【自然语言处理篇】--以NLTK为基础讲解自然语⾔处理的原理和基础知识
一、前述
Python上著名的⾃然语⾔处理库⾃带语料库,词性分类库⾃带分类,分词,等等功能强⼤的社区⽀持,还有N多的简单版wrapper。
二、文本预处理
1、安装nltk
pip install -U nltk
安装语料库 (一堆对话,一对模型)
import nltk
nltk.download()
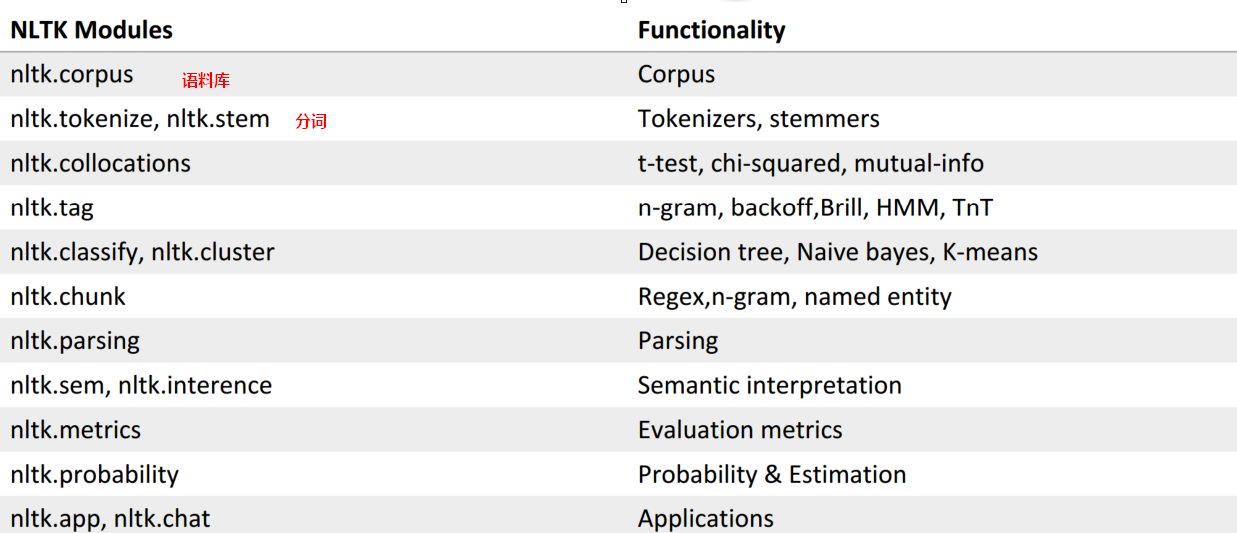
2、功能一览表:
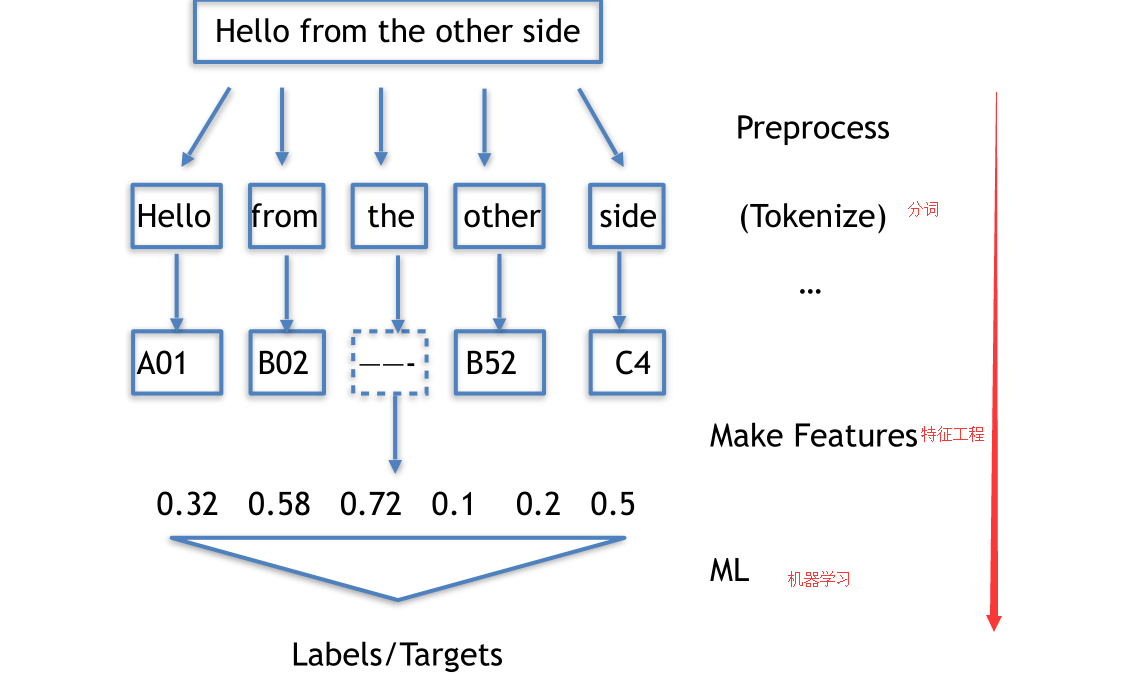
3、文本处理流程
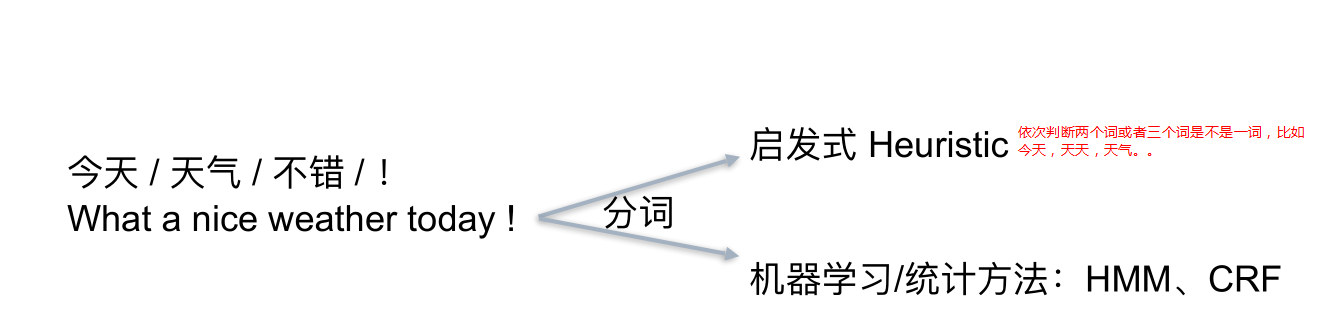
4、Tokenize 把长句⼦拆成有“意义”的⼩部件
import jieba
seg_list = jieba.cut("我来到北北京清华⼤大学", cut_all=True)
print "Full Mode:", "/ ".join(seg_list) # 全模式
seg_list = jieba.cut("我来到北北京清华⼤大学", cut_all=False)
print "Default Mode:", "/ ".join(seg_list) # 精确模式
seg_list = jieba.cut("他来到了了⽹网易易杭研⼤大厦") # 默认是精确模式
print ", ".join(seg_list)
seg_list = jieba.cut_for_search("⼩小明硕⼠士毕业于中国科学院计算所,后在⽇日本京都⼤大学深造")
# 搜索引擎模式
print ", ".join(seg_list)
结果:
【全模式】: 我/ 来到/ 北北京/ 清华/ 清华⼤大学/ 华⼤大/ ⼤大学
【精确模式】: 我/ 来到/ 北北京/ 清华⼤大学
【新词识别】:他, 来到, 了了, ⽹网易易, 杭研, ⼤大厦
(此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了了)
【搜索引擎模式】: ⼩小明, 硕⼠士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算,
计算所, 后, 在, ⽇日本, 京都, ⼤大学, ⽇日本京都⼤大学, 深造
社交⽹络语⾔的tokenize:
import re
emoticons_str = r"""
(?:
[:=;] # 眼睛
[oO\-]? # ⿐鼻⼦子
[D\)\]\(\]/\\OpP] # 嘴
)"""
regex_str = [
emoticons_str,
r'<[^>]+>', # HTML tags
r'(?:@[\w_]+)', # @某⼈人
r"(?:\#+[\w_]+[\w\'_\-]*[\w_]+)", # 话题标签
r'http[s]?://(?:[a-z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-f][0-9a-f]))+',
# URLs
r'(?:(?:\d+,?)+(?:\.?\d+)?)', # 数字
r"(?:[a-z][a-z'\-_]+[a-z])", # 含有 - 和 ‘ 的单词
r'(?:[\w_]+)', # 其他
r'(?:\S)' # 其他
]
正则表达式对照表
http://www.regexlab.com/zh/regref.htm
这样能处理社交语言中的表情等符号:
tokens_re = re.compile(r'('+'|'.join(regex_str)+')', re.VERBOSE | re.IGNORECASE)
emoticon_re = re.compile(r'^'+emoticons_str+'$', re.VERBOSE | re.IGNORECASE)
def tokenize(s):
return tokens_re.findall(s)
def preprocess(s, lowercase=False):
tokens = tokenize(s)
if lowercase:
tokens = [token if emoticon_re.search(token) else token.lower() for token in
tokens]
return tokens
tweet = 'RT @angelababy: love you baby! :D http://ah.love #168cm'
print(preprocess(tweet))
# ['RT', '@angelababy', ':', 'love', 'you', 'baby',
# ’!', ':D', 'http://ah.love', '#168cm']
5、词形归⼀化
Stemming 词⼲提取:⼀般来说,就是把不影响词性的inflection的⼩尾巴砍掉
walking 砍ing = walk
walked 砍ed = walk
Lemmatization 词形归⼀:把各种类型的词的变形,都归为⼀个形式
went 归⼀ = go
are 归⼀ = be
>>> from nltk.stem.porter import PorterStemmer
>>> porter_stemmer = PorterStemmer()
>>> porter_stemmer.stem(‘maximum’)
u’maximum’
>>> porter_stemmer.stem(‘presumably’)
u’presum’
>>> porter_stemmer.stem(‘multiply’)
u’multipli’
>>> porter_stemmer.stem(‘provision’)
u’provis’
>>> from nltk.stem import SnowballStemmer
>>> snowball_stemmer = SnowballStemmer(“english”)
>>> snowball_stemmer.stem(‘maximum’)
u’maximum’
>>> snowball_stemmer.stem(‘presumably’)
u’presum’
>>> from nltk.stem.lancaster import LancasterStemmer
>>> lancaster_stemmer = LancasterStemmer()
>>> lancaster_stemmer.stem(‘maximum’)
‘maxim’
>>> lancaster_stemmer.stem(‘presumably’)
‘presum’
>>> lancaster_stemmer.stem(‘presumably’)
‘presum’
>>> from nltk.stem.porter import PorterStemmer
>>> p = PorterStemmer()
>>> p.stem('went')
'went'
>>> p.stem('wenting')
'went'
6、词性Part-Of-Speech
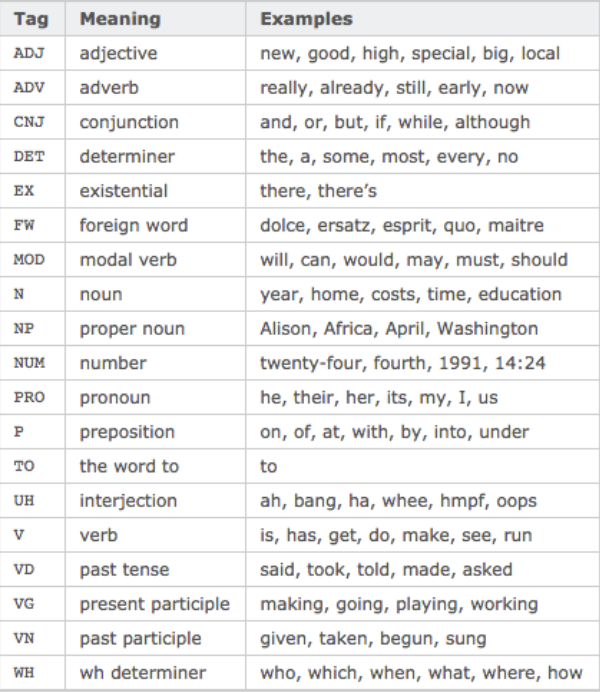
>>> import nltk
>>> text = nltk.word_tokenize('what does the fox say')
>>> text
['what', 'does', 'the', 'fox', 'say']
>>> nltk.pos_tag(text)
[('what', 'WDT'), ('does', 'VBZ'), ('the', 'DT'), ('fox', 'NNS'), ('say', 'VBP')]
7、Stopwords
⾸先记得在console⾥⾯下载⼀下词库
或者 nltk.download(‘stopwords’)
from nltk.corpus import stopwords
# 先token⼀一把,得到⼀一个word_list
# ...
# 然后filter⼀一把
filtered_words =
[word for word in word_list if word not in stopwords.words('english')]
8、⼀条⽂本预处理流⽔线
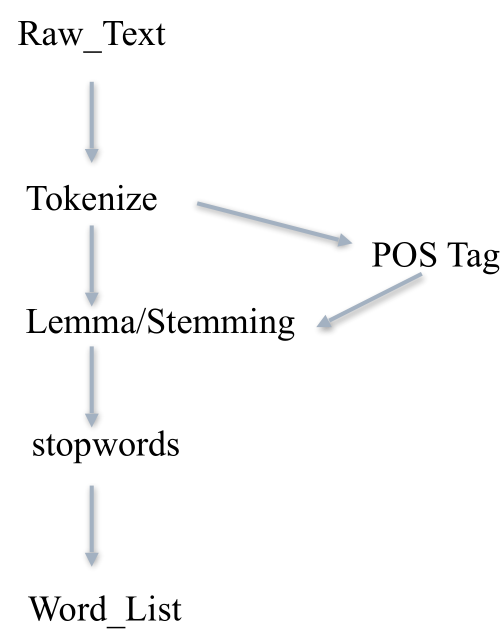
三、自然语言处理应用。
实际上预处理就是将文本转换为Word_List,自然语言处理再转变成计算机能识别的语言。
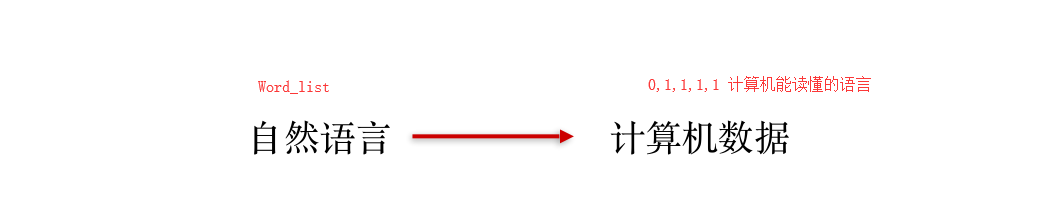
自然语言处理有以下几个应用:情感分析,⽂本相似度, ⽂本分类
1、情感分析
最简单的 sentiment dictionary,类似于关键词打分机制.
like 1
good 2
bad -2
terrible -3
sentiment_dictionary = {}
for line in open('data/AFINN-111.txt')
word, score = line.split('\t')
sentiment_dictionary[word] = int(score)
# 把这个打分表记录在⼀一个Dict上以后
# 跑⼀一遍整个句句⼦子,把对应的值相加
total_score = sum(sentiment_dictionary.get(word, 0) for word in words)
# 有值就是Dict中的值,没有就是0
# 于是你就得到了了⼀一个 sentiment score
显然这个⽅法太Naive,新词怎么办?特殊词汇怎么办?更深层次的玩意⼉怎么办?
加上ML情感分析
from nltk.classify import NaiveBayesClassifier
# 随⼿手造点训练集
s1 = 'this is a good book'
s2 = 'this is a awesome book'
s3 = 'this is a bad book'
s4 = 'this is a terrible book'
def preprocess(s):
# Func: 句句⼦子处理理
# 这⾥里里简单的⽤用了了split(), 把句句⼦子中每个单词分开
# 显然 还有更更多的processing method可以⽤用
return {word: True for word in s.lower().split()}
# return⻓长这样:
# {'this': True, 'is':True, 'a':True, 'good':True, 'book':True}
# 其中, 前⼀一个叫fname, 对应每个出现的⽂文本单词;
# 后⼀一个叫fval, 指的是每个⽂文本单词对应的值。
# 这⾥里里我们⽤用最简单的True,来表示,这个词『出现在当前的句句⼦子中』的意义。
# 当然啦, 我们以后可以升级这个⽅方程, 让它带有更更加⽜牛逼的fval, ⽐比如 word2vec
# 把训练集给做成标准形式
training_data = [[preprocess(s1), 'pos'],
[preprocess(s2), 'pos'],
[preprocess(s3), 'neg'],
[preprocess(s4), 'neg']]
# 喂给model吃
model = NaiveBayesClassifier.train(training_data)
# 打出结果
print(model.classify(preprocess('this is a good book')))
2、文本相似度
⽤元素频率表⽰⽂本特征,常见的做法

然后用余弦定理来计算文本相似度:
Frequency 频率统计:
import nltk
from nltk import FreqDist
# 做个词库先
corpus = 'this is my sentence ' \
'this is my life ' \
'this is the day'
# 随便便tokenize⼀一下
# 显然, 正如上⽂文提到,
# 这⾥里里可以根据需要做任何的preprocessing:
# stopwords, lemma, stemming, etc.
tokens = nltk.word_tokenize(corpus)
print(tokens)
# 得到token好的word list
# ['this', 'is', 'my', 'sentence',
# 'this', 'is', 'my', 'life', 'this',
# 'is', 'the', 'day']
# 借⽤用NLTK的FreqDist统计⼀一下⽂文字出现的频率
fdist = FreqDist(tokens)
# 它就类似于⼀一个Dict
# 带上某个单词, 可以看到它在整个⽂文章中出现的次数
print(fdist['is'])
# 3
# 好, 此刻, 我们可以把最常⽤用的50个单词拿出来
standard_freq_vector = fdist.most_common(50)
size = len(standard_freq_vector)
print(standard_freq_vector)
# [('is', 3), ('this', 3), ('my', 2),
# ('the', 1), ('d
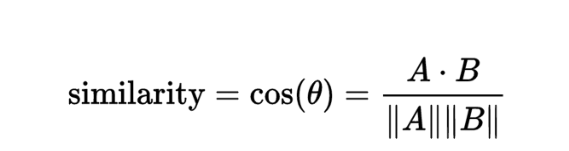
3、文本分类
TF: Term Frequency, 衡量⼀个term在⽂档中出现得有多频繁。
TF(t) = (t出现在⽂档中的次数) / (⽂档中的term总数).
IDF: Inverse Document Frequency, 衡量⼀个term有多重要。
有些词出现的很多,但是明显不是很有卵⽤。⽐如’is',’the‘,’and‘之类
的。
为了平衡,我们把罕见的词的重要性(weight)搞⾼,
把常见词的重要性搞低。
IDF(t) = log_e(⽂档总数 / 含有t的⽂档总数).
TF-IDF = TF * IDF
举个栗⼦
【自然语言处理篇】--以NLTK为基础讲解自然语⾔处理的原理和基础知识的更多相关文章
- 自然语言处理(1)之NLTK与PYTHON
自然语言处理(1)之NLTK与PYTHON 题记: 由于现在的项目是搜索引擎,所以不由的对自然语言处理产生了好奇,再加上一直以来都想学Python,只是没有机会与时间.碰巧这几天在亚马逊上找书时发现了 ...
- Promise入门到精通(初级篇)-附代码详细讲解
Promise入门到精通(初级篇)-附代码详细讲解 Promise,中文翻译为承诺,约定,契约,从字面意思来看,这应该是类似某种协议,规定了什么事件发生的条件和触发方法. Pr ...
- 转载一篇比较详细的讲解html,css的一篇文章,很长
转载自这里,转载请注明出处. DIV+CSS系统学习笔记回顾 第一部分 HTML 第一章 职业规划和前景 职业方向规划定位: web前端开发工程师 web网站架构师 自己创业 转岗管理或其他 ...
- NLTK与NLP原理及基础
参考https://blog.csdn.net/zxm1306192988/article/details/78896319 以NLTK为基础配合讲解自然语言处理的原理 http://www.nlt ...
- C# 基础知识 (一).概念与思想篇
在C#中有一些我自己认为比较独特的知识点,这些知识点是我经常使用的知识,但对它们的了解还是比较少的,所以通过查找资料学习,总结了这些独特的知识点并简单叙述,第一篇主要是一些概念和思想方面的知识.(后面 ...
- CSS3 的box-shadow进阶之 - 基础知识篇
box-shadow被认为是CSS3最好的特性之一,发挥想象力,搭配其它属性,可以做出很多好看的效果(如下图,将会放在下一篇文章讲解),这篇文章主要讲一下box-shadow的基础知识. ...
- 【Java面试题系列】:Java基础知识常见面试题汇总 第一篇
文中面试题从茫茫网海中精心筛选,如有错误,欢迎指正! 1.前言 参加过社招的同学都了解,进入一家公司面试开发岗位时,填写完个人信息后,一般都会让先做一份笔试题,然后公司会根据笔试题的回答结果,确定 ...
- 大数据学习笔记——Java篇之基础知识
Java / 计算机基础知识整理 在进行知识梳理同时也是个人的第一篇技术博客之前,首先祝贺一下,经历了一年左右的学习,从完完全全的计算机小白,现在终于可以做一些产出了!可以说也是颇为感慨,个人认为,学 ...
- Java基础知识常见面试题汇总第一篇
[Java面试题系列]:Java基础知识常见面试题汇总 第一篇 文中面试题从茫茫网海中精心筛选,如有错误,欢迎指正! 1.前言 参加过社招的同学都了解,进入一家公司面试开发岗位时,填写完个人信息后 ...
随机推荐
- Python不同目录间模块调用
#!/usr/bin/python # -*- coding: utf-8 -*- # 导入其它目录下的文件, 需要去帮获取当前程序的绝对路径并加入到环境变量的相对路径中 import os impo ...
- AutoIT 测试GUI工具
今天听到同事提到AutoIT,可以用来测试GUI窗口.了解一下这个工具. 以下内容引自: http://www.jb51.net/article/14870.htm (此url非原出处,该博主未注明原 ...
- 深入css布局篇(3)完结 — margin问题与格式化上下文
深入css布局(3) - margin问题与格式化上下文 在css知识体系中,除了css选择器,样式属性等基础知识外,css布局相关的知识才是css比较核心和重要的点.今天我们来深入学习一下 ...
- 【毕业原版】-《伦敦艺术大学毕业证书》UAL一模一样原件
☞伦敦艺术大学毕业证书[微/Q:865121257◆WeChat:CC6669834]UC毕业证书/联系人Alice[查看点击百度快照查看][留信网学历认证&博士&硕士&海归& ...
- QTTabBar
出处:https://www.mokeyjay.com/archives/1811
- OsharpNS轻量级.net core快速开发框架简明入门教程-从零开始启动Osharp
OsharpNS轻量级.net core快速开发框架简明入门教程 教程目录 从零开始启动Osharp 1.1. 使用OsharpNS项目模板创建项目 1.2. 配置数据库连接串并启动项目 1.3. O ...
- 长沙4月21日开发者大会暨.NET社区成立大会活动纪实
活动总结 2019年4月21日是一个斜风细雨.微风和煦的美好日子,由长沙.NET技术社区.腾讯云云加社区.微软Azure云技术社区.中国.NET技术社区.长沙柳枝行动.长沙互联网活动基地(唐胡子俱乐部 ...
- Boosting(提升方法)之XGBoost
XGBoost是一个机器学习味道非常浓厚的模型,在数学上非常规范,运用正则化.L2范数.二阶梯度.泰勒公式和分布式计算方法,对GBDT等提升树模型进行优化,不仅能处理更大规模的数据,而且运行效率特别高 ...
- Shim 与 Polyfill
Shim: 用来向后兼容.比如 requestIdleCallback,为了在旧的环境中不报错,可以加 shim. 使用环境中现有的 api 来实现,不会引入额外的依赖或其他技术. Polyfill: ...
- Java秋招面经大合集
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...