Hadoop及Hbase部署
原文转自:https://www.cnblogs.com/itzgr/p/10233932.html
作者:木二
目录
- 一 环境准备
- 1.1 相关环境
- 1.2 网络环境
- 二 基础环境配置
- 2.1 配置相关主机名
- 2.2 防火墙及SELinux
- 2.3 时间同步
- 三 jdk安装配置
- 3.1 jdk环境安装
- 3.2 jdk系统变量增加
- 四 SSH无密钥访问
- 4.1 master-slave01之间无密钥登录
- 五 安装hadoop及配置
- 5.1 解压hadoop
- 5.2 创建相应目录
- 5.3 master修改相关配置
- 5.4 slave节点安装hadoop
- 六 系统变量及环境修改
- 6.1 hadoop环境变量
- 6.2 系统环境变量
- 七 格式化namenode并启动
- 八 检测hadoop
- 8.1 确认验证
- 8.2 java检测
- 九 安装Zookeeper
- 9.1 安装并配置zookeeper
- 9.2 修改zookeeper相关配置项
- 9.3 创建myid
- 9.4 修改环境变量
- 9.5 Slave节点的zookeeper部署
- 9.6 Slave主机修改myid
- 9.7 启动zookeeper
- 十 安装及配置hbase
- 10.1 安装hbase
- 10.2 修改环境变量
- 10.4 修改hbase-site.xml
- 10.5 配置 regionservers
- 十一 启动hbase
- 十二 测试
- 12.1 浏览器检测
- 12.2 java检测
一 环境准备
1.1 相关环境
- 系统:CentOS 7
#CentOS 6.x系列也可参考,转换相关命令即可。
- hadoop包:hadoop-2.7.0.tar.gz
#下载官方地址:http://www.apache.org/dyn/closer.cgi/hadoop/common/
- hbase包:hbase-1.0.3-bin.tar.gz
#下载官方地址:http://www.apache.org/dyn/closer.cgi/hbase
- java环境:jdk-8u111-linux-x64.tar.gz
#下载官方地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
- 其他:zookeeper-3.4.9.tar.gz
#下载官方地址:http://www.apache.org/dyn/closer.cgi/zookeeper/
1.2 网络环境
|
主机名
|
IP
|
|
master
|
172.24.8.12
|
|
slave01
|
172.24.8.13
|
|
slave02
|
172.24.8.14
|
二 基础环境配置
2.1 配置相关主机名
1 [root@localhost ~]# hostnamectl set-hostname master
2 [root@localhost ~]# hostnamectl set-hostname slave01
3 [root@localhost ~]# hostnamectl set-hostname slave02
提示:三台主机都需要配置。

1 [root@localhost ~]# vi /etc/hosts
2 ……
3 172.24.8.12 master
4 172.24.8.13 slave01
5 172.24.8.14 slave02
6 [root@localhost ~]# scp /etc/hosts root@slave01:/etc/hosts
7 [root@localhost ~]# scp /etc/hosts root@slave02:/etc/hosts
提示:直接将hosts文件复制到slave01和slave02。
2.2 防火墙及SELinux
1 [root@master ~]# systemctl stop firewalld.service #关闭防火墙
2 [root@master ~]# systemctl disable firewalld.service #禁止开机启动防火墙
3 [root@master ~]# vi /etc/selinux/config
4 ……
5 SELINUX=disabled
6 [root@master ~]# setenforce 0
提示:三台主机都需要配置,配置相关的端口放行和SELinux上下文,也可不关闭。
2.3 时间同步
1 [root@master ~]# yum -y install ntpdate
2 [root@master ~]# ntpdate cn.ntp.org.cn
提示:三台主机都需要配置。
三 jdk安装配置
3.1 jdk环境安装
1 [root@master ~]# cd /usr/
2 [root@master usr]# tar -zxvf jdk-8u111-linux-x64.tar.gz
提示:三台都需要配置。
3.2 jdk系统变量增加
1 [root@master ~]# vi .bash_profile
2 ……
3 PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
4 export PATH
5 export JAVA_HOME=/usr/jdk1.8.0_111
6 [root@master ~]# scp /root/.bash_profile root@slave01:/root/.bash_profile
7 [root@master ~]# scp /root/.bash_profile root@slave02:/root/.bash_profile
8 [root@master ~]# source /root/.bash_profile #重新加载环境变量
提示:
1 [root@master ~]# java -version #测试
2 [root@slave01 ~]# java -version #测试
3 [root@slave02 ~]# java -version #测试
四 SSH无密钥访问
4.1 master-slave01之间无密钥登录
1 [root@master ~]# ssh-keygen -t rsa
2 [root@slave01 ~]# ssh-keygen -t rsa
3 [root@slave02 ~]# ssh-keygen -t rsa
提示:三台都需要生成key密钥。
1 [root@slave01 ~]# scp /root/.ssh/id_rsa.pub root@master:/root/.ssh/slave01.id_rsa.pub
2 #将slave01主机的公钥复制给master,并命名为slave01.id_rsa.pub。
3 [root@master ~]# cat /root/.ssh/id_rsa.pub >>/root/.ssh/authorized_keys
4 [root@master ~]# cat /root/.ssh/slave01.id_rsa.pub >>/root/.ssh/authorized_keys
5 [root@master ~]# scp /root/.ssh/authorized_keys slave01:/root/.ssh/
6 #将master中关于master的公钥和slave01的公钥同时写入authorized_keys文件,并将此文件传送至slave01。
1 [root@slave02 ~]# scp /root/.ssh/id_rsa.pub root@master:/root/.ssh/slave02.id_rsa.pub
2 #将slave02主机的公钥复制给master,并命名为slave02.id_rsa.pub。
3 [root@master ~]# cat /root/.ssh/id_rsa.pub >/root/.ssh/authorized_keys
4 注意:此处为防止slave之间互相登录,采用覆盖方式写入。
5 [root@master ~]# cat /root/.ssh/slave02.id_rsa.pub >>/root/.ssh/authorized_keys
6 [root@master ~]# scp /root/.ssh/authorized_keys slave02:/root/.ssh/
7 #将master中关于master的公钥和slave01的公钥同时写入authorized_keys文件,并将此文件传送至slave01。
8 #以上实现master<---->slave01双向无密钥登录。
9 [root@master .ssh]# cat slave01.id_rsa.pub >>authorized_keys
10 #为实现master和slave01、slave02双向无密钥登录,将slave01的公钥重新写入。
11 [root@master ~]# cat /root/.ssh/authorized_keys #存在master和slave01、slave02的三组公钥
12 [root@slave01 ~]# cat /root/.ssh/authorized_keys #存在master和slave01的公钥
13 [root@slave02 ~]# cat /root/.ssh/authorized_keys #存在master和slave02的公钥
五 安装hadoop及配置
5.1 解压hadoop
1 [root@master ~]# cd /usr/
2 [root@master usr]# tar -zxvf hadoop-2.7.0.tar.gz
5.2 创建相应目录
1 [root@master usr]# mkdir /usr/hadoop-2.7.0/tmp #存放集群临时信息
2 [root@master usr]# mkdir /usr/hadoop-2.7.0/logs #存放集群相关日志
3 [root@master usr]# mkdir /usr/hadoop-2.7.0/hdf #存放集群信息
4 [root@master usr]# mkdir /usr/hadoop-2.7.0/hdf/data #存储数据节点信息
5 [root@master usr]# mkdir /usr/hadoop-2.7.0/hdf/name #存储Name节点信息
5.3 master修改相关配置
5.3.1 修改slaves
1 [root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/slaves
2 slave01
3 slave02
4 #删除localhost,添加相应的主机名。
5.3.2 修改core-site.xml
1 [root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/core-site.xml
2 ……
3 <configuration>
4 <property>
5 <name>fs.default.name</name>
6 <value>hdfs://master:9000</value>
7 </property>
8 <property>
9 <name>hadoop.tmp.dir</name>
10 <value>file:/usr/hadoop-2.7.0/tmp</value>
11 <description>
12 Abase for other temporary directories.
13 </description>
14 </property>
15 <property>
16 <name>hadoop.proxyuser.root.hosts</name>
17 <value>master</value>
18 </property>
19 <property>
20 <name>hadoop.proxyuser.root.groups</name>
21 <value>*</value>
22 </property>
23 </configuration>
5.3.3 修改hdfs-site.xml
1 [root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/hdfs-site.xml
2 ……
3 <configuration>
4 <property>
5 <name>dfs.datanode.data.dir</name>
6 <value>/usr/hadoop-2.7.0/hdf/data</value>
7 <final>true</final>
8 </property>
9 <property>
10 <name>dfs.namenode.name.dir</name>
11 <value>/usr/hadoop-2.7.0/hdf/name</value>
12 <final>true</final>
13 </property>
14 </configuration>
5.3.4 修改mapred-site.xml
1 [root@master ~]# cp /usr/hadoop-2.7.0/etc/hadoop/mapred-site.xml.template /usr/hadoop-2.7.0/etc/hadoop/mapred-site.xml
2 [root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/mapred-site.xml
3 ……
4 <configuration>
5 <property>
6 <name>mapreduce.framework.name</name>
7 <value>yarn</value>
8 </property>
9 <property>
10 <name>mapreduce.jobhistory.address</name>
11 <value>master:10020</value>
12 </property>
13 <property>
14 <name>mapreduce.jobhistory.webapp.address</name>
15 <value>master:19888</value>
16 </property>
17 </configuration>
5.3.5 修改yarn-site.xml
1 [root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/yarn-site.xml
2 <configuration>
3 ……
4 <property>
5 <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
6 <value>org.apache.mapred.ShuffleHandler</value>
7 </property>
8 <property>
9 <name>yarn.resourcemanager.address</name>
10 <value>master:8032</value>
11 </property>
12 <property>
13 <name>yarn.resourcemanager.scheduler.address</name>
14 <value>master:8030</value>
15 </property>
16 <property>
17 <name>yarn.resourcemanager.resource-tracker.address</name>
18 <value>master:8031</value>
19 </property>
20 <property>
21 <name>yarn.resourcemanager.admin.address</name>
22 <value>master:8033</value>
23 </property>
24 <property>
25 <name>yarn.resourcemanager.webapp.address</name>
26 <value>master:8088</value>
27 </property>
28 </configuration>
5.4 slave节点安装hadoop
1 [root@master ~]# scp -r /usr/hadoop-2.7.0 root@slave01:/usr/
2 [root@master ~]# scp -r /usr/hadoop-2.7.0 root@slave02:/usr/
提示:直接将master的hadoop目录复制到slave01和slave02。
六 系统变量及环境修改
6.1 hadoop环境变量
1 [root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/hadoop-env.sh
2 export JAVA_HOME=/usr/jdk1.8.0_111
3 [root@master ~]# vi /usr/hadoop-2.7.0/etc/hadoop/yarn-env.sh
4 export JAVA_HOME=/usr/jdk1.8.0_111
6.2 系统环境变量
1 [root@master ~]# vi /root/.bash_profile
2 ……
3 PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
4 export PATH
5 export JAVA_HOME=/usr/jdk1.8.0_111
6 export HADOOP_HOME=/usr/hadoop-2.7.0
7 export HADOOP_LOG_DIR=/usr/hadoop-2.7.0/logs
8 export YARN_LOG_DIR=$HADOOP_LOG_DIR
9 [root@master ~]# scp /root/.bash_profile root@slave01:/root/
10 [root@master ~]# scp /root/.bash_profile root@slave02:/root/
11 [root@master ~]# source /root/.bash_profile
12 [root@slave01 ~]# source /root/.bash_profile
13 [root@slave02 ~]# source /root/.bash_profile
七 格式化namenode并启动
1 [root@master ~]# cd /usr/hadoop-2.7.0/bin/
2 [root@master bin]# ./hadoop namenode -format #或者./hdfs namenode -format
3 提示:其他主机不需要格式化。
4 [root@master ~]# cd /usr/hadoop-2.7.0/sbin
5 [root@master sbin]# ./start-all.sh #启动
提示:其他节点不需要启动,主节点启动时,会启动其他节点,查看其他节点进程,slave也可以单独启动datanode和nodemanger进程即可,如下——
1 [root@slave01 ~]# cd /usr/hadoop-2.7.0/sbin
2 [root@slave01 ~]# hadoop-daemon.sh start datanode
3 [root@slave01 ~]# yarn-daemon.sh start nodemanager
八 检测hadoop
8.1 确认验证
http://172.24.8.12:8088/cluster
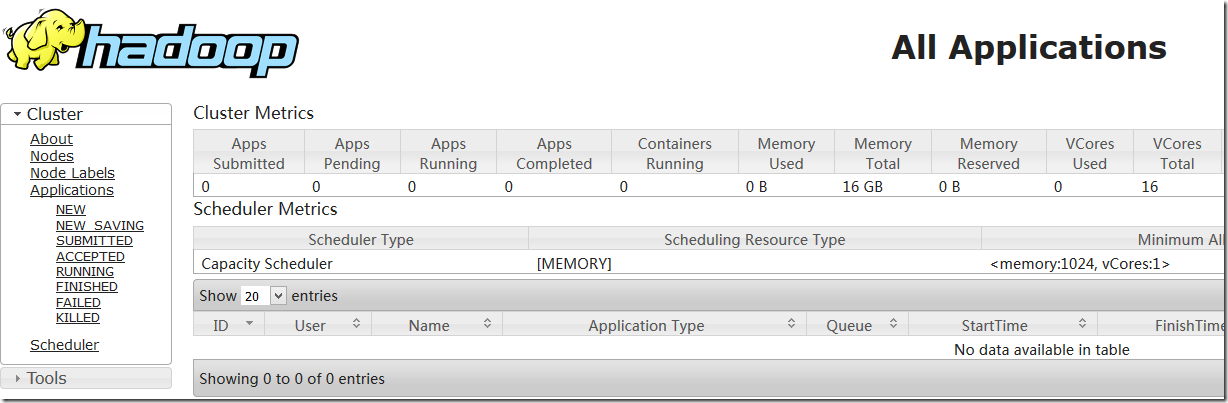
8.2 java检测
1 [root@master ~]# /usr/jdk1.8.0_111/bin/jps
2 21346 NameNode
3 21703 ResourceManager
4 21544 SecondaryNameNode
5 21977 Jps
6 [root@slave01 ~]# jps
7 16038 NodeManager
8 15928 DataNode
9 16200 Jps
10 15533 SecondaryNameNode
11 [root@slave02 ~]# jps
12 15507 SecondaryNameNode
13 16163 Jps
14 16013 NodeManager
15 15903 DataNode
九 安装Zookeeper
9.1 安装并配置zookeeper
1 [root@master ~]# cd /usr/
2 [root@master usr]# tar -zxvf zookeeper-3.4.9.tar.gz #解压zookeeper
3 [root@master usr]# mkdir /usr/zookeeper-3.4.9/data #创建zookeeper数据保存目录
4 [root@master usr]# mkdir /usr/zookeeper-3.4.9/logs #创建zookeeper日志保存目录
9.2 修改zookeeper相关配置项
1 [root@master ~]# cp /usr/zookeeper-3.4.9/conf/zoo_sample.cfg /usr/zookeeper-3.4.9/conf/zoo.cfg
2 #从模板复制zoo配置文件
3 [root@master ~]# vi /usr/zookeeper-3.4.9/conf/zoo.cfg
4 tickTime=2000
5 initLimit=10
6 syncLimit=5
7 dataDir=/usr/zookeeper-3.4.9/data
8 dataLogDir=/usr/zookeeper-3.4.9/logs
9 clientPort=2181
10 server.1=master:2888:3888
11 server.2=slave01:2888:3888
12 server.3=slave02:2888:3888
9.3 创建myid
1 [root@master ~]# vi /usr/zookeeper-3.4.9/data/myid
2 1
注意:此处创建的文件myid内容为zoo.cfg配置中server.n中的n。即master为1,slave01为2,slave02为3。
9.4 修改环境变量
1 [root@master ~]# vi /root/.bash_profile #修改环境变量
2 PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin #增加zookeeper变量路径
3 export PATH
4 export JAVA_HOME=/usr/jdk1.8.0_111
5 export HADOOP_HOME=/usr/hadoop-2.7.0
6 export HADOOP_LOG_DIR=/usr/hadoop-2.7.0/logs
7 export YARN_LOG_DIR=$HADOOP_LOG_DIR
8 export ZOOKEEPER_HOME=/usr/zookeeper-3.4.9/ #增加zookeeper路径
9 [root@master ~]# source /root/.bash_profile
9.5 Slave节点的zookeeper部署
1 [root@master ~]# scp -r /usr/zookeeper-3.4.9/ root@slave01:/usr/
2 [root@master ~]# scp -r /usr/zookeeper-3.4.9/ root@slave02:/usr/
3 [root@master ~]# scp /root/.bash_profile root@slave01:/root/
4 [root@master ~]# scp /root/.bash_profile root@slave02:/root/
提示:三台主机都需要配置,依次将zookeeper和环境变量文件profile复制到slave01和slave02。
9.6 Slave主机修改myid
1 [root@slave01 ~]# vi /usr/zookeeper-3.4.9/data/myid
2 2
3 [root@slave02 ~]# vi /usr/zookeeper-3.4.9/data/myid
4 3
9.7 启动zookeeper
1 [root@master ~]# cd /usr/zookeeper-3.4.9/bin/
2 [root@master bin]# ./zkServer.sh start
3 [root@slave01 ~]# cd /usr/zookeeper-3.4.9/bin/
4 [root@slave01 bin]# ./zkServer.sh start
5 [root@slave02 ~]# cd /usr/zookeeper-3.4.9/bin/
6 [root@slave02 bin]# ./zkServer.sh start
提示:三台主机都需要启动,命令方式一样。
十 安装及配置hbase
10.1 安装hbase
1 [root@master ~]# cd /usr/
2 [root@master usr]# tar -zxvf hbase-1.0.3-bin.tar.gz #解压hbase
3 [root@master ~]# mkdir /usr/hbase-1.0.3/logs #创建hbase的日志存放目录
4 [root@master ~]# mkdir /usr/hbase-1.0.3/temp #hbase的临时文件存放目录
5 [root@master ~]# mkdir /usr/hbase-1.0.3/temp/pid #hbase相关pid文件存放目录
10.2 修改环境变量
1 [root@master ~]# vi /root/.bash_profile
2 PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HBASE_HOME/bin
3 export PATH
4 export JAVA_HOME=/usr/jdk1.8.0_111
5 export HADOOP_HOME=/usr/hadoop-2.7.0
6 export HADOOP_LOG_DIR=/usr/hadoop-2.7.0/logs
7 export YARN_LOG_DIR=$HADOOP_LOG_DIR
8 export ZOOKEEPER_HOME=/usr/zookeeper-3.4.9/
9 export HBASE_HOME=/usr/hbase-1.0.3
10 export HBASE_LOG_DIR=$HBASE_HOME/logs
11 [root@master ~]# source /root/.bash_profile
12 [root@master ~]# scp /root/.bash_profile slave01:/root/
13 [root@master ~]# scp /root/.bash_profile slave02:/root/
提示:三台主机都需要配置,可直接将环境变量复制给slave01和slave02。
1 [root@master ~]# vi /usr/hbase-1.0.3/conf/hbase-env.sh
2 export JAVA_HOME=/usr/jdk1.8.0_111
3 export HBASE_MANAGES_ZK=true
4 export HBASE_CLASSPATH=/usr/hadoop-2.7.0/etc/hadoop/
5 export HBASE_PID_DIR=/usr/hbase-1.0.3/temp/pid
注意:分布式运行的一个Hbase依赖一个zookeeper集群。所有的节点和客户端都必须能够访问zookeeper。默认Hbase会管理一个zookeep集群,即HBASE_MANAGES_ZK=true,这个集群会随着 Hbase 的启动而启动。也可以采用独立的 zookeeper 来管理 hbase,即HBASE_MANAGES_ZK=false。
10.4 修改hbase-site.xml
1 [root@master ~]# vi /usr/hbase-1.0.3/conf/hbase-site.xml
2 ……
3 <configuration>
4 <property>
5 <name>hbase.rootdir</name>
6 <value>hdfs://master:9000/hbase</value>
7 </property>
8 <property>
9 <name>hbase.cluster.distributed</name>
10 <value>true</value>
11 </property>
12 <property>
13 <name>hbase.zookeeper.quorum</name>
14 <value>slave01,slave02</value>
15 </property>
16 <property>
17 <name>hbase.master.maxclockskew</name>
18 <value>180000</value>
19 </property>
20 <property>
21 <name>hbase.zookeeper.property.dataDir</name>
22 <value>/usr/zookeeper-3.4.9/data</value>
23 </property>
24 <property>
25 <name>hbase.tmp.dir</name>
26 <value>/usr/hbase-1.0.3/temp</value>
27 </property>
28 <property>
29 <name>hbase.master</name>
30 <value>hdfs://master:60000</value>
31 </property>
32 <property>
33 <name>hbase.master.info.port</name>
34 <value>60010</value>
35 </property>
36 <property>
37 <name>hbase.regionserver.info.port</name>
38 <value>60030</value>
39 </property>
40 <property>
41 <name>hbase.client.scanner.caching</name>
42 <value>200</value>
43 </property>
44 <property>
45 <name>hbase.balancer.period</name>
46 <value>300000</value>
47 </property>
48 <property>
49 <name>hbase.client.write.buffer</name>
50 <value>10485760</value>
51 </property>
52 <property>
53 <name>hbase.hregion.majorcompaction</name>
54 <value>7200000</value>
55 </property>
56 <property>
57 <name>hbase.hregion.max.filesize</name>
58 <value>67108864</value>
59 </property>
60 <property>
61 <name>hbase.hregion.memstore.flush.size</name>
62 <value>1048576</value>
63 </property>
64 <property>
65 <name>hbase.server.thread.wakefrequency</name>
66 <value>30000</value>
67 </property>
68 </configuration>
69 #直接将imxhy01的相关配置传送给imxhy02即可。
70 [root@master ~]# scp -r /usr/hbase-1.0.3 root@imxhy02:/usr/
10.5 配置 regionservers
1 [root@master ~]# vi /usr/hbase-1.0.3/conf/regionservers
2 slave01
3 slave02
十一 启动hbase
1 [root@master ~]# cd /usr/hbase-1.0.3/bin/
2 [root@master bin]# ./start-hbase.sh
3 [root@slave01 ~]# cd /usr/hbase-1.0.3/bin/
4 [root@slave01 bin]# ./hbase-daemon.sh start regionserver
5 [root@slave02 ~]# cd /usr/hbase-1.0.3/bin/
6 [root@slave02 bin]# ./hbase-daemon.sh start regionserver
十二 测试
12.1 浏览器检测
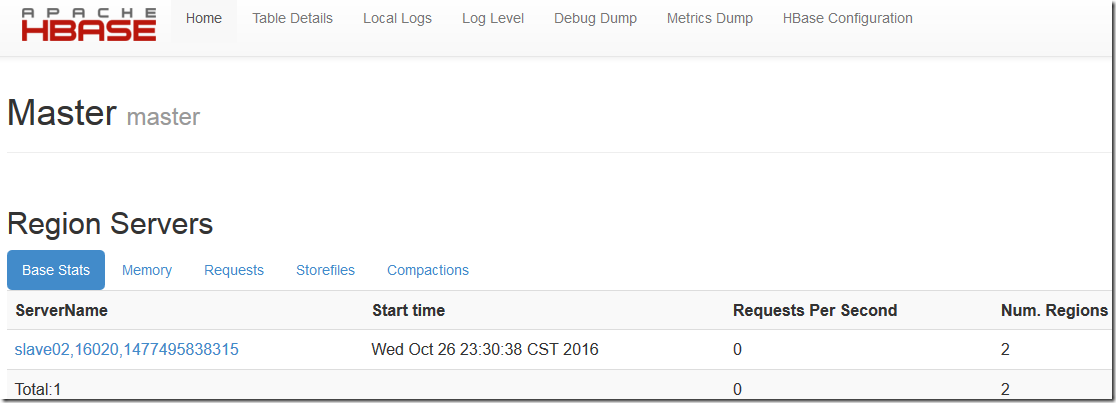
12.2 java检测
1 [root@master ~]# /usr/jdk1.8.0_111/bin/jps
2 21346 NameNode
3 23301 Jps
4 21703 ResourceManager
5 21544 SecondaryNameNode
6 22361 QuorumPeerMain
7 23087 HMaster
8 [root@slave01 ~]# jps
9 17377 HRegionServer
10 17457 Jps
11 16038 NodeManager
12 15928 DataNode
13 16488 QuorumPeerMain
14 15533 SecondaryNameNode
15 [root@slave02 ~]# jps
16 16400 QuorumPeerMain
17 15507 SecondaryNameNode
18 16811 HRegionServer
19 17164 Jps
20 16013 NodeManager
21 15903 DataNode
Hadoop及Hbase部署的更多相关文章
- 001.hadoop及hbase部署
一 环境准备 1.1 相关环境 系统:CentOS 7 #CentOS 6.x系列也可参考,转换相关命令即可. hadoop包:hadoop-2.7.0.tar.gz #下载官方地址:http://w ...
- Hadoop+Spark+Hbase部署整合篇
之前的几篇博客中记录的Hadoop.Spark和Hbase部署过程虽然看起来是没多大问题,但是之后在上面跑任务的时候出现了各种各样的配置问题.庆幸有将问题记录下来,可以整理出这篇部署整合篇. 确保集群 ...
- Zookeeper + Hadoop + Hbase部署备忘
网上类似的文章很多,本文只是记录下来备忘.本文分四大步骤: 准备工作.安装zookeeper.安装hadoop.安装hbase,下面分别详细介绍: 一 准备工作 1. 下载 zookeeper.had ...
- hadoop和hbase高可用模式部署
记录apache版本的hadoop和hbase的安装,并启用高可用模式. 1. 主机环境 我这里使用的操作系统是centos 6.5,安装在vmware上,共三台. 主机名 IP 操作系统 用户名 安 ...
- 基于Hadoop技术实现的离线电商分析平台(Flume、Hadoop、Hbase、SpringMVC、highcharts)
离线数据分析平台是一种利用hadoop集群开发工具的一种方式,主要作用是帮助公司对网站的应用有一个比较好的了解.尤其是在电商.旅游.银行.证券.游戏等领域有非常广泛,因为这些领域对数据和用户的特性把握 ...
- Hadoop.之.入门部署
一.课程目标 ->大数据是什么?大数据能做什么? ->什么是Hadoop?Hadoop的设计思想? ->Hadoop如何解决大数据的问题?(什么是hdfs与yarn.MapReduc ...
- 大数据【七】HBase部署
接着前面的Zookeeper部署之后,现在可以学习HBase了. HBase是基于Hadoop的开源分布式数据库,它以Google的BigTable为原型,设计并实现了具有高可靠性.高性能.列存储.可 ...
- Hadoop生态圈-Sqoop部署以及基本使用方法
Hadoop生态圈-Sqoop部署以及基本使用方法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与 ...
- 第十二章 Ganglia监控Hadoop及Hbase集群性能(安装配置)
1 Ganglia简介 Ganglia 是 UC Berkeley 发起的一个开源监视项目,设计用于测量数以千计的节点.每台计算机都运行一个收集和发送度量数据(如处理器速度.内存使用量等)的名为 gm ...
随机推荐
- Skywalking-05:在Skywalking RocketBot上添加监控图表
在 Skywalking RocketBot 上添加监控图表 效果图 该图的一些配置信息如下: 标题为: JVM Thread State Count (Java Service) 指标为: read ...
- odoo源生打印【web report】
https://www.odoo.com/documentation/12.0/reference/reports.html 具体的看官方文档 一.纸张格式设置: <record id= ...
- Linux chgrp命令的使用
Linux chgrp(change group)命令用于变更文件或目录的所属群组. 语法 chgrp [-cfhRv][--help][--version][所属群组][文件或目录...] 或 ch ...
- Java大整形BigInteger的用法
基本类型int有32位,范围是:[-2147483648, 2147483647](正负21亿多) 基本类型long有64位,范围是:[-9223372036854775808, 9223372036 ...
- joomla 3.7.0 (CVE-2017-8917) SQL注入漏洞
影响版本: 3.7.0 poc http://192.168.49.2:8080/index.php?option=com_fields&view=fields&layout=moda ...
- Sunset靶机
仅供个人娱乐 靶机信息 https://www.vulnhub.com/entry/sunset-sunrise,406/ 一.主机探测 二.信息收集 nmap -sS -sV -T5 -A -p- ...
- 小技巧 | Get 到一个 Web 自动化方案,绝了!
1. 前言 大家好,我是安果! 无论是 Chrome,还是 Firefox 浏览器,它们的强大性在很大程度上都是依赖于海量的插件,让我们能高效办公 那我们是否可以编写一个插件,让浏览器自动化完成一些日 ...
- 从net到java:java快速入门
学习java那是不可能的,到为什么不学习一下呢.仅为总结.希望自己在不久的将来能书写优美的java程序.加油!奥利给 1.注释 注释的重要性不言而喻,我们不管写什么代码注释必不可少,那么java的注释 ...
- Linux-shell编程经验记录
Linux-shell编程经验总结 1.接收用户输入 #读取用户输入并且将输入保存到input变量中 read -p "请输入:" input #也可以先输出信息再进行读取,这里的 ...
- 字节跳动Android实习面试难吗,应该如何应对?
字节跳动的面试难不难其实很难去非常准确的定义,但是能肯定的一点是,字节跳动的面试题都很有水平,真正考察了该岗位在以后工作中需要的能力. 大学学的Java后面又自学Android方向,跟着老师在实验室做 ...