HDFS基本原理总结
HDFS由三个基本组件组成:NameNode,SecondaryName,DataNode,其思想类似于Linux的文件系统,可以进行类比。
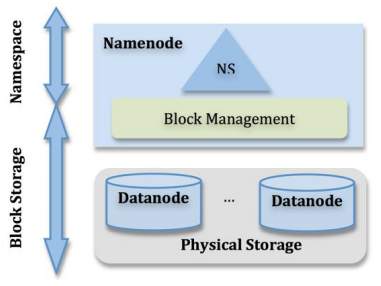
1.NameNode介绍:
1.管理整个文件系统的命名空间,内部维护了命名树。
2.存储元数据:文件层级关系,文件所有者及权限,每个文件由哪些文件块组成(但元信息中不包括每个块的位置)。内容通过fsimage及edits维护,后文会详述。
3.接受客户端请求
2.为什么HDFS倾向于存储大文件:
首先,NameNode中存储一条元信息需要200byte,而元信息是保存在NameNode的内存中的,不能分布式存储,文件越小,存储同样大小的内容元信息越大,NameNode的内存有可能会成为系统存储的瓶颈。
其次,大文件减少了磁盘的寻道时间。但是数据块过大也会出现问题,MapReduce框架通常会为每个数据块启动一个进程,数据块过大会使并行数量减少,降低任务处理效率。
3.元信息持久化:
fsimage是NameNode的元数据镜像文件,用于存储某一时段内存的元数据信息,而系统运行期间所有元信息的操作都保存在内存中并被持久化到另一个文件edits中,edits会被周期性合并进fsimage中。合并两个日志的操作显然会占用大量的CPU,内存及IO,而NameNode中的计算及存储资源是很宝贵的,因此,通常合并操作通常交给SecondaryNameNode(注意,SecondaryNameNode作用不是热备!)。而NameNode本身通常也不会参与MapReduce计算和数据存储。
4.单点问题:
可以发现,HDFS中NameNode是一个单点,除了定期保存fsimage用于故障恢复外,也可以在元数据写入同时将其实时同步到一个远程挂载的NFS上。
5.SecondaryNameNode作用:
1. 减少启动时NameNode合并日志的时间
2. 一定程度上减少了NameNode的单点问题
2.DataNode
1.负责存储数据块,响应客户端读写(注意,客户端直接读写DataNode,而非经过NameNode)。
2.根据NameNode发送的指令创建,删除和复制文件。
3.定期向NameNode发送心跳,报告文件块列表信息。
4.为了安全,提供了数据块冗余,默认为3个副本。数据块默认为64MB
5.数据完整性问题:
存储和处理数据时数据有可能发生错误或丢失,HDFS会对写入的数据计算校验和。
HDFS基本原理总结的更多相关文章
- HDFS基本原理及数据存取实战
---------------------------------------------------------------------------------------------------- ...
- 【图文详解】HDFS基本原理
本文主要详述了HDFS的组成结构,客户端上传下载的过程,以及HDFS的高可用和联邦HDFS等内容.若有不当之处还请留言指出. 当数据集大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区,并 ...
- Hadoop之HDFS(二)HDFS基本原理
HDFS 基本 原理 1,为什么选择 HDFS 存储数据 之所以选择 HDFS 存储数据,因为 HDFS 具有以下优点: 1.高容错性 数据自动保存多个副本.它通过增加副本的形式,提高容错性. 某一 ...
- HDFS基本原理
一.什么是HDFS HDFS即Hadoop分布式文件系统(Hadoop Distributed Filesystem),以流式数据访问模式来存储超大文件,它和现有的分布式文件系统有很多共同点.但同时, ...
- hdfs的基本原理和基本操作总结
hdfs基本原理 Hadoop分布式文件系统(HDFS)被设计成适合执行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有非常多共同点. 但同一时候,它和 ...
- 最通熟易懂的Hadoop HDFS实践攻略
HDFS是用来解决什么问题?怎么解决的? 如何在命令行下操作HDFS? 如何使用Java API来操作HDFS? 在了解基本思路和操作方法后,进一步深究HDFS具体的读写数据流程 学习并实践本文教程后 ...
- Hadoop_HDFS_02
1. HDFS入门 1.1 HDFS基本概念 HDFS是Hadoop Distribute File System的简称, 意为: Hadoop分布式文件系统. 是Hadoop三大核心组件之一, 作为 ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
- 定时脚本: 删除HDFS中的过期文件
1. 基本原理: 通过hadoop fs -ls *命令获取相关文件或目录的修改时间,然后与设定的过期时间进行比较,之后执行删除操作即可 2. 相关代码: #!/bin/bash source ~/. ...
随机推荐
- java url demo
// File Name : URLDemo.java import java.net.*; import java.io.*; public class URLDemo { public stati ...
- UVA-714 二分
把可能的进行二分判断,判断的时候尽量向右取,一直取到不能去为止,这样才有可能成功分割. 判断是否可以把up作为最大值的代码: bool judge(LL up){ if(up < Big) re ...
- Codeforces475D - CGCDSSQ
Portal Description 给出长度为\(n(n\leq10^5)\)的序列\(\{a_n\}\),给出\(q(q\leq3\times10^5)\)个\(x\),对于每个\(x\),求满足 ...
- Spring data mongodb ObjectId ,根据id日期条件查询,省略@CreatedDate注解
先看看ObjectId 的json 结构,非常丰富,这里有唯一机器码,日期,时间戳等等,所以强烈建议ID 使用 ObjectId 类型,并且自带索引 Spring data mongodb 注解 @C ...
- python 小练习之生成手机号码
需求分析: 1 将固定的号码段放到list中 如:136 137 180 183等等 2 随机取8个数字元素 3 将固定号码段与随机产生的元素拼接在一起 4 写入文件 import stringdef ...
- H3C单臂路由配置
Route配置 int g0/0.1 ip add 192.168.10.1 255.255.255.0 vlan-type dot1q vid 10 #子接口封装dot1q并分配给VLAN 10 q ...
- U-Boot启动过程
开发板上电后,执行U-Boot的第一条指令,然后顺序执行U-Boot启动函数.看一下board/smdk2410/u-boot.lds这个链接脚本,可以知道目标程序的各部分链接顺序.第一个要链接的是c ...
- Flex中的FusionCharts 四图监听
<?xml version="1.0" encoding="utf-8"?> <s:Application xmlns:fx="ht ...
- Flex中的FusionCharts 3D饼图
1.3D饼图设计源码 <?xml version="1.0" encoding="utf-8"?> <s:Application xmlns: ...
- R语言实现关联规则与推荐算法(学习笔记)
R语言实现关联规则 笔者前言:以前在网上遇到很多很好的关联规则的案例,最近看到一个更好的,于是便学习一下,写个学习笔记. 1 1 0 0 2 1 1 0 0 3 1 1 0 1 4 0 0 0 0 5 ...