爬虫基本原理及入门
爬虫:请求目标网站并获得数据的程序 爬虫的基本步骤: 使用python自带的urllib库请求百度: import urllib.request response = urllib.request.u ...
- H5 页面在微信端的分享
微信分享,咋一看好像很复杂,实则非常简单.只需要调用微信官方出的微信jssdk,加上些许配置,就可以实现h5页面在微信上的分享,官方文档地址为: https://mp.weixin.qq.com/wi ...
- C++三大特性 封装 继承 多态
C++ 三大特性 封装,继承,多态 封装 定义:封装就是将抽象得到的数据和行为相结合,形成一个有机的整体,也就是将数据与操作数据的源代码进行有机的结合,形成类,其中数据和函数都是类的成员,目的在于将对 ...
- dubbo源码分析(一)-从xml到我们认识的Java对象
项目中用的dubbo的挺多的,然后随着自己对dubbo的慢慢深入,自己也希望能够了解dubbo的底层实现,这半年来一直在看dubbo的源码,有点断断续续的,于是准备写一个dubbo源码系列的分析文章, ...
- Struts 2 初步入门(一)
搭建Struts 2环境步骤 下载jar包----->创建web项目---->创建并完善相关配置文件---->创建action并测试启动 下载jar包访问网站:http://stru ...