lucene 全文检索工具的介绍
Lucene:全文检索工具:这是一种思想,使用的是C语言写出来的
1.Lucene就是apache下的一个全文检索工具,一堆的jar包,我们可以使用lucene做一个谷歌和百度一样的搜索引擎系统
2.Lucene是由Doug Cutting 2000年开发出的第一个版本,后捐给apache基金会,doug Cutting是Lucene , Hadoop(大数据领域)等项目的发起人
3.常用的搜索:solr,ES
常见的应用场景:
百度,谷歌,必应
站内的搜索:京东,淘宝,站内贴吧
为什么学习Luene?
原来的方式实现搜索功能,我们的搜索流程为:
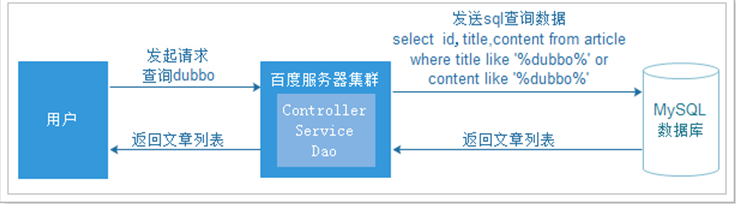
上图就是原始搜索引擎技术,如果用户比较少而且数据库的数据量比较小,那么这种方式实现搜索功能在企业中还是比较常见的.
但是数据量过多时,数据库的压力就会变得更大,查询速度就会变得非常慢,我们需要使用更好的解决方案来分担数据库的压力.
解决方法,就是使用Lucene
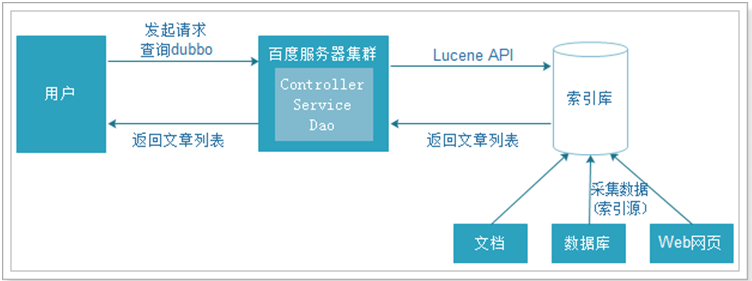
为了解决数据库压力和速度的问题,我们的数据库就会变成索引库,我们使用Lucene的API的来操作服务器上的索引库,这样完全和数据库进行了分离.
数据库的查询方法:
常见的算法:
1.顺序扫描法:从上到下,从左到右,一次匹配,直到找到为止
优点:准确率高
缺点:效率低
举例:数据库like查询
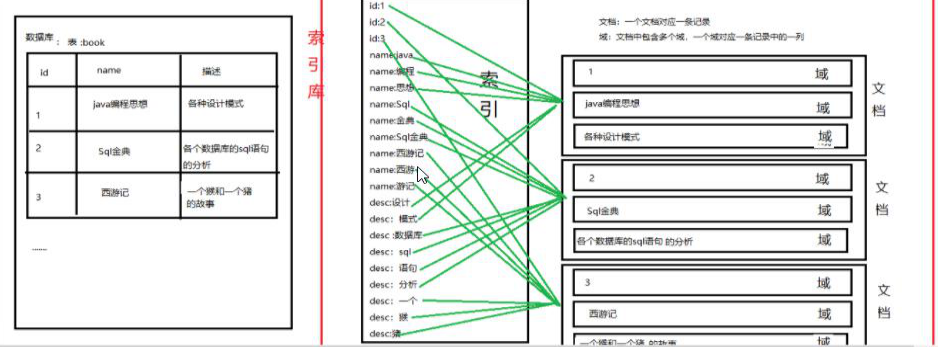
2.倒排索引算法(全文检索算法)
描述:首先把所有的数据查询出来,进行切分词,用分词组成索引,然后把内容存储到文档对象中,索引和文档列表组成索引库,在查询时,先找到索引,索引与文档之间有联系,通过索引快速的找到文档对象,这就是倒排索引算法.
优点:效率高.
缺点:以空间换时间
举例子:新华词典(偏旁部首,页码)
lucene的原理:
Lucene介绍:
什么是全文索引?
计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就会根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式.
什么是Lucene?
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但是它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和搜索引擎,部分文本分析引擎(英文和德文两种西方语言)
Lucene的目的是为软件开发人员提供了一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是一次为基础建立起来完整的全文检索引擎.
目前已经有很多应用程序的搜索功能是基于Lucene的,比如Eclipse的帮助系统的搜索功能,Lucene能够为文本类型的数据建立索引,所以你只要能把你要索引的数据格式转化的文本的,Lucene就能对你的文档进行索引和搜索.比如你要对一些HTML文档,PDF文档进行索引的话,你就首先需要吧HTML文档和PDF文档转化为文本格式的,然后将转化后的内容交给Lucene进行索引,然后把创建好的索引文件保存到磁盘或者内存中,最后根据用户输入的查询条件在索引文件上进行查询.不指定要索引的文档的格式也使Lucene能够几乎适用于所有的搜索应用程序.
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供.
Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻,在java开发环境里Lucene是一个成熟的免费开放源代码工具.
Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品
Lucene与搜索引擎的区别?
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统,包括建立索引.处理查询返回结果集,增加索引
优化索引结构等功能.例如百度,eclipse帮助搜索,淘宝网商品搜索
搜索引擎是全文检索技术最主要的一个应用,例如百度.搜索引擎起源于传统的信息全文检索理论,即计算机程序通过扫描每一篇文章中的每一个词,建立以词为单位的倒排文件,检索程序根据检索词在每一篇文章更中出现的频率和每一个检索词在一篇文章中出现的概率,对包含这些检索词的文章进行排序,最后输出排序的结果.全文检索技术是搜索引擎的核心支撑技术.
Lucene和搜索引擎不同,Lucene是一套用java或其他语言写的全文检索的工具包,为应用程序提供了很多个api接口去调用,可以简单理解为是一套实现全文检索的类库,搜索引擎是一个全文检索系统,它是一个单独运行的软件系统
Lucene官网
网址:http://lucene.apache.org/
Lucene全文检索的流程
索引和搜索流程图
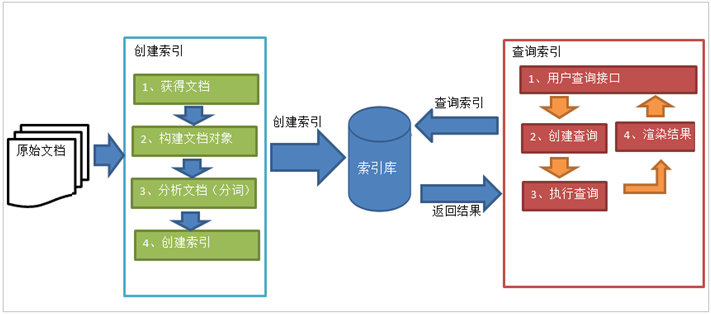
1.绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容-->获取文档-->创建文档-->分析文档-->索引文档.
2.红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面-->创建查询-->执行搜索,从索引库搜索-->渲染搜索结果.
索引流程
对文档索引的过程,将用户要搜索的文档内容进行索引,索引存储在索引库(index)中
原始内容
原始内容是指索引和搜索的内容
原始内容包括互联网上的页面.数据库中的数据,磁盘上的文件等.
获得文档(采集数据)
从互联网上.数据库.文件系统中等获取需要搜索的原始信息,这个过程就是信息采集,采集数据的目的是为了对原始内容更进行索引.
采集数据分类:
1.对于互联网上个网页,可以使用工具将晚归抓取到本地生成html文件
2.数据库中的数据,可以直接连接数据库读取表中的数据
3.文件系统给中的某个文件,可以通过I/O操作读取文件的内容.
在Internet上采集信息的软件通常称为爬虫或者蜘蛛,也称为网络机器人,爬虫访问互联网上的每一个网页,将获取到的网页内容存储起来.
创建文档
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容.
这里我们可以将磁盘上的一个文件当成一个document,Document中包括一些Field,如下图:

注意:每个Document可以有多个Fiele,不同的Document可以有不同的Field,同一个Docuemnt可以有相同的Field(域名和域值都相同)
分析文档
将原始内容能够创建为包含域(Field)的文档(Docuemnt),需要再对域中的内容进行分析,分析成为一个一个的单词.
比如下边的文档经过分析如下:
原文档内容:
Lucene is a java full-text search engine , Lucene is not a complete application,but rather a code library and API that can
easily be used to add search capabilities to applications.
分析后得到的词:
lucene、java、full、search、engine。。。。
索引文档
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现之搜索被索引的语汇单元从而找到document(文档)
创建多音是对语汇单元索引,通过词语找文档,这种索引的结构叫做倒排索引结构,
倒排索引结构是根据内容(词汇)找文档,如下图:
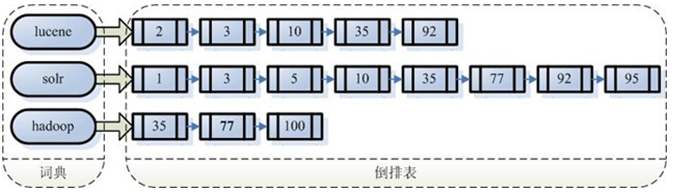
倒排索引结构也叫做反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大.
搜索流程
搜索:就是用户输入关键字,从索引中进行搜索的过程,根据关键字搜索索引,根据索引找到对应的文档,从而找到要搜索的内容.
用户:就是使用搜索的角色,用户可以是自然人,也可以是远程调用的程序.
用户搜索界面:全文检索系统提供用户搜索的界面供用户提交搜索的关键字,搜索完成展示搜索结果.如下图:
Lucene不提供制作用户搜索界面的功能,需要根据自己的需求开发搜索界面.
创建查询
用户输入查询关键字执行搜索之前需要先构建一个查询对象,查询对象中可以制定查询要查询关键字,要搜索的Field文档域等,查询对象会生成具体的查询语法.比如:
name:lucene表示要搜索name这个field域中,内容为"lucene"的文档.
desc:lucene AND desc:java 表示要搜索即包括关键字"lucene"包括"java"的文档.
执行搜索
1.根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所连接的文档链表.
例如搜索语法为"desc:lucene AND desc:java" 表示搜索出的文档中既要包括lucene也要包括java

2.由于是AND,所以要对包含lucene或者java词语的链表进行交集,得到文档链表应该包括每一个搜索词语.
3.获取文档中的field域数据.
渲染结果
以一个友好的界面将查询结果展示给用户,用户根据搜索结果找自己想要的信息,为了帮助用户很快找到自己的结果,提供了很多展示的效果,比如搜索结果中将关键字高亮显示,百度提供的快照等.

备注:(名词解释)
1.切分词:把内容中不重要的数据删除,比如:的,得,地,啊,嗯,哦,哎,a,an,the.......
2.索引:目录(把分词组成了一个目录)
3.文档:是lucene中的一个对象,一个文档可以存储数据库的一条记录
4.索引库:对应电脑上的一个文件夹,保存索引和文档对象.
5.域对象的选择:
是否分词:是否有意义,如果分词后有意义,就分词,无意义不分词
是:有意义
举例:name,price,description
否:无意义
举例:id,pic
是否索引:索引的目的,就是为了查询.
是:需要使用它去查询
举例:id,name,pic,description
否:不需要使用它进行查询
举例:pic,
是否存储:是否要存储到索引库中,需要在查询页展示的数据则需要存储.描述域一般内容比较多,一般不存储,如果需要描述信息,通过id和name从数据库中进行查询.
是:需要展示
举例:id,name,price,pic,
否:不需要进行展示
举例:description
6.特例:如果需要检索范围,则需要进行分词.
lucene 全文检索工具的介绍的更多相关文章
- Lucene3.6.2包介绍,第一个Lucene案例介绍,查看索引信息的工具lukeall介绍,Luke查看的索引库内容,索引查找过程
2.Lucene3.6.2包介绍,第一个Lucene案例介绍,查看索引信息的工具lukeall介绍,Luke查看的索引库内容,索引查找过程 2014-12-07 23:39 2623人阅读 评论(0) ...
- Lucene全文检索技术
Lucene全文检索技术 今日大纲 ● 搜索的概念.搜索引擎原理.倒排索引 ● 全文索引的概念 ● 使用Lucene对索引进行CRUD操作 ● Lucene常用API详解 ● ...
- Apache Lucene(全文检索引擎)—创建索引
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- Elasticsearch全文检索工具入门
Elasticsearch全文检索工具入门: 1.下载对应系统版本的文件 elasticsearch-2.4.0.zip 1.1运行elasticsearch-2.4.0\elasticsearch- ...
- Lucene全文检索_分词_复杂搜索_中文分词器
1 Lucene简介 Lucene是apache下的一个开源的全文检索引擎工具包. 1.1 全文检索(Full-text Search) 1.1.1 定义 全文检索就是先分词创建索引,再执行搜索的过 ...
- Lucene 全文检索
基于 lucene 8 1 Lucene简介 Lucene是apache下的一个开源的全文检索引擎工具包. 1.1 全文检索(Full-text Search) 全文检索就是先分词创建索引,再执行搜索 ...
- 星型数据仓库olap工具kylin介绍
星型数据仓库olap工具kylin介绍 数据仓库是目前企业级BI分析的重要平台,尤其在互联网公司,每天都会产生数以百G的日志,如何从这些日志中发现数据的规律很重要. 数据仓库是数据分析的重要工具, 每 ...
- linux下内存泄露检测工具Valgrind介绍
目前在linux开发一个分析实时路况的应用程序,在联合测试中发现程序存在内存泄露的情况. 这下着急了,马上就要上线了,还好发现了一款Valgrind工具,完美的解决了内存泄露的问题. 推荐大家可以使用 ...
- Java XML解析工具 dom4j介绍及使用实例
Java XML解析工具 dom4j介绍及使用实例 dom4j介绍 dom4j的项目地址:http://sourceforge.net/projects/dom4j/?source=directory ...
随机推荐
- OpenResty安装(Centos7.2)
下载.解压安装包 [root]# wget https://openresty.org/download/openresty-1.11.2.5.tar.gz 安装libpq.pcre.openssl ...
- mac上命令行解压rar
时间进入到2018年12月,mac上好用的rar解压工具要收费了.被逼的没办法,用命令行吧,谁让咱擅长呢? 1,使用Homebrew安装unrar,没有自己装去 brew install unrar ...
- Java后台+数据库+Java web前端(新手)
实现简单页面上对数据的增删改查:Java后台+数据库表+Jsp前端网页设计 这里做一个简单的学生课程信息管理系统,做之前一定要先有自己的思路,要不然对新手来说,很容易乱的. 另有一完整的代码可供参考, ...
- app刷新
https://segmentfault.com/a/1190000006733978 优化TCP socket参数,包括:是否关闭快速回收.初始RTO.初始拥塞窗口.socket缓存大小.Delay ...
- 笔记本(ThinkPad)怎样关闭触摸板
随着笔记本电脑的普及,人们越来越习惯于出门使用笔记本,笔记本的便捷高效也大幅度地提升了人们的工作效率.但是如果居家使用笔记本电脑,也有其不便之处.比如在键盘上打字,很容易就会喷到触摸板,以至于光标一下 ...
- Entity Framework学习初级篇2
Entity Framework 学习初级篇2--ObjectContext.ObjectQuery.ObjectStateEntry.ObjectStateManager类的介绍 本节,简单的介绍E ...
- 关于RBAC的文章
权限系统与RBAC模型概述 RBAC权限管理模型 摘自慕课网的RBAC
- cocos2dx 3.x(for 循环让精灵从中间往上下两边排列)
最近很多游戏都喜欢房卡类的游戏,就是创建房间时(),选择玩法与规则,今天耗费2小时处理这个数学问题:例如选择规则两条,则背景框中间显示两条规则,若选择三条,则背景框中间显示三条规则与玩法,依次从中间往 ...
- web.config或App.config中AttachDBFilenamex相对路径问题
<add name="employeeManagerConnectionString" connectionString="Data Source=.\SQLExp ...
- LeetCode112.路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和. 说明: 叶子节点是指没有子节点的节点. 示例: 给定如下二叉树,以及目标和 sum = 22 ...