[DeeplearningAI笔记]改善深层神经网络_优化算法2.1_2.2_mini-batch梯度下降法
觉得有用的话,欢迎一起讨论相互学习~Follow Me
2.1 mini-batch gradient descent mini-batch梯度下降法
我们将训练数据组合到一个大的矩阵中
\(X=\begin{bmatrix}x^{(1)}&x^{(2)}&x^{(3)}&x^{(4)}&x^{(5)}...x^{(n)}\end{bmatrix}\)
\(Y=\begin{bmatrix}y^{(1)}&y^{(2)}&y^{(3)}&y^{(4)}&y^{(5)}...y^{(n)}\end{bmatrix}\)
在对整个数据集进行梯度下降时,你要做的是,你必须训练整个训练集,然后才能进行一步梯度下降法.然后需要重新训练整个数据集,才能进行下一步梯度下降法.所以你在训练整个训练集的一部分时就进行梯度下降,你的算法速度会更快.你可以把训练集分割为小一点的子训练集.这些小的训练集被称为mini-batch.每次训练一个mini-batch后就对模型的权值进行梯度下降的算法叫做mini-batch梯度下降法.
2.2 理解mini-batch梯度下降
在batch梯度下降中,每次迭代你都需要遍历整个训练集,可以预期正常情况下每次迭代的成本函数都会下降.

使用mini-batch梯度下降法时,会发现cost并不是每次迭代都下降的,看到的图像可能是以下这种情况.总体走向朝下但是有更多的噪声.

你需要决定的变量之一就是mini-batch的大小,m就是训练集的大小.
极端情况下,如果m=mini-batch,其实就是batch梯度下降法.在这种极端情况下,假设mini-batch大小为1一次只处理一个,就有了新的算法,叫做随机梯度下降法.
看两个极端情况下,成本函数的优化情况:
假设图中蓝点是最小值点,其中batch梯度下降从某处开始,相对噪声低些,幅度也大一些:
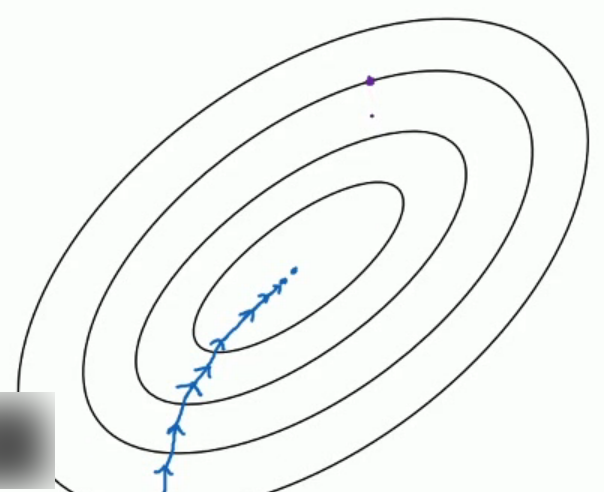
对于随机剃度下降,你只对一个样本进行梯度下降,大部分时候你向着全局最小值靠近,但是有时候你会偏离方向,因为那个样本恰好给你指的方向不正确.因此随机梯度下降法是有很多噪声的.平均来看会向着正确的方向,不过有时候也会方向错误.
因为随机梯度下降法永远不会收敛,而是会一直在最小值附近波动.但它并不会达到最小值并停留于此.
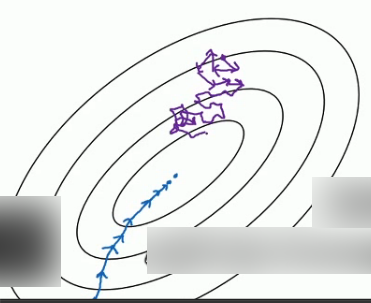
不同的梯度下降算法的利和弊
每次迭代需要处理大量训练样本,该算法主要弊端是特别是在训练样本数量巨大的时候,单次迭代耗时太长,如果训练样本不大,batch梯度下降法运行的很好.
相反如果使用随机梯度下降法,每次只训练一个训练样本,通过减少学习率,噪声也会相应的减少.但是其一大缺点是:你会失去所有向量化带给你的加速.
指导原则
如果训练集较小,就直接使用batch梯度下降法,样本集较小就没必要使用mini-batch梯度下降法.这里说的是少于2000个样本.这样比较适合使用batch梯度下降法.
不然如果数据量较大,一般的mini-batch大小为64到512,考虑到计算机的结构,一般来说,mini-batch的值取2的幂次方数比较合适,会相应的加快训练速度.
[DeeplearningAI笔记]改善深层神经网络_优化算法2.1_2.2_mini-batch梯度下降法的更多相关文章
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.3_2.5_带修正偏差的指数加权平均
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.3 指数加权平均 举个例子,对于图中英国的温度数据计算移动平均值或者说是移动平均值( ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 动量梯度下降法(Momentum) 另一种成本函数优化算法,优化速度一般快于标准 ...
- 改善深层神经网络_优化算法_mini-batch梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam优化、学习率衰减
1.mini-batch梯度下降 在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵: 当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练 ...
- Coursera Deep Learning笔记 改善深层神经网络:优化算法
笔记:Andrew Ng's Deeping Learning视频 摘抄:https://xienaoban.github.io/posts/58457.html 本章介绍了优化算法,让神经网络运行的 ...
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.9_归一化normalization
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.9 归一化Normaliation 训练神经网络,其中一个加速训练的方法就是归一化输入(normalize inputs). 假设我们有一个 ...
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.10_1.12/梯度消失/梯度爆炸/权重初始化
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.10 梯度消失和梯度爆炸 当训练神经网络,尤其是深度神经网络时,经常会出现的问题是梯度消失或者梯度爆炸,也就是说当你训练深度网络时,导数或坡 ...
- [DeeplearningAI笔记]改善深层神经网络1.1_1.3深度学习使用层面_偏差/方差/欠拟合/过拟合/训练集/验证集/测试集
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.1 训练/开发/测试集 对于一个数据集而言,可以将一个数据集分为三个部分,一部分作为训练集,一部分作为简单交叉验证集(dev)有时候也成为验 ...
- deeplearning.ai 改善深层神经网络 week2 优化算法 听课笔记
这一周的主题是优化算法. 1. Mini-batch: 上一门课讨论的向量化的目的是去掉for循环加速优化计算,X = [x(1) x(2) x(3) ... x(m)],X的每一个列向量x(i)是 ...
- deeplearning.ai 改善深层神经网络 week2 优化算法
这一周的主题是优化算法. 1. Mini-batch: 上一门课讨论的向量化的目的是去掉for循环加速优化计算,X = [x(1) x(2) x(3) ... x(m)],X的每一个列向量x(i)是 ...
随机推荐
- 深透清晰理解Java高并发概述
1.多线程安全性 多线程安全性的定义可能众说纷纭,但是其最核心的一点就是正确性,也就是程序的行为结果和预期一致. 当多个线程访问某个类时,不管运行环境采用何种线程调度算法或者这些线程如何交替执行,且不 ...
- Flask源码流程剖析
在此之前需要先知道类和方法,个人总结如下: 1.对象是类创建,创建对象时候类的__init__方法自动执行,对象()执行类的 __call__ 方法 2.类是type创建,创建类时候type的__i ...
- Java与算法之(1) - 冒泡排序
冒泡排序法的原理是,每次比较相邻的两个元素,如果它们的顺序错误就把它们交换过来. 例如对4 3 6 2 7 1 5这7个数字进行从小到大的排序,从最左侧开始,首先比较4和3 因为是从小到大排序,4和3 ...
- ssm maven spring AOP读写分离
ssm maven spring AOP读写分离 总体流程 配置最开始写在pom.xml文件,解析到数据库配置文件,再解析到spring配置文件. 自定义注解DataSource:通过这个注解并且在s ...
- gulp的流与执行顺序
gulp的关键在于流,这从它的logo就能看出来. 在node中,流是操作文件时一个重要的概念.流是指什么呢?它包含两个含义:“水流”和“流水”. 水流蕴含了源源不断或是一股一股那样流过的意味:而流水 ...
- jsp的内置对象
JSP内置对象即无需声明就可以直接使用的对象实例,在实际的开发过程中,比较常用的JSP对象有request,response,session,out和application等,笔者在本文章中将简单介绍 ...
- hbmy周赛1--C
C - Exam Time Limit:1000MS Memory Limit:262144KB 64bit IO Format:%I64d & %I64u Submit St ...
- 教你理解微信小程序的生命周期和运行原理
转自:http://blog.csdn.net/tsr106/article/details/53052879 写微信小程序,他的生命周期不能不知道,不知道小程序就会出现各种bug而无法解决.小助君 ...
- 【C#附源码】数据库文档生成工具支持(Excel+Htm)
数据库文档生成工具是用C#开发的基于NPOI组件的小工具.软件源码大小不到10MB.支持生成Excel 和Html 两种文档形式.了解更多,请访问:http://www.oschina.net/cod ...
- UEP-下拉
uep建立下拉 静态下拉: ①private Map<String,String> beanMap = new HashMap<String,String>(); //gett ...