ElasticSearch入门系列(六)分布式操作
一、路由文档到分片
当你索引一个文档的时候,他被存储在单独一个主分片上。Elasticsearch根据一个算法来找到所在分片上。
shard=hash(routing)%number_of_primary_shards
routing值是一个任意字符串,默认是_id但也可以自定义。这个routing通过哈希函数生成一个数字,然后除以主切片的数量得到一个榆树。这也就是为什么主分片的数量只能在创建索引时定义且不能修改:如果主分片的数量在未来改变了,所有先前的路由值就失效了,文档就永远找不到了。
所有的文档API都接受一个routing参数,用来定义文档到分片的映射。
二、分片交互
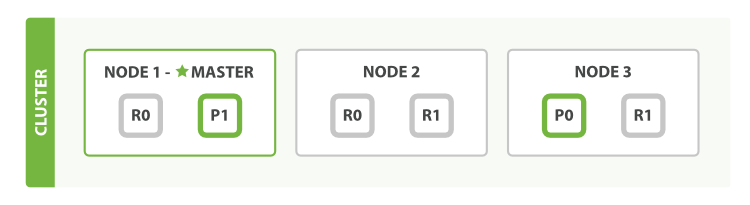
这里有三个节点的集群,他包含一个叫做bblogs的索引并拥有两个主分片。每个主分片有两个复制分片。相同的分片不会再同一个节点上。
我们可以发送请求给集群中任意一个节点,每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点。所以也可以请求转发到需要的节点。
在我们发送请求时,最好的做法是循环通过所有节点请求,这样可以平衡负载。
三、新建索引和删除文档
新建索引和删除文档都是写操作,他们必须在主分片上成功完成才能复制到相关的复制分片上

以下为在主分片和复制分片上成功新建索引和删除文档的步骤:
①:客户端给Node1发送新建索引或删除请求
②:节点使用文档的_id确定文档属于分片0.他转发请求到Node3,分片0位于这个节点上
③:Node3在主分片上执行请求,如果成。他组案发请求到相应的位于Node1和Node2的复制节点上,当所有的复制节点报告成功,Node3报告成功到请求的节点,请求的节点再报告给客户端。
客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片,你的修改就生效了。
replication:
复制的默认值是sync.这将导致主分片得到复制分片的成功响应后才返回。
如果你设置replication为async,请求在主分片上被执行后就会返回客户端,他依旧会转发请求给复制节点,但是你将不知道复制节点成功与否。
consistency:
默认主分片在尝试写入时需要规定数量(quorum)或过半的分片可用。为了防止数据被写入到错的网络分区。
int((primary+number_of_replicas)/2)+1
consistency允许值为一个 全部过过半分区、
timeout:
当分片副本不足时,Elasticsearch会等待更多的分片出现,默认等待一分钟还可以自己设置。
四、检索文档
文档能够从主分片或任意一个复制分片被检索
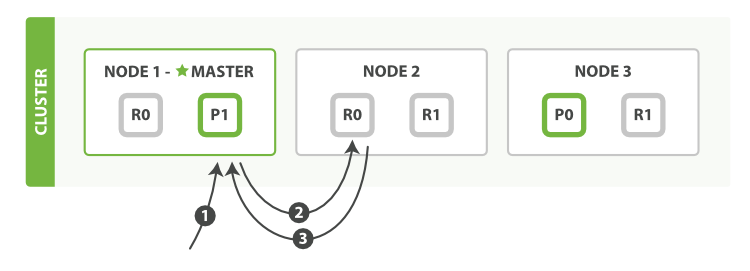
以下为从主分片或复制分片上检索一个文档的步骤:
①:客户端给Node1发送请求
②:节点使用文档的_id确定文档属于分片0、分片0对应的复制分片在三个节点上都有。此时。他转发请求到Node2
③:Node2返回endangered给Node1然后返回给客户端
五、局部更新文档
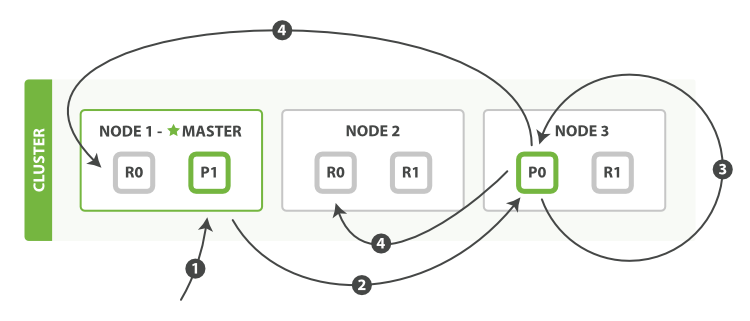
以下为局部更新的步骤:
①:客户端给Node1发送更新请求
②:他转发请求到主分片所在节点Node3
③:Node3从主分片检索出文档,修改_source字段的JSON。然后在主分片上重建索引。如果有其他进程修改了文档,他以retry_on_confluct设置的次数重复步骤3,都未成功则放弃
④:如果Node3成功更新文档,他同时转发文档的新版本到Node1和Node2上的复制节点以重建索引,当所有复制节点报告成功,Node3返回成功给请求节点,然后返回给客户端
六、批量请求
mget和bulk API与单独的文档类似。差别是请求节点知道每个文档所在的分片。它把多文档请求拆成每个分片的对文档请求,然后转发每个参与的节点。
一旦接收到每个节点的应答,然后整理这些响应组合为一个单独的响应,最后返回给客户端。

以下为请求步骤:
1.客户点向Node1发送mget请求
2.Node1为每个分片构建一个多条数据检索请求,然后转发到这些请求所需的主分片或复制分片上。当所有回复被接受,Node1构建响应并返回给客户端
routing参数可以被docs中的每个文档设置
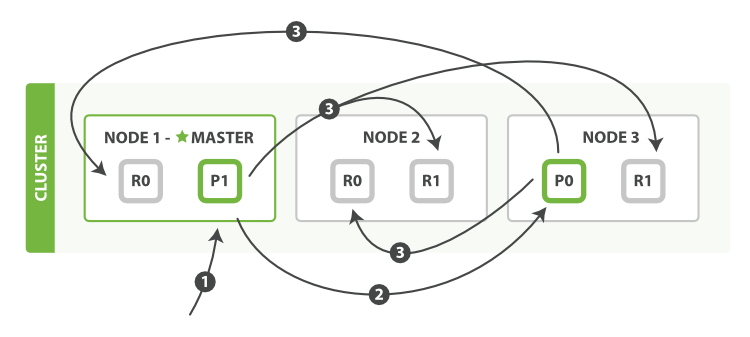
下面我们将罗列使用一个bulk执行多个create、index、delete和update请求的顺序步骤:
- 客户端向
Node 1发送bulk请求。 Node 1为每个分片构建批量请求,然后转发到这些请求所需的主分片上。- 主分片一个接一个的按序执行操作。当一个操作执行完,主分片转发新文档(或者删除部分)给对应的复制节点,然后执行下一个操作。复制节点为报告所有操作完成,节点报告给请求节点,请求节点整理响应并返回给客户端。
bulk API还可以在最上层使用replication和consistency参数,routing参数则在每个请求的元数据中使用。
ElasticSearch入门系列(六)分布式操作的更多相关文章
- ElasticSearch入门 第六篇:复合数据类型——数组,对象和嵌套
这是ElasticSearch 2.4 版本系列的第六篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- Elasticsearch入门教程(六):Elasticsearch查询(二)
原文:Elasticsearch入门教程(六):Elasticsearch查询(二) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:h ...
- ElasticSearch实战系列六: Logstash快速入门和实战
前言 本文主要介绍的是ELK日志系统中的Logstash快速入门和实战 ELK介绍 ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是 ...
- Go语言入门系列(六)之再探函数
Go语言入门系列前面的文章: Go语言入门系列(三)之数组和切片 Go语言入门系列(四)之map的使用 Go语言入门系列(五)之指针和结构体的使用 在Go语言入门系列(二)之基础语法总结这篇文章中已经 ...
- ElasticSearch入门系列(四)分布式初探
序言:ElasticSearch致力于隐藏分布式系统的复杂性,以下的操作都是在底层自动完成的: 将你的文档分区到不同的容器或者分片(shards),他们可以存在于一个或多个节点中 将分片均匀的分配到各 ...
- Elasticsearch入门系列~通过Java一系列操作Elasticsearch
Elasticsearch索引的创建.数据的增删该查操作 上一章节已经在Linux系统上安装Elasticsearch并且可以外网访问,这节主要通过Java代码操作Elasticsearch 1.创建 ...
- ElasticSearch入门系列(五)数据
序言:无论程序如何写,最终都是为了组织数据为我们服务.在实际应用中,并不是所有相同类型的实体的看起来都是一样的.传统上我们使用行和列将数据存储在关系型数据库中相当于使用电子表格,这种固定的存储方式导致 ...
- ElasticSearch入门系列(七)搜索
一.在之前,我们已经学会了如何使用elasticsearch作为一个简单的NoSql风格的分布式文件存储器--我们可以将一个JSON文档扔给Elasticsearch.也可以根据ID检索他们.但Ela ...
- ElasticSearch入门系列(三)文档,索引,搜索和聚合
一.文档 在实际使用中的对象往往拥有复杂的数据结构 Elasticsearch是面向文档的,这意味着他可以存储整个对象或文档,然而他不仅仅是存储,还会索引每个文档的内容使之可以被搜索,在Elastic ...
随机推荐
- Centos 7 ASP.NET Core 1.0 Docker部署
先决条件 64位,内核3.10以上,查看当前的内核版本,打开一个终端使用uname -r显示您的内核版本 安装 sudo yum update sudo tee /et ...
- Eclipse安装python注意事项
第一次用Eclipse来开发python,在安装环境时走了很多弯路,下面记录下正确的安装方法: 1.下载Eclipse与jdk.(注意jdk与Eclipse要么都是32位,要么都是64位) 2.安装好 ...
- MMORPG大型游戏设计与开发(规范)
一件事如果没有规范.章法,那么做这件事起来往往会遇到许多难题,特别是在多人协作的时候,没有到规范通常让每个人多多少少都面临着头疼的困难.举个例子,多个人要做一桌美味的饺子,有买材料.做面皮.弄肉(菜) ...
- 最新discuz模版制作7堂课让你精通discuz模版制作
第一课 基本知识储备一.基本 HTML 代码二.网站语言编码 三.DIV+CSS 认知及应用 第二课 必备软件.环境配置及程序安装 第三课 DISCUZ 构架详解 一.DISCUZ 基础构架讲 ...
- Python+excel实现的简单接口自动化 V0.1
好久没写博客了..最近忙着工作以及新工作的事.. 看了下以前写的简单接口自动化,拿出来总结下,也算记录下学习成果 先来贴一下最后的结果,结果是写在原来的excel中 执行完毕后,会将结果写入到“状态” ...
- NOIP2004合并果子
题目描述 在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆.多多决定把所有的果子合成一堆. 每一次合并,多多可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和.可 ...
- VIJOS1240 朴素的网络游戏[DP]
描述 佳佳最近又迷上了某款类似于虚拟人生的网络游戏.在游戏中,佳佳是某旅行团的团长,他需要安排客户住进旅馆.旅馆给了佳佳的旅行团一个房间数的限制.每一个房间有不同的容纳人数和价钱(这个价格是房间的总价 ...
- win7旗舰版 中文64位 产品密钥(序列号)
无需破解即可激活Windows 7旗舰版的"神Key". 第一枚"神Key":TFP9Y-VCY3P-VVH3T-8XXCC-MF4YK: 第二枚"神 ...
- java 28 - 2 设计模式之 模版设计模式
模版设计模式 模版设计模式概述 模版方法模式就是定义一个算法的骨架,而将具体的算法延迟到子类中来实现 优点 使用模版方法模式,在定义算法骨架的同时,可以很灵活的实现具体的算法,满足用户灵活多变的需求 ...
- hdu 1255
覆盖的面积 Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Sub ...